bBSARD
收藏arXiv2024-12-10 更新2024-12-12 收录
下载链接:
https://huggingface.co/datasets/clips/bBSARD
下载链接
链接失效反馈官方服务:
资源简介:
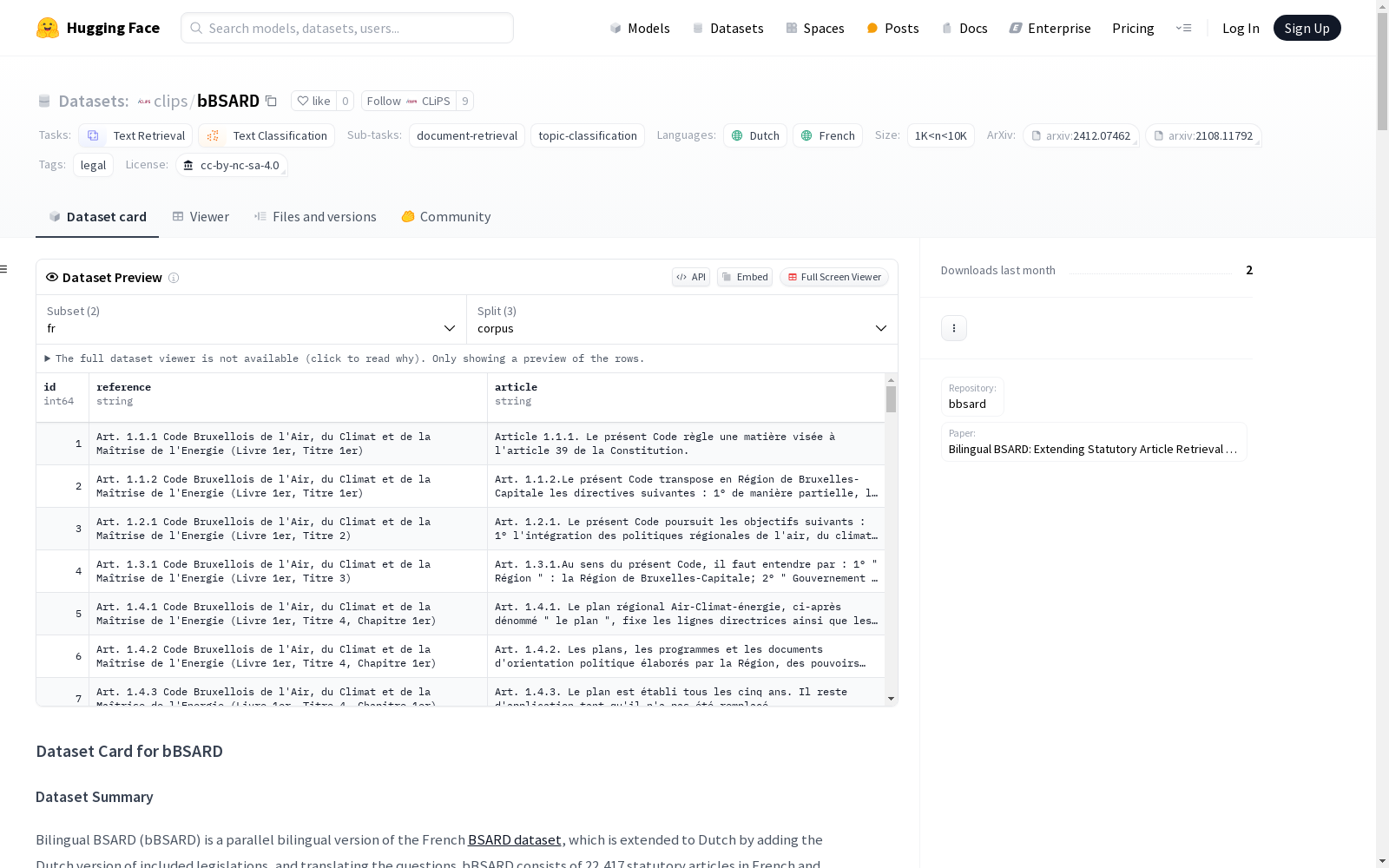
bBSARD数据集是基于比利时法定条文检索数据集(BSARD)扩展的双语版本,包含法语和荷兰语的平行法律条文,旨在解决比利时多语言法律检索的挑战。数据集包含22417条法律条文和1108个法律问题,问题主要涉及家庭、住房、金钱等主题。数据集通过从比利时联邦政府的Justel数据库中抓取法语和荷兰语的条文,并使用GPT-4进行自动翻译和人工校对创建。该数据集主要用于评估和改进荷兰语和法语的法律检索模型,特别是在多语言法律环境中的应用。
The bBSARD dataset is a bilingual extended variant of the Belgian Statutory Article Retrieval Dataset (BSARD), which contains parallel legal texts in French and Dutch, aiming to tackle the challenges of multilingual legal retrieval in Belgium. The dataset comprises 22,417 legal articles and 1,108 legal questions, with the questions primarily covering topics such as family, housing, and financial matters. It was developed by scraping French and Dutch legal articles from the Justel database of the Belgian Federal Government, followed by automatic translation using GPT-4 and manual proofreading. This dataset is mainly used to evaluate and improve legal retrieval models for Dutch and French, especially for applications in multilingual legal environments.
提供机构:
安特卫普大学CLiPS
创建时间:
2024-12-10
搜集汇总
数据集介绍
构建方式
bBSARD数据集基于比利时法语版的BSARD数据集构建,扩展至荷兰语版本。该数据集通过从比利时联邦政府维护的Justel数据库中抓取法语和荷兰语的平行法律条文,并使用自动翻译结合人工校对的方式将BSARD中的法律问题翻译成荷兰语。最终,数据集包含了22,417篇平行法律条文,涵盖了比利时联邦和瓦隆地区的32个法律条文,确保了法语和荷兰语条文在同一立法版本下的对齐。
特点
bBSARD数据集的主要特点在于其双语平行结构,包含了法语和荷兰语的法律条文以及相应的法律问题。该数据集不仅为荷兰语的法律检索任务提供了基准,还通过双语对齐的方式,为跨语言法律检索模型的研究提供了丰富的资源。此外,数据集中的法律问题涵盖了家庭、住房、金钱、司法等多个领域,具有较高的实用性和多样性。
使用方法
bBSARD数据集可用于评估和训练法律检索模型,尤其是在多语言环境下的法律信息检索任务。研究者可以使用该数据集进行零样本学习、微调模型以及跨语言检索实验。数据集支持多种检索模型的评估,包括基于词汇的模型(如BM25)、零样本模型(如mE5、LaBSE)以及微调模型(如RobBERT、FlauBERT)。通过这些实验,研究者可以深入探索不同语言模型在法律检索任务中的表现,并为未来的法律信息检索系统提供优化方向。
背景与挑战
背景概述
在法律信息获取领域,法律条文检索是确保公众和法律专业人士能够高效访问法律信息的关键。比利时作为一个多语言国家,面临着在不同语言间处理法律问题的独特挑战。基于法国版的比利时法律条文检索数据集(BSARD),Ehsan Lotfi、Nikolay Banar等研究人员于2022年扩展了该数据集,创建了双语版本的bBSARD数据集。该数据集包含了比利时法律条文的双语(法语和荷兰语)平行文本,以及从BSARD中提取的法律问题及其荷兰语翻译。通过bBSARD,研究人员对荷兰语和法语的检索模型进行了广泛的基准测试,展示了BM25等传统模型的竞争力,并揭示了在零样本和微调场景下,小型语言特定模型的潜力。
当前挑战
bBSARD数据集的构建面临多重挑战。首先,如何在多语言环境下确保法律条文的准确性和一致性是一个重要问题。其次,数据集的构建过程中,研究人员需要从比利时联邦政府的Justel数据库中抓取并手动对齐大量的法律条文,这一过程耗时且容易出错。此外,法律条文的翻译也需要高度的专业性,以确保法律术语的准确传达。最后,尽管bBSARD为荷兰语提供了急需的检索基准,但数据集的局限性在于其仅涵盖了比利时联邦和瓦隆地区的法律条文,未涉及弗拉芒地区的法律条文,这限制了其在更广泛法律领域的应用。
常用场景
经典使用场景
bBSARD数据集的经典使用场景主要集中在法律信息检索领域,特别是在比利时这样的多语言国家中。该数据集通过提供法语和荷兰语的平行法律条文以及相应的法律问题翻译,使得研究者能够开发和评估多语言法律检索模型。这些模型可以有效地帮助法律从业者和普通公民在多语言环境下快速找到相关的法律条文,从而提高法律信息的可访问性和实用性。
解决学术问题
bBSARD数据集解决了多语言法律检索中的关键学术问题,特别是在处理法律条文和问题时如何跨越语言障碍。通过提供法语和荷兰语的平行数据,该数据集为研究者提供了一个可靠的基准,用于评估和比较不同检索模型的性能。这不仅推动了法律信息检索技术的发展,还为多语言环境下的法律信息处理提供了新的研究方向。
衍生相关工作
基于bBSARD数据集,许多相关工作得以展开,特别是在多语言法律检索模型的开发和评估方面。例如,研究者们利用该数据集进行了广泛的基准测试,比较了不同模型在法语和荷兰语检索任务中的表现。此外,该数据集还激发了更多关于跨语言法律信息处理的研究,推动了法律自然语言处理领域的进一步发展。
以上内容由遇见数据集搜集并总结生成


