temporal-nobel-prize
收藏Hugging Face2025-06-06 更新2025-06-07 收录
下载链接:
https://huggingface.co/datasets/LouisDo2108/temporal-nobel-prize
下载链接
链接失效反馈官方服务:
资源简介:
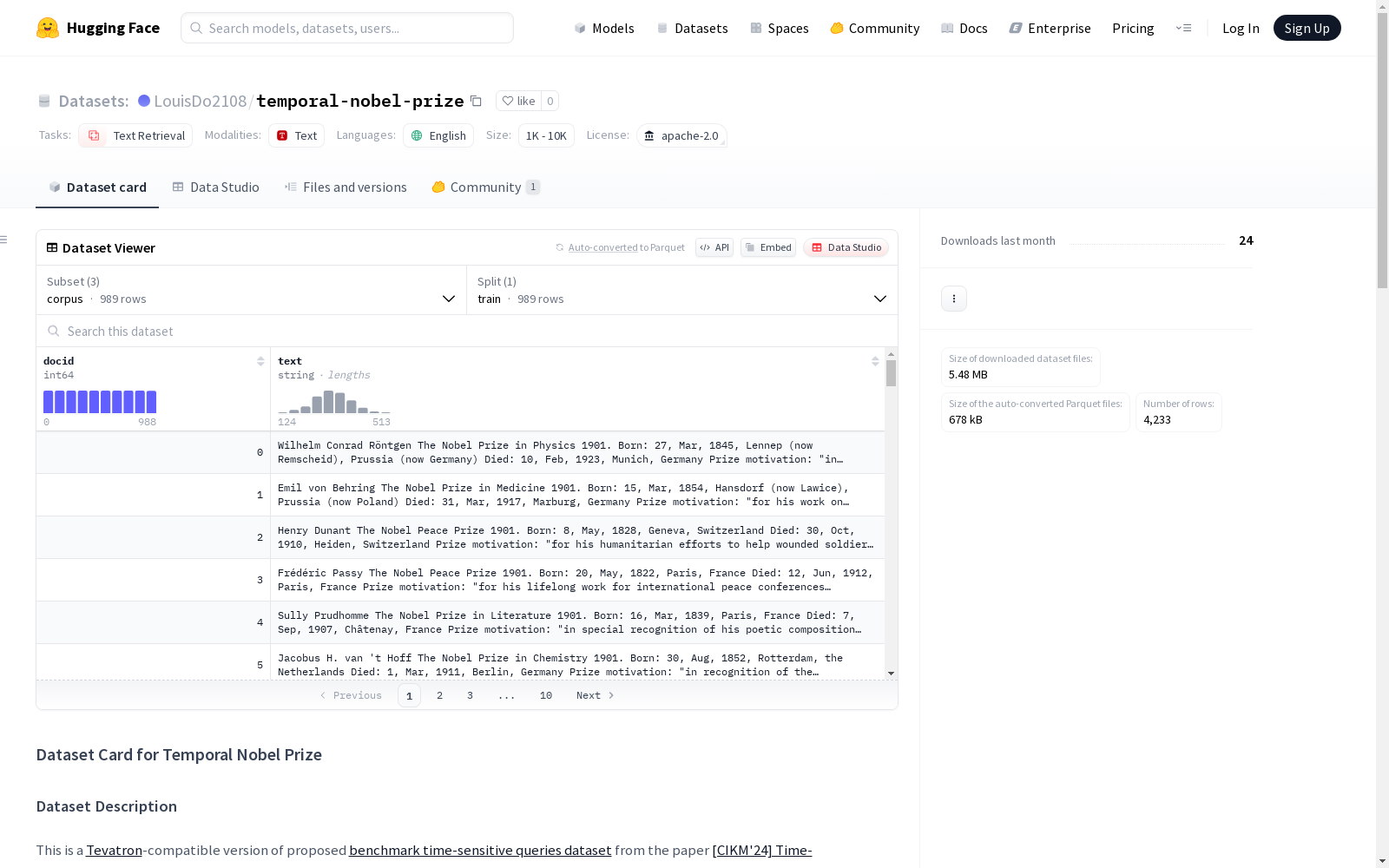
这是一个与诺贝尔奖相关的文本检索数据集,设计用于时间敏感的查询任务。数据集包括三个主要文件:corpus.jsonl、query.jsonl和qrel.txt。corpus.jsonl包含989条诺贝尔奖相关文档,query.jsonl包含3244条查询,每个查询都有对应的答案和相关的正文段落,qrel.txt则包含13110条查询与文档的相关性评估信息。数据集大小在1K到10K之间,适用于文本检索任务,尤其是那些需要考虑时间敏感性的任务。
创建时间:
2025-06-04
搜集汇总
数据集介绍
构建方式
在时间敏感信息检索研究领域,Temporal Nobel Prize数据集通过系统化采集1901年至2022年诺贝尔奖获奖者信息构建而成。其语料库包含989条结构化文档,每条记录均包含获奖者姓名、奖项类别及获奖年份等关键时间维度信息。查询数据集采用人工构建与验证方式,形成3244条具有明确时间范围约束的自然语言问句,并严格标注对应的正例文档集合。相关性判断文件采用TREC qrel标准格式,通过13110条标注数据确保评估体系的严谨性。
特点
该数据集最显著的特征在于其严格的时间敏感性设计,每个查询都包含明确的时间区间约束,要求检索系统具备时序推理能力。文档内容采用标准化格式呈现,保持字段结构的一致性,便于模型理解时间语义。正例文档集合经过多轮人工校验,确保标注质量的可靠性。数据集规模适中,包含三种结构化数据组件,完全兼容Tevatron和Pyserini等主流检索框架,为时间感知检索研究提供标准化评估基准。
使用方法
研究人员可通过HuggingFace平台直接加载数据集三个组件:corpus.jsonl作为文档库,query.jsonl提供测试查询及参考答案,qrel.txt则包含标准相关性标注。使用时应首先构建检索系统索引,采用密集检索或稀疏检索方法处理时间约束查询。评估阶段需下载原始qrel文件,利用Pyserini工具包计算标准信息检索指标。该数据集特别适用于时间敏感检索模型的性能验证,以及检索增强生成系统在时序问答任务中的效果评估。
背景与挑战
背景概述
Temporal Nobel Prize数据集由Wu Feifan等研究人员在2024年CIKM会议上提出,旨在构建一个时间敏感的检索增强生成基准数据集。该数据集聚焦于诺贝尔奖获奖者的时序信息检索,包含989篇文档和3244条查询,覆盖1901年以来的获奖记录。其核心研究问题在于解决时序敏感的信息检索与问答任务,为检索增强生成模型提供关键评估基准,推动时序信息处理领域的发展。
当前挑战
该数据集主要挑战在于处理时序敏感查询的复杂性,要求模型准确识别时间范围内的获奖者信息,避免时序错位导致的检索错误。构建过程中需整合分散的诺贝尔奖历史数据,确保时间标注的精确性与一致性,同时处理多答案查询的匹配问题,如同一奖项多年份获奖者的正例文档关联。
常用场景
经典使用场景
在时间敏感信息检索领域,该数据集通过诺贝尔奖获奖者的时空查询任务,为检索系统提供了验证时间感知能力的标准场景。研究者利用其结构化查询与文档关联,评估检索模型在时间约束下的准确性与召回率,尤其适用于测试模型对历史事件时序关系的理解能力。
解决学术问题
该数据集有效解决了时序信息检索中的关键挑战,包括时间边界界定、动态知识更新和跨时段证据整合等问题。通过提供精确的时间标注和答案验证机制,它为评估检索模型的时间敏感性提供了量化基准,推动了时序检索理论与方法学的创新发展。
衍生相关工作
基于该数据集衍生的经典工作包括时序检索增强生成(TS-RAG)框架、动态知识图谱补全方法以及多粒度时间编码模型。这些研究显著提升了时间敏感问答系统的性能,并催生了诸如时序对比学习和跨时段负采样等创新技术路线。
以上内容由遇见数据集搜集并总结生成


