Criticality Prediction
收藏数据集卡片:Legal Criticality Prediction
数据集描述
数据集概述
Legal Criticality Prediction (LCP) 是一个多语言、历时数据集,包含139K瑞士联邦最高法院(FSCS)案件,带有两个关键性标签。bge_label 是一个二元标签(critical, non-critical),而 citation_label 有5个类别(critical-1, critical-2, critical-3, critical-4, non-critical)。citation_label 的关键类别是 bge_label 关键类别的不同子集。该数据集创建了一个具有挑战性的文本分类任务。此外,我们还提供了额外的元数据,如出版年份、法律领域和案件来源的州,以促进法律NLP领域的鲁棒性和公平性研究。
支持的任务和排行榜
LCP 可用于文本分类任务。
语言
数据集包含瑞士的三种官方语言:德语、法语和意大利语。案件由法官和书记员用诉讼语言书写。
- 德语 (91k)
- 法语 (33k)
- 意大利语 (15k)
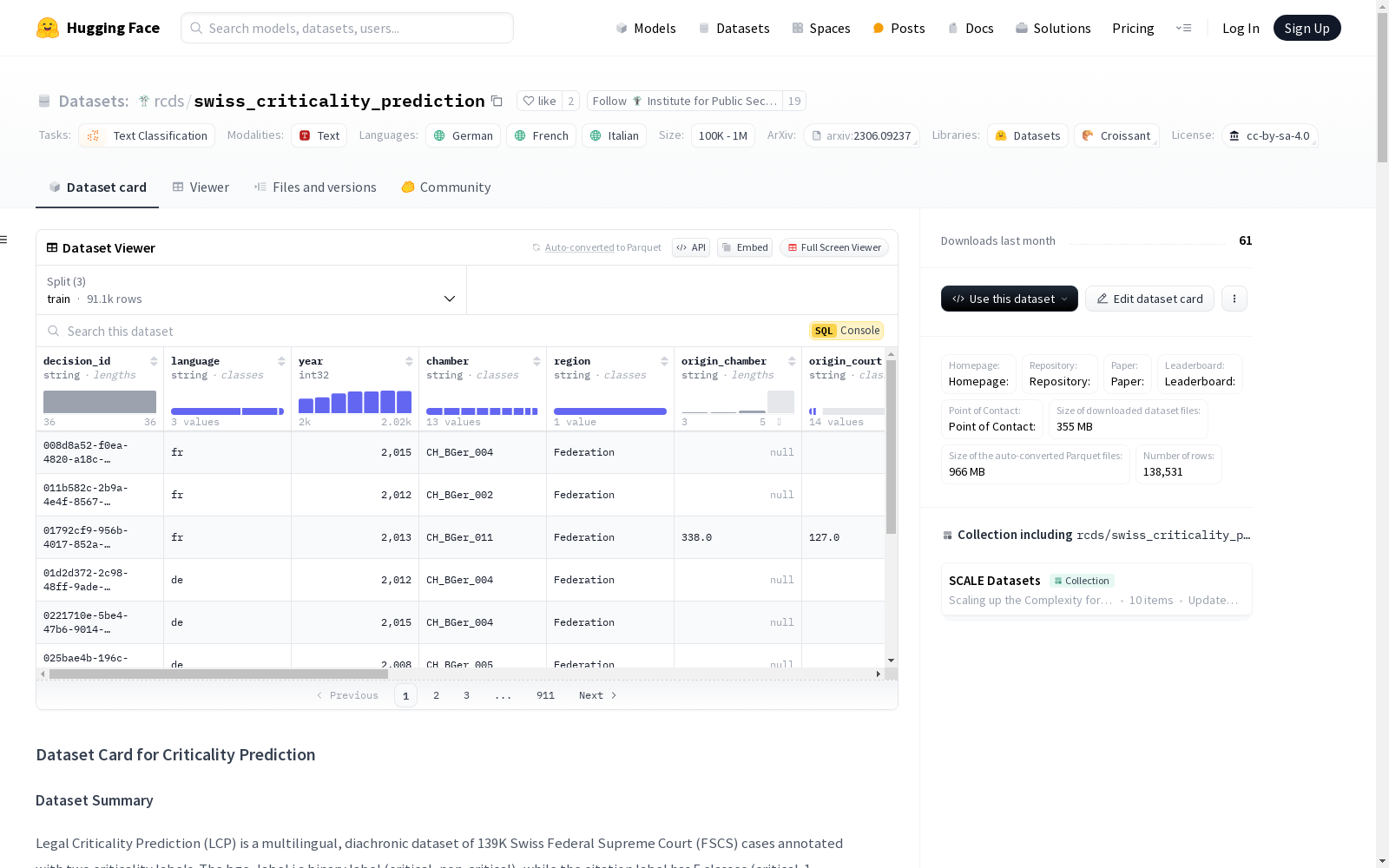
数据集结构
数据实例
json { "decision_id": "008d8a52-f0ea-4820-a18c-d06066dbb407", "language": "fr", "year": "2018", "chamber": "CH_BGer_004", "region": "Federation", "origin_chamber": "338.0", "origin_court": "127.0", "origin_canton": "24.0", "law_area": "civil_law", "law_sub_area": "", "bge_label": "critical", "citation_label": "critical-1", "facts": "Faits : A. A.a. Le 17 août 2007, C.X._, née le 14 février 1944 et domiciliée...", "considerations": "Considérant en droit : 1. Interjeté en temps utile (art. 100 al. 1 LTF) par les défendeurs qui ont succombé dans leurs conclusions (art. 76 LTF) contre une décision...", "rulings": "Par ces motifs, le Tribunal fédéral prononce : 1. Le recours est rejeté. 2. Les frais judiciaires, arrêtés à 10000 fr., sont mis solidairement à la charge des recourants..." }
数据字段
decision_id: (str) 文档的唯一标识符language: (str) 语言 (de, fr, it)year: (int) 出版年份chamber: (str) 案件所在的法庭region: (str) 案件所在的地区origin_chamber: (str) 原始案件的法庭origin_court: (str) 原始案件的法院origin_canton: (str) 原始案件的州law_area: (str) 案件的法律领域law_sub_area: (str) 案件的法律子领域bge_label: (str) 关键性标签 (critical, non-critical)citation_label: (str) 引用标签 (critical-1, critical-2, critical-3, critical-4, non-critical)facts: (str) 案件的事实considerations: (str) 案件的考虑rulings: (str) 案件的裁决
数据分割
数据集按日期分割:
- 训练集: 2002-2015
- 验证集: 2016-2017
- 测试集: 2018-2022
| 语言 | 子集 | 文档数量 (训练/验证/测试) |
|---|---|---|
| 德语 | de | 81,264 (56,592 / 19,601 / 5,071) |
| 法语 | fr | 49,354 (29,263 / 11,117 / 8,974) |
| 意大利语 | it | 7,913 (5,220 / 1,901 / 792) |
数据集创建
数据来源
原始数据由瑞士联邦最高法院发布(https://www.bger.ch),格式为未处理的HTML。文档从Entscheidsuche门户(https://entscheidsuche.ch)下载为HTML格式。
注释过程
bge_label: 提取bge标题中的所有bger_references,并将bger文件名与找到的引用进行比较。citation_label: 计算所有bger案件的所有引用并加权引用,根据引用数量将引用案件分为四个不同的类别。
个人和敏感信息
数据集包含瑞士联邦最高法院的公开法庭判决。个人或敏感信息在发布前已由法院根据以下指南进行匿名化:https://www.bger.ch/home/juridiction/anonymisierungsregeln.html。
附加信息
许可信息
数据集在CC-BY-4.0许可下发布,符合法院许可(https://www.bger.ch/files/live/sites/bger/files/pdf/de/urteilsveroeffentlichung_d.pdf)。
引用信息
请引用我们的ArXiv预印本:https://arxiv.org/abs/2306.09237
@misc{rasiah2023scale, title={SCALE: Scaling up the Complexity for Advanced Language Model Evaluation}, author={Vishvaksenan Rasiah and Ronja Stern and Veton Matoshi and Matthias Stürmer and Ilias Chalkidis and Daniel E. Ho and Joel Niklaus}, year={2023}, eprint={2306.09237}, archivePrefix={arXiv}, primaryClass={cs.CL} }
- 1Breaking the Manual Annotation Bottleneck: Creating a Comprehensive Legal Case Criticality Dataset through Semi-Automated Labeling伯尔尼大学、伯尔尼应用科学大学、斯坦福大学、哥本哈根大学 · 2024年


