mteb/BRIGHT
收藏Hugging Face2026-04-02 更新2026-03-29 收录
下载链接:
https://hf-mirror.com/datasets/mteb/BRIGHT
下载链接
链接失效反馈官方服务:
资源简介:
---
language:
- en
license: cc-by-4.0
size_categories:
- 1K<n<10K
task_categories:
- text-retrieval
dataset_info:
- config_name: Gemini-1.0_reason
features:
- name: query
dtype: string
- name: reasoning
dtype: string
- name: id
dtype: string
- name: excluded_ids
sequence: string
- name: gold_ids_long
sequence: string
- name: gold_ids
sequence: string
- name: gold_answer
dtype: string
splits:
- name: biology
num_bytes: 571840
num_examples: 103
- name: earth_science
num_bytes: 569680
num_examples: 116
- name: economics
num_bytes: 617171
num_examples: 103
- name: psychology
num_bytes: 557169
num_examples: 101
- name: robotics
num_bytes: 467620
num_examples: 101
- name: stackoverflow
num_bytes: 652597
num_examples: 117
- name: sustainable_living
num_bytes: 626085
num_examples: 108
- name: leetcode
num_bytes: 1382908
num_examples: 142
- name: pony
num_bytes: 327318
num_examples: 112
- name: aops
num_bytes: 14182450
num_examples: 111
- name: theoremqa_questions
num_bytes: 13144059
num_examples: 194
- name: theoremqa_theorems
num_bytes: 393390
num_examples: 76
download_size: 5946613
dataset_size: 33492287
- config_name: claude-3-opus_reason
features:
- name: query
dtype: string
- name: reasoning
dtype: string
- name: id
dtype: string
- name: excluded_ids
sequence: string
- name: gold_ids_long
sequence: string
- name: gold_ids
sequence: string
- name: gold_answer
dtype: string
splits:
- name: biology
num_bytes: 557025
num_examples: 103
- name: earth_science
num_bytes: 558266
num_examples: 116
- name: economics
num_bytes: 574237
num_examples: 103
- name: psychology
num_bytes: 516517
num_examples: 101
- name: robotics
num_bytes: 437209
num_examples: 101
- name: stackoverflow
num_bytes: 622316
num_examples: 117
- name: sustainable_living
num_bytes: 591735
num_examples: 108
- name: leetcode
num_bytes: 1407501
num_examples: 142
- name: pony
num_bytes: 361169
num_examples: 112
- name: aops
num_bytes: 14149870
num_examples: 111
- name: theoremqa_questions
num_bytes: 13121703
num_examples: 194
- name: theoremqa_theorems
num_bytes: 382228
num_examples: 76
download_size: 5777474
dataset_size: 33279776
- config_name: documents
features:
- name: id
dtype: string
- name: content
dtype: string
splits:
- name: biology
num_bytes: 21983744
num_examples: 57359
- name: earth_science
num_bytes: 46952371
num_examples: 121249
- name: economics
num_bytes: 22771374
num_examples: 50220
- name: psychology
num_bytes: 23167414
num_examples: 52835
- name: robotics
num_bytes: 20718385
num_examples: 61961
- name: stackoverflow
num_bytes: 189733583
num_examples: 107081
- name: sustainable_living
num_bytes: 24373723
num_examples: 60792
- name: pony
num_bytes: 2365157
num_examples: 7894
- name: leetcode
num_bytes: 456581333
num_examples: 413932
- name: aops
num_bytes: 146564475
num_examples: 188002
- name: theoremqa_theorems
num_bytes: 21124422
num_examples: 23839
- name: theoremqa_questions
num_bytes: 146564475
num_examples: 188002
download_size: 465489179
dataset_size: 1122900456
- config_name: examples
features:
- name: query
dtype: string
- name: reasoning
dtype: string
- name: id
dtype: string
- name: excluded_ids
sequence: string
- name: gold_ids_long
sequence: string
- name: gold_ids
sequence: string
- name: gold_answer
dtype: string
splits:
- name: biology
num_bytes: 326427
num_examples: 103
- name: earth_science
num_bytes: 280741
num_examples: 116
- name: economics
num_bytes: 343172
num_examples: 103
- name: psychology
num_bytes: 286062
num_examples: 101
- name: robotics
num_bytes: 366862
num_examples: 101
- name: stackoverflow
num_bytes: 470365
num_examples: 117
- name: sustainable_living
num_bytes: 336562
num_examples: 108
- name: pony
num_bytes: 135009
num_examples: 112
- name: leetcode
num_bytes: 1212640
num_examples: 142
- name: aops
num_bytes: 13981802
num_examples: 111
- name: theoremqa_theorems
num_bytes: 257842
num_examples: 76
- name: theoremqa_questions
num_bytes: 12810785
num_examples: 194
download_size: 4590189
dataset_size: 30808269
- config_name: gpt4_reason
features:
- name: query
dtype: string
- name: reasoning
dtype: string
- name: id
dtype: string
- name: excluded_ids
sequence: string
- name: gold_ids_long
sequence: string
- name: gold_ids
sequence: string
- name: gold_answer
dtype: string
splits:
- name: biology
num_bytes: 613511
num_examples: 103
- name: earth_science
num_bytes: 618266
num_examples: 116
- name: economics
num_bytes: 642234
num_examples: 103
- name: psychology
num_bytes: 571504
num_examples: 101
- name: robotics
num_bytes: 519720
num_examples: 101
- name: stackoverflow
num_bytes: 704186
num_examples: 117
- name: sustainable_living
num_bytes: 657382
num_examples: 108
- name: leetcode
num_bytes: 1461063
num_examples: 142
- name: pony
num_bytes: 423199
num_examples: 112
- name: aops
num_bytes: 14332394
num_examples: 111
- name: theoremqa_questions
num_bytes: 13262646
num_examples: 194
- name: theoremqa_theorems
num_bytes: 442272
num_examples: 76
download_size: 6421256
dataset_size: 34248377
- config_name: grit_reason
features:
- name: query
dtype: string
- name: reasoning
dtype: string
- name: id
dtype: string
- name: excluded_ids
sequence: string
- name: gold_ids_long
sequence: string
- name: gold_ids
sequence: string
- name: gold_answer
dtype: string
splits:
- name: biology
num_bytes: 478151
num_examples: 103
- name: earth_science
num_bytes: 443792
num_examples: 116
- name: economics
num_bytes: 493163
num_examples: 103
- name: psychology
num_bytes: 407907
num_examples: 101
- name: robotics
num_bytes: 340895
num_examples: 101
- name: stackoverflow
num_bytes: 540771
num_examples: 117
- name: sustainable_living
num_bytes: 475118
num_examples: 108
- name: leetcode
num_bytes: 1305306
num_examples: 142
- name: pony
num_bytes: 258002
num_examples: 112
- name: aops
num_bytes: 14170933
num_examples: 111
- name: theoremqa_questions
num_bytes: 13040517
num_examples: 194
- name: theoremqa_theorems
num_bytes: 360282
num_examples: 76
download_size: 5202414
dataset_size: 32314837
- config_name: llama3-70b_reason
features:
- name: query
dtype: string
- name: reasoning
dtype: string
- name: id
dtype: string
- name: excluded_ids
sequence: string
- name: gold_ids_long
sequence: string
- name: gold_ids
sequence: string
- name: gold_answer
dtype: string
splits:
- name: biology
num_bytes: 631132
num_examples: 103
- name: earth_science
num_bytes: 622087
num_examples: 116
- name: economics
num_bytes: 631657
num_examples: 103
- name: psychology
num_bytes: 563987
num_examples: 101
- name: robotics
num_bytes: 449342
num_examples: 101
- name: stackoverflow
num_bytes: 641853
num_examples: 117
- name: sustainable_living
num_bytes: 654690
num_examples: 108
- name: leetcode
num_bytes: 1376032
num_examples: 142
- name: pony
num_bytes: 315870
num_examples: 112
- name: aops
num_bytes: 14183895
num_examples: 111
- name: theoremqa_questions
num_bytes: 13157545
num_examples: 194
- name: theoremqa_theorems
num_bytes: 405388
num_examples: 76
download_size: 5877403
dataset_size: 33633478
- config_name: long_documents
features:
- name: id
dtype: string
- name: content
dtype: string
splits:
- name: biology
num_bytes: 19454314
num_examples: 524
- name: earth_science
num_bytes: 41843262
num_examples: 601
- name: economics
num_bytes: 20095594
num_examples: 516
- name: psychology
num_bytes: 20541239
num_examples: 512
- name: robotics
num_bytes: 18220587
num_examples: 508
- name: stackoverflow
num_bytes: 184616744
num_examples: 1858
- name: sustainable_living
num_bytes: 21200303
num_examples: 554
- name: pony
num_bytes: 2098474
num_examples: 577
download_size: 104578765
dataset_size: 328070517
configs:
- config_name: Gemini-1.0_reason
data_files:
- split: biology
path: Gemini-1.0_reason/biology-*
- split: earth_science
path: Gemini-1.0_reason/earth_science-*
- split: economics
path: Gemini-1.0_reason/economics-*
- split: psychology
path: Gemini-1.0_reason/psychology-*
- split: robotics
path: Gemini-1.0_reason/robotics-*
- split: stackoverflow
path: Gemini-1.0_reason/stackoverflow-*
- split: sustainable_living
path: Gemini-1.0_reason/sustainable_living-*
- split: leetcode
path: Gemini-1.0_reason/leetcode-*
- split: pony
path: Gemini-1.0_reason/pony-*
- split: aops
path: Gemini-1.0_reason/aops-*
- split: theoremqa_questions
path: Gemini-1.0_reason/theoremqa_questions-*
- split: theoremqa_theorems
path: Gemini-1.0_reason/theoremqa_theorems-*
- config_name: claude-3-opus_reason
data_files:
- split: biology
path: claude-3-opus_reason/biology-*
- split: earth_science
path: claude-3-opus_reason/earth_science-*
- split: economics
path: claude-3-opus_reason/economics-*
- split: psychology
path: claude-3-opus_reason/psychology-*
- split: robotics
path: claude-3-opus_reason/robotics-*
- split: stackoverflow
path: claude-3-opus_reason/stackoverflow-*
- split: sustainable_living
path: claude-3-opus_reason/sustainable_living-*
- split: leetcode
path: claude-3-opus_reason/leetcode-*
- split: pony
path: claude-3-opus_reason/pony-*
- split: aops
path: claude-3-opus_reason/aops-*
- split: theoremqa_questions
path: claude-3-opus_reason/theoremqa_questions-*
- split: theoremqa_theorems
path: claude-3-opus_reason/theoremqa_theorems-*
- config_name: documents
data_files:
- split: biology
path: documents/biology-*
- split: earth_science
path: documents/earth_science-*
- split: economics
path: documents/economics-*
- split: psychology
path: documents/psychology-*
- split: robotics
path: documents/robotics-*
- split: stackoverflow
path: documents/stackoverflow-*
- split: sustainable_living
path: documents/sustainable_living-*
- split: pony
path: documents/pony-*
- split: leetcode
path: documents/leetcode-*
- split: aops
path: documents/aops-*
- split: theoremqa_theorems
path: documents/theoremqa_theorems-*
- split: theoremqa_questions
path: documents/theoremqa_questions-*
- config_name: examples
data_files:
- split: biology
path: examples/biology-*
- split: earth_science
path: examples/earth_science-*
- split: economics
path: examples/economics-*
- split: psychology
path: examples/psychology-*
- split: robotics
path: examples/robotics-*
- split: stackoverflow
path: examples/stackoverflow-*
- split: sustainable_living
path: examples/sustainable_living-*
- split: pony
path: examples/pony-*
- split: leetcode
path: examples/leetcode-*
- split: aops
path: examples/aops-*
- split: theoremqa_theorems
path: examples/theoremqa_theorems-*
- split: theoremqa_questions
path: examples/theoremqa_questions-*
- config_name: gpt4_reason
data_files:
- split: biology
path: gpt4_reason/biology-*
- split: earth_science
path: gpt4_reason/earth_science-*
- split: economics
path: gpt4_reason/economics-*
- split: psychology
path: gpt4_reason/psychology-*
- split: robotics
path: gpt4_reason/robotics-*
- split: stackoverflow
path: gpt4_reason/stackoverflow-*
- split: sustainable_living
path: gpt4_reason/sustainable_living-*
- split: leetcode
path: gpt4_reason/leetcode-*
- split: pony
path: gpt4_reason/pony-*
- split: aops
path: gpt4_reason/aops-*
- split: theoremqa_questions
path: gpt4_reason/theoremqa_questions-*
- split: theoremqa_theorems
path: gpt4_reason/theoremqa_theorems-*
- config_name: grit_reason
data_files:
- split: biology
path: grit_reason/biology-*
- split: earth_science
path: grit_reason/earth_science-*
- split: economics
path: grit_reason/economics-*
- split: psychology
path: grit_reason/psychology-*
- split: robotics
path: grit_reason/robotics-*
- split: stackoverflow
path: grit_reason/stackoverflow-*
- split: sustainable_living
path: grit_reason/sustainable_living-*
- split: leetcode
path: grit_reason/leetcode-*
- split: pony
path: grit_reason/pony-*
- split: aops
path: grit_reason/aops-*
- split: theoremqa_questions
path: grit_reason/theoremqa_questions-*
- split: theoremqa_theorems
path: grit_reason/theoremqa_theorems-*
- config_name: llama3-70b_reason
data_files:
- split: biology
path: llama3-70b_reason/biology-*
- split: earth_science
path: llama3-70b_reason/earth_science-*
- split: economics
path: llama3-70b_reason/economics-*
- split: psychology
path: llama3-70b_reason/psychology-*
- split: robotics
path: llama3-70b_reason/robotics-*
- split: stackoverflow
path: llama3-70b_reason/stackoverflow-*
- split: sustainable_living
path: llama3-70b_reason/sustainable_living-*
- split: leetcode
path: llama3-70b_reason/leetcode-*
- split: pony
path: llama3-70b_reason/pony-*
- split: aops
path: llama3-70b_reason/aops-*
- split: theoremqa_questions
path: llama3-70b_reason/theoremqa_questions-*
- split: theoremqa_theorems
path: llama3-70b_reason/theoremqa_theorems-*
- config_name: long_documents
data_files:
- split: biology
path: long_documents/biology-*
- split: earth_science
path: long_documents/earth_science-*
- split: economics
path: long_documents/economics-*
- split: psychology
path: long_documents/psychology-*
- split: robotics
path: long_documents/robotics-*
- split: stackoverflow
path: long_documents/stackoverflow-*
- split: sustainable_living
path: long_documents/sustainable_living-*
- split: pony
path: long_documents/pony-*
tags:
- text-retrieval
- code
- biology
- earth_science
- economics
- psychology
- robotics
- math
---
# BRIGHT benchmark
BRIGHT is the first text retrieval benchmark that requires intensive reasoning to retrieve relevant documents.
The queries are collected from diverse domains (StackExchange, LeetCode, and math competitions), all sourced from realistic human data.
Experiments show that existing retrieval models perform poorly on BRIGHT, where the highest score is only 22.1 measured by nDCG@10.
BRIGHT provides a good testbed for future retrieval research in more realistic and challenging settings. More details are in the [paper](https://brightbenchmark.github.io/).
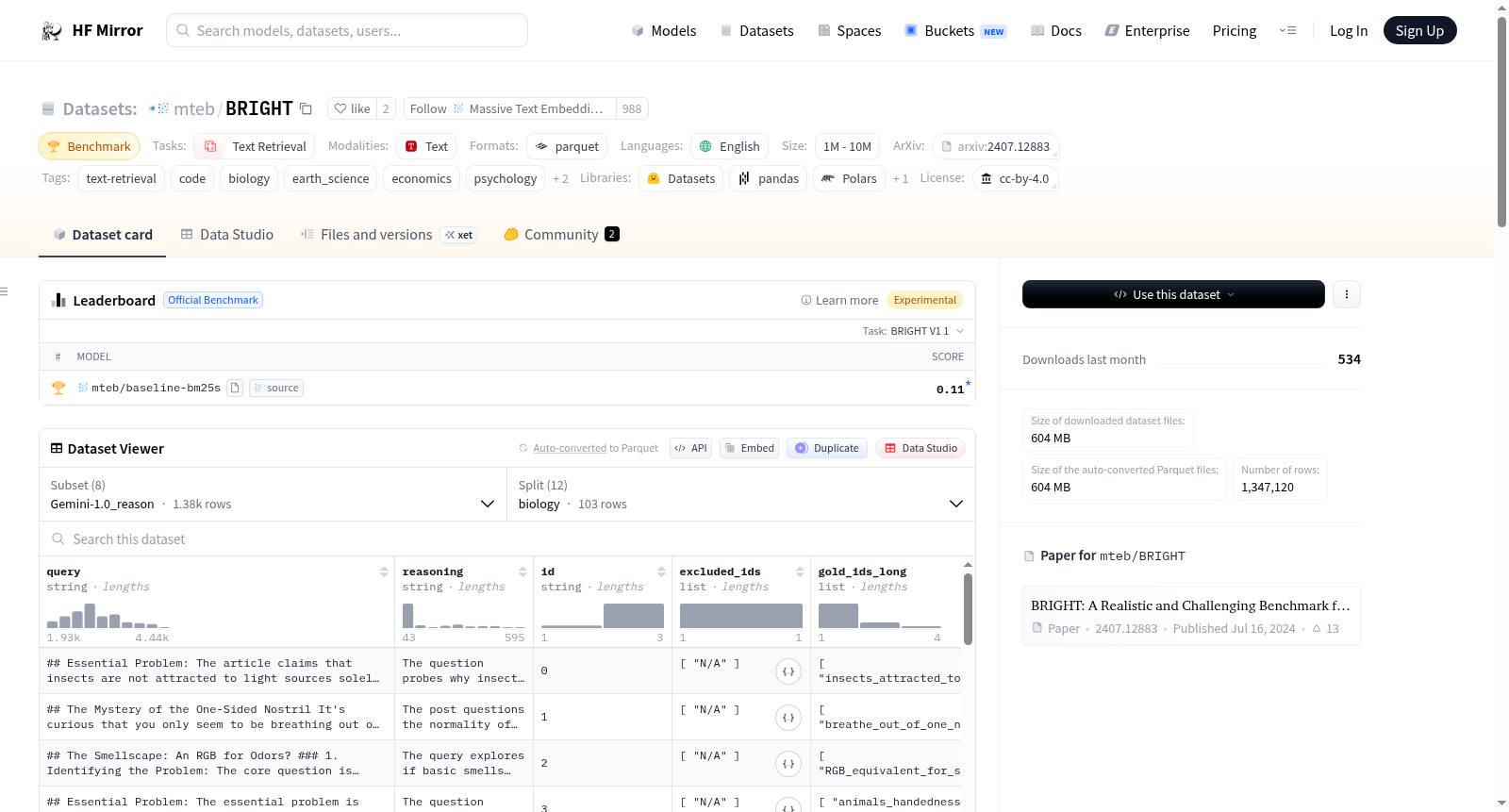
## Dataset Structure
We unify all the datasets with consistent formats. They are organized into three subsets, examples, documents, and long_documents:
* `examples`:
* `query`: the query for retrieval
* `reasoning`: the gold reasoning steps annotated by humans (they help people understand the relevance between queries and documents, but are not used in any experiment in the paper)
* `id`: the index of the instance
* `excluded_ids`: a list of the ids (string) to exclude during evaluation (only for `theoremqa`/`aops`/`leetcode`)
* `gold_ids_long`: a list of the ids (string) of the ground truth documents, corresponding to the ids of the `long_documents` subset
* `gold_ids`: a list of the ids (string) of the ground truth documents, corresponding to the indices of the `documents` subset
* `documents`:
* `id`: the index of the document
* `content`: document content (short version split from the complete web page, blogs, etc., or a problem and solution pair)
* `long_documents` (not applicable to `theoremqa`/`aops`/`leetcode`):
* `id`: the index of the document
* `content`: document content (long version corresponding to the complete web page, blogs, etc.)
## Dataset Statistics
<img src="statistics.png" width="80%" alt="BRIGHT statistics">
## Data Loading
Each dataset can be easily loaded. For example, to load biology examples:
```
from datasets import load_dataset
data = load_dataset('xlangai/BRIGHT', 'examples')['biology']
```
## Citation
If you find our work helpful, please cite us:
```citation
@misc{BRIGHT,
title={BRIGHT: A Realistic and Challenging Benchmark for Reasoning-Intensive Retrieval},
author={Su, Hongjin and Yen, Howard and Xia, Mengzhou and Shi, Weijia and Muennighoff, Niklas and Wang, Han-yu and Liu, Haisu and Shi, Quan and Siegel, Zachary S and Tang, Michael and Sun, Ruoxi and Yoon, Jinsung and Arik, Sercan O and Chen, Danqi and Yu, Tao},
url={https://arxiv.org/abs/2407.12883},
year={2024},
}
```
提供机构:
mteb
搜集汇总
数据集介绍
构建方式
在信息检索领域,面对日益复杂的查询需求,BRIGHT基准的构建旨在模拟真实场景中需要深度推理的检索任务。该数据集通过整合来自StackExchange、LeetCode以及数学竞赛等多个领域的真实人类查询数据,精心构建了查询与文档之间的关联。其核心结构分为三个子集:examples子集包含查询、人工标注的推理步骤及标准答案标识;documents子集提供经过分割的短版本文档内容;long_documents子集则保留了完整的原始网页或博客长文本,共同形成了一个层次分明的检索评估体系。
特点
BRIGHT基准的显著特征在于其强调推理密集型检索,突破了传统检索任务对表面语义匹配的依赖。数据集覆盖生物学、地球科学、经济学、心理学、机器人学等十二个专业领域,并包含编程与数学竞赛等复杂场景,体现了高度的多样性与专业性。每个查询均配有详尽的推理步骤标注,揭示了查询与相关文档之间的深层逻辑联系,为评估模型在复杂语境下的理解能力提供了严谨的测试框架。
使用方法
为便于研究者使用,BRIGHT数据集通过Hugging Face的datasets库提供了便捷的加载接口。用户可根据需要加载特定的配置与领域子集,例如通过指定配置名'examples'和分割名'biology'来获取生物学领域的查询实例。数据集中明确的标识字段,如gold_ids和excluded_ids,为设计检索实验与评估指标(如nDCG@10)提供了清晰的指引,使得该基准能够直接应用于训练与测试前沿的检索模型。
背景与挑战
背景概述
在信息检索领域,传统模型通常依赖于关键词匹配或浅层语义关联,难以应对需要深度逻辑推理的复杂查询。为应对这一挑战,研究团队于2024年推出了BRIGHT基准数据集,该数据集由多领域专家共同构建,旨在评估模型在需要密集推理的文本检索任务中的性能。BRIGHT的核心研究问题聚焦于如何提升检索系统在真实且复杂的跨学科场景下的理解与推理能力,其涵盖生物学、地球科学、经济学、心理学、机器人学以及数学竞赛等多个专业领域,为推进检索技术向更高层次的认知理解迈进提供了关键的评估工具。
当前挑战
BRIGHT数据集所针对的领域挑战在于,现有检索模型在面对需要多步逻辑推理和深层领域知识的查询时表现显著不足,例如在解决数学证明或专业代码问题时,模型难以准确关联查询与相关文档。在构建过程中,挑战主要源于如何从StackExchange、LeetCode等真实人类数据源中收集和标注高质量、多样化的查询与文档对,同时确保推理步骤的准确性和领域覆盖的全面性,这需要精细的领域知识整合与大规模数据清洗工作。
常用场景
经典使用场景
在信息检索领域,BRIGHT数据集为评估检索模型在复杂推理任务上的性能提供了经典场景。该数据集包含来自生物学、地球科学、经济学、心理学、机器人学以及StackOverflow、LeetCode和数学竞赛等多个专业领域的查询与文档,每个查询均需经过深度推理才能确定相关文档。研究人员通常利用该数据集测试检索模型在处理需要多步逻辑分析和领域知识整合的查询时的表现,特别是在面对长文档和跨领域内容时的检索精度与鲁棒性。
衍生相关工作
围绕BRIGHT数据集,已衍生出多项关注推理增强检索的经典研究工作。这些工作主要探索如何将大型语言模型的推理能力与检索系统相结合,例如通过生成式检索或检索增强生成技术来改善复杂查询下的文档相关性判断。同时,一些研究利用BRIGHT的多领域特性,开发了跨领域自适应检索方法,以提升模型在专业场景中的泛化能力。这些工作共同推动了检索技术向更高层次的认知智能迈进。
数据集最近研究
最新研究方向
在信息检索领域,随着大语言模型在复杂推理任务中的广泛应用,传统检索系统面临理解深层语义关联的严峻挑战。BRIGHT基准作为首个专注于推理密集型检索的数据集,其跨学科的真实查询与标注的推理步骤,为评估模型在生物学、经济学、心理学及编程等专业场景下的逻辑分析能力提供了全新范本。当前研究热点集中于利用多模态思维链技术增强检索模型的推理泛化性,探索检索与生成模型的协同机制,以应对长文档理解和领域知识融合的难题。该数据集的推出,不仅推动了检索系统向认知智能方向的演进,也为构建更鲁棒、可解释的下一代信息检索架构奠定了实证基础。
以上内容由遇见数据集搜集并总结生成


