reddit_dataset_72
收藏Hugging Face2025-05-09 更新2025-05-10 收录
下载链接:
https://huggingface.co/datasets/James096/reddit_dataset_72
下载链接
链接失效反馈官方服务:
资源简介:
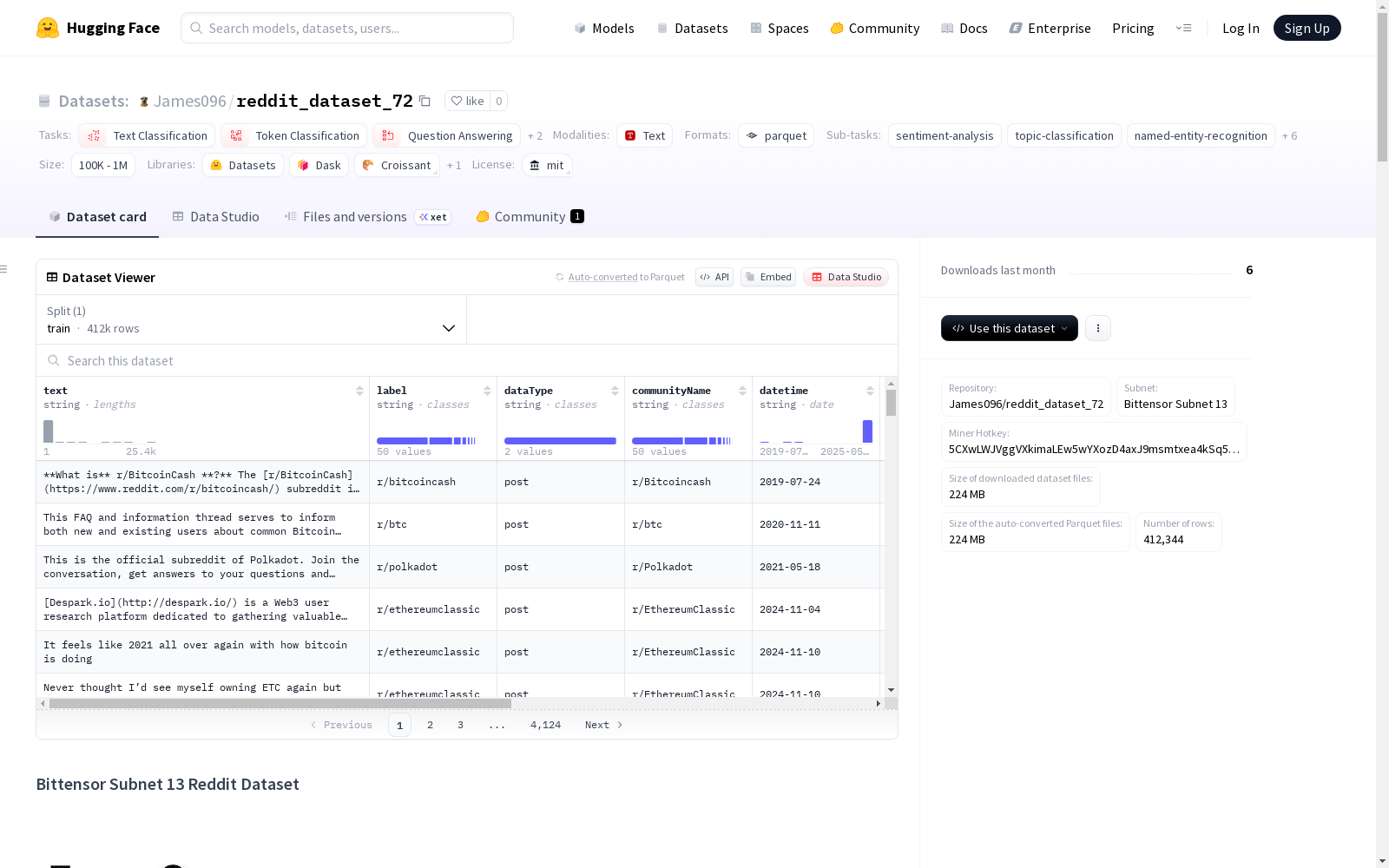
Bittensor Subnet 13 Reddit数据集是Bittensor Subnet 13去中心化网络的一部分,包含了经过预处理的Reddit数据。这些数据由网络矿工持续更新,提供了实时的Reddit内容流,适用于进行各种分析和机器学习任务。数据集主要是英文,但也包含多语言内容。每个数据实例代表一个Reddit帖子或评论,包括文本内容、情感或主题标签、数据类型、社区名称、发布时间戳、编码后的用户名和URL。该数据集没有固定的数据分割,用户需要根据需求和时间戳自行创建。数据来源于Reddit的公开帖子或评论,所有个人信息都经过编码处理。
创建时间:
2025-05-03
搜集汇总
数据集介绍
构建方式
在社交媒体分析领域,该数据集依托Bittensor Subnet 13去中心化网络构建,通过分布式矿工实时采集Reddit平台的公开帖文与评论。数据源严格遵循Reddit服务条款与API规范,采用自动化流程对原始内容进行结构化处理,涵盖文本内容、情感标签、社区分类等核心字段,并通过编码技术对用户名与链接进行匿名化处理以保障用户隐私。
特点
该数据集呈现多维度特征,其时间跨度自2019年至2025年,包含41万余条数据实例且持续动态更新。数据结构上以评论内容为主体(占比99.01%),覆盖政治、科技、加密货币等十大核心社区话题,其中r/AskReddit板块占比达45.93%。数据字段设计兼顾语义分析与隐私保护,同时具备多语言特性,为社交动态研究提供丰富样本。
使用方法
研究者可通过HuggingFace平台直接加载该数据集,利用其文本分类、实体识别等任务适配性开展社会计算研究。建议使用者根据时间戳字段构建自定义数据分割,结合社区名称与数据类型字段进行垂直领域分析。需注意数据存在时空偏差与社交平台固有噪声,建议配合去偏差技术提升模型鲁棒性,同时遵守MIT许可与Reddit使用条款。
背景与挑战
背景概述
作为Bittensor Subnet 13去中心化网络的重要组成部分,reddit_dataset_72数据集由James096等研究人员于2025年构建,旨在通过实时采集Reddit平台公开内容,为自然语言处理领域提供动态语料资源。该数据集聚焦于社交媒体文本的多维度分析,覆盖情感分析、主题分类、命名实体识别等核心任务,其去中心化采集机制突破了传统数据集的静态局限,为社交计算研究提供了持续演化的实证基础。
当前挑战
在领域问题层面,该数据集需应对社交媒体文本固有的语义模糊性与文化语境多样性,例如讽刺表达与跨社区术语差异对分类任务造成的干扰。构建过程中面临实时数据流的质量控制难题,包括垃圾信息过滤、时序偏差校正,以及隐私保护与数据完整性之间的平衡——通过用户名编码虽规避了隐私风险,但可能削弱用户行为关联分析的有效性。
常用场景
经典使用场景
在社交媒体分析领域,reddit_dataset_72数据集凭借其丰富的Reddit平台内容,常被用于情感分析和主题建模研究。该数据集覆盖了从政治、技术到加密货币等多元社区,为探索网络社群动态提供了真实语料。通过分析用户评论与帖子的情感倾向,研究者能够揭示公众舆论的演变规律,同时利用主题分类技术识别热门讨论焦点,深化对在线交流模式的理解。
解决学术问题
该数据集有效解决了社交媒体研究中数据稀疏性与时效性不足的难题。通过去中心化网络实时更新的机制,它为自然语言处理任务如命名实体识别和文本生成提供了大规模训练资源。其多任务支持特性助力学者突破传统方法的局限,例如在跨社区语言模式比较中验证理论假设,推动计算社会科学与人工智能的交叉创新。
衍生相关工作
基于该数据集衍生的经典研究包括去中心化数据采集框架的优化,以及多模态社交媒体分析模型的开发。例如结合Bittensor子网架构的工作探索了分布式数据验证机制,另有研究利用其时序特性构建了动态话题演化图谱。这些成果进一步推动了隐私保护技术与语义理解算法的融合创新。
以上内容由遇见数据集搜集并总结生成


