jackf857/qwen3-8b-base-new-dpo-hh-helpful-4xh200-batch-64-q_t-0.45-s_star-0.4-eta-0.5-margin-log
收藏Hugging Face2026-05-01 更新2026-05-03 收录
下载链接:
https://hf-mirror.com/datasets/jackf857/qwen3-8b-base-new-dpo-hh-helpful-4xh200-batch-64-q_t-0.45-s_star-0.4-eta-0.5-margin-log
下载链接
链接失效反馈官方服务:
资源简介:
该数据集是从一个名为jackf857/qwen3-8b-base-new-dpo-hh-helpful-4xh200-batch-64-q_t-0.45-s_star-0.4-eta-0.5的新DPO训练运行中导出的每一步边际摘要统计。数据集包含了训练过程中的各种统计指标,如epoch、step、batch_size、mean、std等。数据集的来源是基于Anthropic/hh-rlhf的混合数据,训练参数包括beta、f_divergence_type、f_alpha_divergence_coef等。
Per-step margin summary statistics exported from a New-DPO training run. The dataset includes various statistical metrics during the training process, such as epoch, step, batch_size, mean, std, etc. The source of the dataset is based on a mix of Anthropic/hh-rlhf data, and the training parameters include beta, f_divergence_type, f_alpha_divergence_coef, etc.
提供机构:
jackf857
搜集汇总
数据集介绍
构建方式
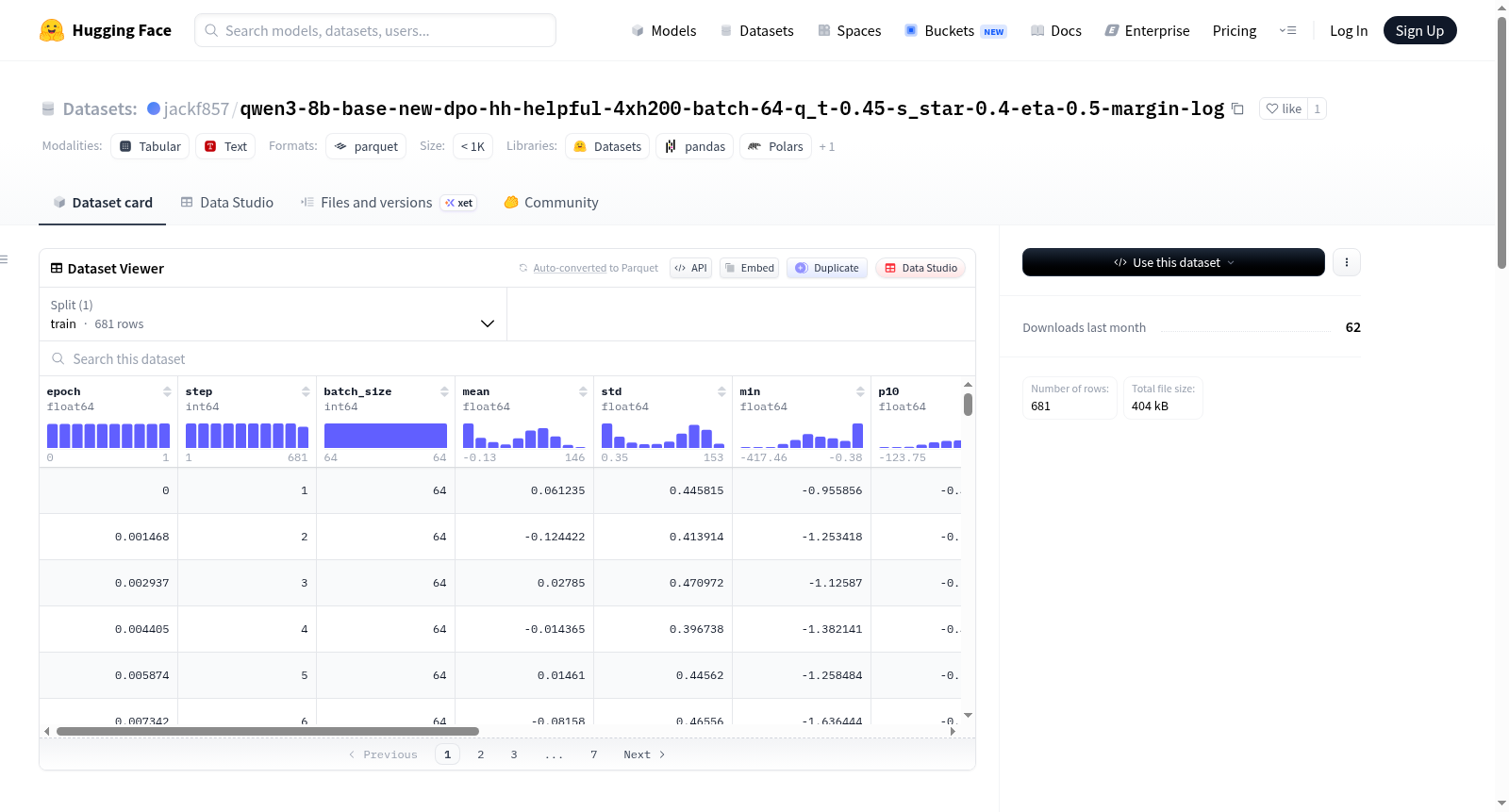
该数据集源自基于Qwen3-8B模型进行的New-DPO训练过程,具体而言,是对超参数组合为q_t=0.45、s_star=0.4、eta=0.5的强化学习实验的中间状态进行记录与导出。训练采用混合数据集Anthropic/hh-rlhf,通过边际损失函数(margin)的逐步骤统计信息来监测模型偏好对齐的动态。数据收集过程中,系统以每1步的间隔保存完整边际数组,确保捕获训练过程中每个关键节点的精细化梯度信号。最终汇总形成包含681条样本的训练集,每条记录均包含epoch、step、batch_size及多种边际统计量,为后续分析提供了丰富的结构化工件。
特点
本数据集的核心特色在于其聚焦于强化学习训练中边际(margin)指标的细腻统计表征,而非传统的奖励或损失标量。数据包含从均值、标准差到分位数(p10、p90)的多维度分布信息,能够全面揭示模型在每一步中对偏好对的区分程度。特别地,‘sample’字段保存了有效批次内每个样本的边际值,‘npy’字段则提供了完整边际数组的存储路径,便于研究者进行深层可视化与特征分析。这种设计使得数据集超越了单一指标监测的局限,成为理解New-DPO算法动态行为的重要诊断工具。
使用方法
在使用本数据集时,研究者可直接加载训练集(train split)中包含的统计字段,用于计算训练过程中的边际变化趋势或绘制分布演变图。对于需要全量边际数组的应用场景,可通过‘npy’字段对应路径加载完整的numpy数组,进行细粒度的样本级别分析。该数据集与HuggingFace Datasets库原生兼容,支持直接使用load_dataset方法读取。若需复现或扩展训练,可通过README中的模型repo id和W&B项目链接获取超参数配置与基准模型,从而在类似任务中进行对照实验或超参数调优研究。
背景与挑战
背景概述
该数据集由研究者jackf857基于Qwen3-8B基座模型在Anthropic/hh-rlhf数据集上通过New-DPO算法微调后导出,创建于2025年。核心研究问题聚焦于探索偏好对齐算法中边际分布(margin)的动态特性,及其对模型优化策略的指导意义。通过记录每步训练过程中边际的均值、标准差、分位数等统计信息,该数据集为深入理解DPO变体算法(如New-DPO)的收敛行为与超参数敏感性提供了结构化分析基础,对强化学习与人类反馈领域的精细化调参研究具有重要参考价值。
当前挑战
所解决的领域问题在于,传统偏好对齐方法通常仅关注最终性能指标,缺乏对训练过程中边际演化规律的量化分析,难以揭示模型偏好偏移的动态本质。构建过程中面临的核心挑战包括:如何在固定超参数组合(如q_t=0.45、s_star=0.4、eta=0.5)下稳定记录高维边际张量,并确保统计摘要的时效性与可复现性;同时,来自hh-rlhf数据集的二元偏好标签与New-DPO目标函数中f-散度约束的耦合可能引入梯度噪声,需通过大batch size(64)与日志采样策略降低异常值干扰,但数据集仅包含681条记录,样本稀缺性限制了泛化结论的统计显著性。
常用场景
经典使用场景
在基于人类反馈的强化学习(RLHF)范式下,该数据集作为New-DPO训练过程中的逐步边际统计量记录,为研究者提供了理解奖励模型偏好对齐动态的微观视角。其经典的用法在于分析训练过程中正负样本边际值(margin)的演变规律,通过跟踪均值、标准差、分位数等统计指标,直观揭示模型在偏好优化阶段的收敛行为与稳定性。
实际应用
在实际应用中,该数据集可服务于大语言模型偏好对齐的超参数搜索与训练监控,通过分析边际统计量的变化趋势来判定是否出现欠拟合或过优化。它也可以作为日志归档工具,使团队能够追溯训练过程,快速定位导致模型生成质量波动的具体训练阶段,从而指导进一步的微调策略调整。
衍生相关工作
该数据集衍生了多个方向的研究工作。其一在于边际分布的可视化与聚类分析,衍生出训练状态诊断工具;其二推动了自适应边际阈值方法的发展,研究者利用其中记录的边际统计数据动态调整训练中的β、η等关键参数;其三催生了基于步进边际图的模型鲁棒性评估基准,帮助社区更细致地比对新版DPO与传统DPO的收敛路径差异。
以上内容由遇见数据集搜集并总结生成


