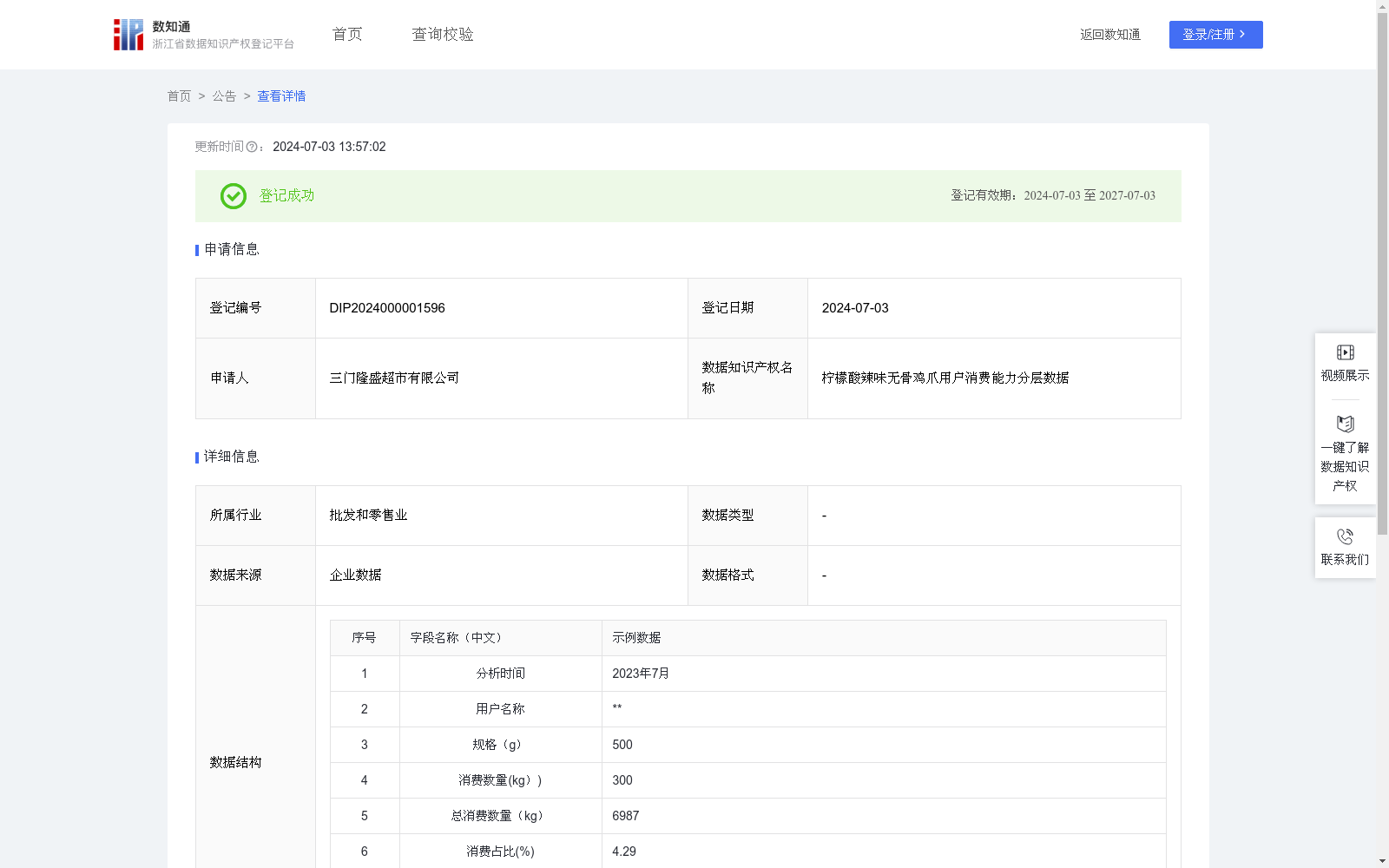
柠檬酸辣味无骨鸡爪用户消费能力分层数据
收藏浙江省数据知识产权登记平台2024-07-03 更新2024-07-04 收录
下载链接:
https://www.zjip.org.cn/home/announce/trends/36173
下载链接
链接失效反馈官方服务:
资源简介:
统计分析柠檬酸辣味无骨鸡爪消费数据,通过对历史下单用户画像建立,对用户进行标签制定,定位用户消费级别,为企业在全国各地设立产品周转仓及针对各地区消费者对辣度、规格的喜好有针对性的制定广告营销策略提供数据支持。1、用户消费柠檬酸辣味无骨鸡爪数量占总消费无骨鸡爪数量的比例=用户消费柠檬酸辣味无骨鸡爪数量/总消费无骨鸡爪数量*100%;2、用户消费占总消费的比例按从大到小进行排名;3、消费分类运用ABCDEF分类法,对占比6%以上的,给予“A类消费”分层;占比5%到6%区间的,则给予“B类消费”分层;占比在4%到5%区间,则给予“C类消费”分层。占比在3%到4%区间,则给予“D类消费”分层;占比在2%到3%区间,则给予“E类消费”分层;占比在2%以下,则给予“F类消费”分层。
This dataset is dedicated to the statistical analysis of consumption data for lemon-spicy boneless chicken feet. Specifically, we first construct user profiles based on historical order records, formulate user tags, and classify user consumption tiers, so as to provide data support for enterprises to establish product turnover warehouses across the country and develop targeted advertising and marketing strategies tailored to regional consumers' preferences for spiciness and product specifications. 1. The proportion of a user's consumption of lemon-spicy boneless chicken feet in their total boneless chicken feet consumption is calculated as: (Number of lemon-spicy boneless chicken feet consumed by the user / Total number of boneless chicken feet consumed by the user) × 100%. 2. Rank all users in descending order according to their calculated consumption proportion. 3. Apply the ABCDEF classification method for consumption tiering: users with a proportion exceeding 6% are classified as "Class A consumers"; those with a proportion ranging from 5% to 6% are "Class B consumers"; 4% to 5% is "Class C consumers"; 3% to 4% is "Class D consumers"; 2% to 3% is "Class E consumers"; and users with a proportion below 2% are categorized as "Class F consumers".
提供机构:
三门隆盛超市有限公司
创建时间:
2024-06-04
搜集汇总
数据集介绍
特点
该数据集包含629条柠檬酸辣味无骨鸡爪的消费记录,通过ABCDEF分类法对用户消费能力进行分层,用于企业营销策略和产品周转仓设立的决策支持。
以上内容由遇见数据集搜集并总结生成


