HOIGen-1M
收藏arXiv2025-03-31 更新2025-04-03 收录
下载链接:
https://liuqi-creat.github.io/HOIGen.github.io
下载链接
链接失效反馈官方服务:
资源简介:
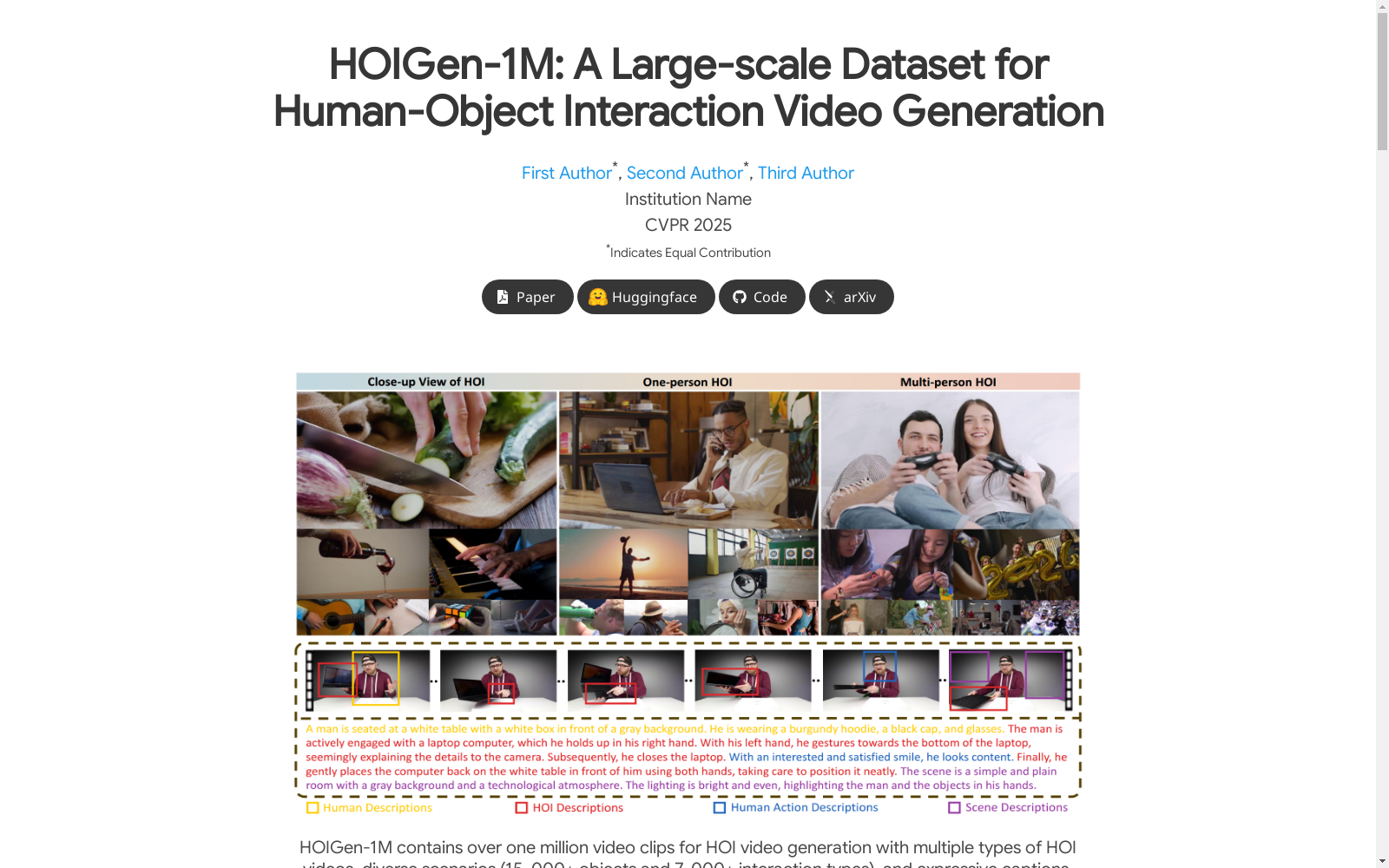
HOIGen-1M是一个大规模的高质量人类对象交互视频生成数据集,由京东探索学院等机构构建。该数据集包含超过一百万段经过人工验证的、涵盖多种人类对象交互场景的高质量视频。这些视频选自80百万段原始视频,经过严格的筛选和处理流程,包括元数据过滤、光学字符识别去除、美学评分筛选、动作评分筛选、语言模型评估和人工审核。数据集的视频分辨率至少为720p,包含三种细粒度交互类型,旨在为文本到视频的生成任务提供支持。
HOIGen-1M is a large-scale, high-quality human-object interaction (HOI) video generation dataset constructed by institutions including JD Explore Academy. This dataset contains over one million manually verified high-quality videos covering diverse human-object interaction scenarios. These videos are selected from 80 million raw videos and have undergone rigorous screening and processing workflows, including metadata filtering, optical character recognition (OCR) removal, aesthetic score screening, action score evaluation, large language model (LLM) assessment, and manual review. The videos in the dataset have a minimum resolution of 720p and include three fine-grained interaction types. It is designed to support text-to-video generation tasks.
提供机构:
京东探索学院,中国科学院大学,中国科学技术大学,罗切斯特大学
创建时间:
2025-03-31
搜集汇总
数据集介绍
构建方式
HOIGen-1M数据集的构建采用了多阶段筛选与标注流程,首先从BEHAVE、InterCap等HOI感知数据集及Panda-70M等通用视频数据集中初选8000万条原始视频。通过元数据分析(分辨率≥720p、时长≥1秒)、光学字符识别去噪、美学评分筛选(Laion Aesthetic Predictor)和运动评分(UniMatch光流分析)构建初级过滤层。随后采用PLLaVA多模态模型生成描述,结合Qwen2.5大语言模型进行HOI存在性判断,最终由7名标注员进行人工核验,从1.5万候选视频中精选110万条高质量HOI视频,整体筛选通过率约1.375%。
特点
该数据集的核心优势体现在三维度特征:规模维度上,其包含110万条经过人工验证的HOI视频,总时长2200小时,远超现有HOI感知数据集(如HOI4D仅4000段视频);质量维度上,所有视频均满足720p以上分辨率,通过美学一致性、时序连贯性、运动差异度等五重质量指标验证,且采用MoME策略消除多模态大模型描述中的幻觉问题;语义维度上,平均描述长度达153.8词(WebVid-10M仅12词),涵盖15,000种物体和7,000种交互类型,构建了当前最细粒度的HOI语义体系。
使用方法
使用该数据集时,建议采用三阶段流程:预训练阶段可结合WebVid-10M等通用视频数据增强模型基础能力;微调阶段需重点利用其结构化提示词(含<Human><HOI><Scene>标签),通过LORA机制适配交互生成任务;评估阶段推荐采用论文提出的CoarseHOIScore(基于HOI检测器)和FineHOIScore(像素级接触分析)双指标体系。实验表明,CogVideoX-5B模型经该数据集微调后,CoarseHOIScore可从32.84%提升至44.04%,显著优于未微调的商业模型Kling 1.5(42.72%)。
背景与挑战
背景概述
HOIGen-1M是由JD Explore Academy、USTC等机构的研究团队于2025年提出的首个大规模人-物交互(HOI)视频生成数据集。该数据集包含超过100万条高质量视频片段,涵盖15,000多种物体和7,000多种交互类型,旨在解决当前文本到视频(T2V)生成模型在人-物交互场景中的表现不足问题。研究人员创新性地设计了基于多模态大语言模型(MLLM)的数据筛选框架和混合多模态专家(MoME)标注策略,显著提升了视频描述的质量和准确性。作为该领域的开创性工作,HOIGen-1M为人-物交互视频生成研究提供了重要的基准资源,推动了计算机视觉和视频生成技术的发展。
当前挑战
HOIGen-1M主要面临两大核心挑战:在领域问题方面,当前T2V模型难以准确生成复杂的人-物交互视频,主要由于缺乏大规模、高质量且标注精确的训练数据;在数据集构建方面,研究人员需要从8000万原始视频中筛选出符合要求的HOI视频,并解决多模态大模型在视频描述中产生的幻觉问题。为此,团队开发了创新的数据筛选流程和MoME标注策略,通过多模型交叉验证确保描述准确性。此外,针对HOI视频评估标准缺失的问题,研究者还提出了CoarseHOIScore和FineHOIScore两阶段评估指标,为相关研究提供了新的评价体系。
常用场景
经典使用场景
HOIGen-1M数据集在计算机视觉领域被广泛应用于人-物交互(HOI)视频生成任务。该数据集包含超过一百万条高质量视频片段,涵盖15,000多种物体和7,000多种交互类型,为文本到视频(T2V)生成模型提供了丰富的训练素材。其经典使用场景包括生成具有复杂人-物交互行为的视频序列,例如人类与乐器、交通工具或厨房工具的互动。这些场景在现有T2V模型中往往难以精确生成,而HOIGen-1M通过其大规模、高质量的标注数据有效解决了这一问题。
实际应用
在实际应用层面,HOIGen-1M数据集为多个领域提供了重要支持。在虚拟现实领域,可用于生成逼真的人机交互场景;在教育领域,能够创建生动的教学演示视频;在自动驾驶领域,可为算法训练提供丰富的行人-物体交互场景。实验表明,基于该数据集微调的T2V模型在生成质量上显著提升,例如CogVideoX-5B模型在CoarseHOIScore指标上达到了与商业软件Kling 1.5相当的水平。这些应用验证了数据集在提升实际场景视频生成效果方面的价值。
衍生相关工作
HOIGen-1M数据集催生了一系列相关研究工作。在模型架构方面,推动了如CogVideoX等开源视频生成模型的改进;在评估方法上,启发了基于HOIScore的细粒度视频质量评估体系;在数据增强领域,其MoME标注策略为多模态数据标注提供了新思路。该数据集还促进了HOI检测与生成任务的协同发展,例如将HOI检测器用于生成视频的质量评估。这些衍生工作共同推动了人-物交互视频生成这一细分领域的技术进步。
以上内容由遇见数据集搜集并总结生成


