sarasarahuss/ALIF_Urdu_Corpus_AUC
收藏Hugging Face2026-04-30 更新2026-05-03 收录
下载链接:
https://hf-mirror.com/datasets/sarasarahuss/ALIF_Urdu_Corpus_AUC
下载链接
链接失效反馈官方服务:
资源简介:
ALIF_Urdu_Corpus数据集是Orature AI的ALIF项目的一部分,专为乌尔都语语言模型的预训练而设计。该数据集是完整33GB数据集的预览版,包含5000个文本条目,总大小约为13.7MB。数据来源多样,包括Common Crawl Dumps、翻译数据、新闻网站、现有数据集、书籍和博客等。数据集经过严格的预处理,包括清理、编码规范化、语言过滤、去重和格式化。主要用途包括预训练语言模型、指令微调、NLP研究和基准测试。
The ALIF_Urdu_Corpus dataset is part of the ALIF project by Orature AI, curated for pretraining Urdu language models. It serves as a preview to the entire 33GB dataset, containing 5000 text entries with a total size of about 13.7MB. The data was collected from diverse sources including Common Crawl Dumps, translated data, news websites, existing datasets, books, and blogs. The dataset underwent rigorous preprocessing steps such as cleaning, encoding normalization, language filtering, deduplication, and formatting. Its primary intended uses include pretraining language models, instruction fine-tuning, NLP research, and benchmarking.
提供机构:
sarasarahuss
搜集汇总
数据集介绍
构建方式
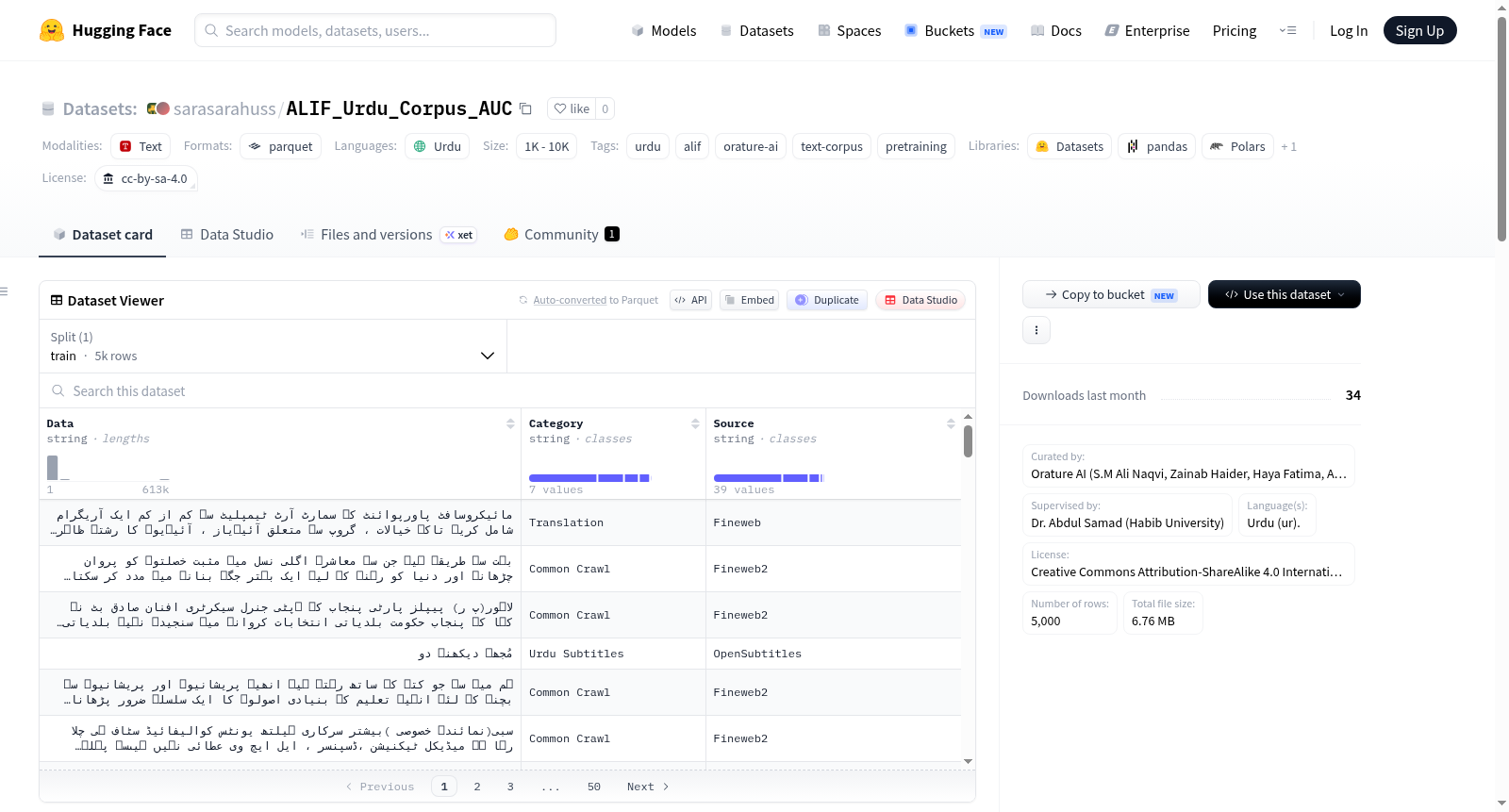
ALIF_Urdu_Corpus(AUC)是由Orature AI团队精心构建的乌尔都语预训练语料库预览版,作为庞大的33GB全量数据集的缩影。其构建过程贯穿极为严谨的流水线:数据来源广泛多样,囊括11.3GB和8.1GB的Common Crawl过滤文本、5.5GB经Google Translate API从FineWeb英语教育内容翻译的语料、3.3GB乌尔都语新闻网站爬取数据、2.9GB现有公开乌尔都语语料库(如UrduHack)、1.3GB经Google Vision OCR处理及后清洗的扫描书籍文本,以及0.6GB的博客内容。预处理阶段,依次执行去除非语言噪声(HTML标签、链接、邮箱等)、编码归一化至一致UTF-8、基于语言检测工具过滤非乌尔都语内容,再通过MinHash局部敏感哈希(LSH)进行严格的去重——同时移除精确重复与近似重复文档,最终以结构化CSV格式组织数据,训练时借助End-of-Text(EOT)标记分隔文档。
特点
该数据集的核心特点在于其多样性、规模与高质量的有机融合。尽管当前预览版仅含5000条样本(约13.7MB),但已浓缩了全量数据的结构化精华。每条记录包含三个字段:Data字段存储经过严格清洗的真实乌尔都语文本,Category字段标识文本类型(如CommonCrawl、Fineweb等所代表的数据来源范畴),Source字段则精确标注文本的原始出处。这一设计使得用户既可灵活筛选特定来源的子集,也能追溯每段文本的生成路径。特别是OCR书籍文本的引入,大幅提升了语料对文学性、学术性内容的覆盖度,而翻译数据则巧妙弥合了乌尔都语高质量教育语料的稀缺。历经多层去重后,数据冗余度极低,为语言模型预训练提供了高度纯净且类别均衡的语料基底。
使用方法
ALIF_Urdu_Corpus的设计初衷聚焦于乌尔都语大规模生成式语言模型的预训练,尤其在基础语义学习与领域适应性上具有天然优势。用户可直接借助Hugging Face的`datasets`库加载该预览版:使用`load_dataset("OratureAI/ALIF_Urdu_Corpus")`命令,即可获取包含5000条训练样本的默认配置,每条样本均以字典形式呈现Data、Category与Source字段。在模型开发流程中,研究者可将其接入标准的预训练管线,直接输入分词器与模型,或利用Category字段实现领域自适应训练——例如选取特定类别数据以增强模型的新闻或文学理解能力。此外,该语料也适用于乌尔都语NLP的各类研究任务,包括语言现象分析、文本偏见检测以及新预处理技术的基准测试,甚至可作为构建下游任务评价指标的原始数据源。
背景与挑战
背景概述
ALIF_Urdu_Corpus(AUC)是由Orature AI团队于近年创建的大规模乌尔都语文本语料库,由S.M Ali Naqvi、Zainab Haider、Haya Fatima、Ali M Asad和Hammad Sajid等研究人员在Habib University的Dr. Abdul Samad指导下完成。该数据集旨在为乌尔都语生成式语言模型的预训练提供高质量、多样化的基础资源。作为ALIF项目的一部分,AUC的预览版本包含5000条样本数据,而完整版本规模高达33GB,覆盖了从Common Crawl、新闻网站、翻译数据、书籍OCR文本、博客及公开数据集等多源异构文本,为乌尔都语自然语言处理研究奠定了重要基石,对推动低资源语言深度学习技术发展具有显著影响力。
当前挑战
该数据集在构建和领域应用上面临多重挑战。首先,乌尔都语作为低资源语言,其预训练语料库匮乏且质量参差不齐,AUC需从非结构化网页(如Common Crawl)中过滤噪声内容,并解决文本清洗、编码归一化和语言检测等难题。其次,构建过程中面临数据异构性挑战,需整合来自翻译数据、OCR书籍和新闻网站等不同来源的文本,并利用MinHash-LSH算法进行严格的去重处理,以消除段落和文档层面的近似重复。此外,翻译数据依赖Google Translate API可能引入语义偏差,OCR后处理也需应对印刷与手写文本的识别误差,这些均对语料库的一致性和多样性构成考验。
常用场景
经典使用场景
ALIF_Urdu_Corpus(AUC)作为乌尔都语大规模预训练语料库,其核心用途在于为生成式语言模型提供高质量的预训练数据。研究者可借助该数据集丰富的文本多样性——涵盖网页爬取、新闻、书籍、翻译内容及博客等来源——训练具有深厚语言理解能力的基底模型。该预览版包含5000条精心清洗与去重的样本,足以为小规模实验与原型验证奠定基础。
解决学术问题
该数据集直面乌尔都语自然语言处理中低资源语种语料匮乏的核心困境。通过系统化收集与严格预处理(包括UTF-8编码统一、HTML噪声去除、基于MinHash的近似去重),AUC显著提升了预训练语料的规模与纯度,为研究者在语言建模、序列生成及跨领域迁移学习等任务上提供了可靠的数据支撑,推动了南亚区域语言的数字化演进与学术复兴。
衍生相关工作
基于AUC已衍生出多项里程碑式工作,包括专门的指令微调数据集ALIF-Urdu-Instruct,以及针对乌尔都语的基准评测套件。此外,研究者利用该语料训练了首批公开可用的乌尔都语大型语言模型,促进了南亚语言模型在情感分析、命名实体识别及文本分类等下游任务上的性能突破,并激发了对阿拉伯-波斯文字体系下语言建模独特挑战的深入探讨。
以上内容由遇见数据集搜集并总结生成


