有没有相关的论文或文献参考?
这个数据集是基于什么背景创建的?
数据集的作者是谁?
能帮我联系到这个数据集的作者吗?
这个数据集如何下载?
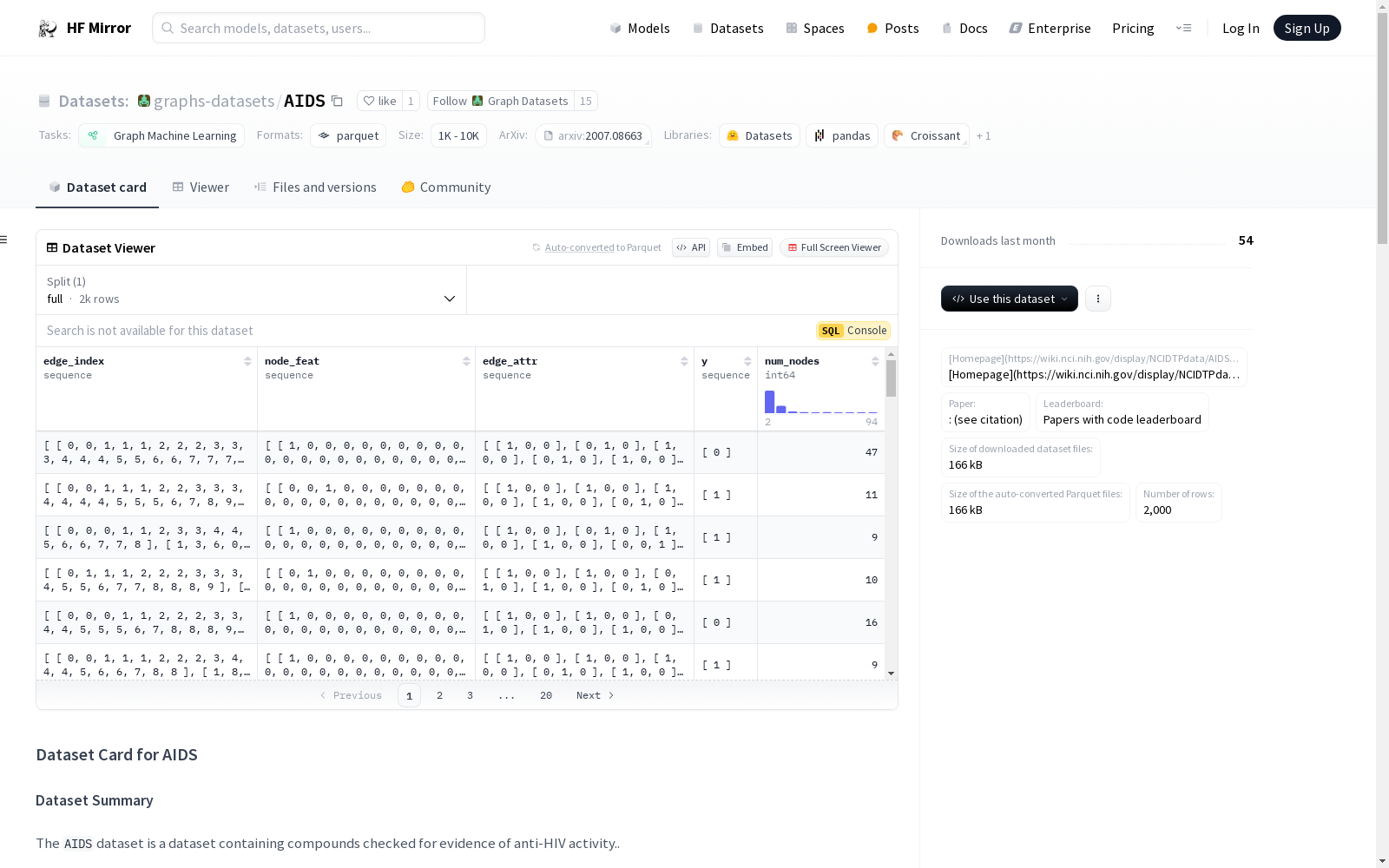
AIDS 数据集包含用于检测抗HIV活性的化合物。
AIDS 应用于分子分类,这是一个二元分类任务。评分标准是使用交叉验证的准确性。
在 PyGeometric 中加载数据集的示例如下:
python from datasets import load_dataset from torch_geometric.data import Data from torch_geometric.loader import DataLoader
dataset_hf = load_dataset("graphs-datasets/<mydataset>")
dataset_pg_list = [Data(graph) for graph in dataset_hf["train"]] dataset_pg = DataLoader(dataset_pg_list)
| 属性 | 值 |
|---|---|
| 规模 | 中等 |
| 图数量 | 1999 |
| 平均节点数 | 15.5875 |
| 平均边数 | 32.39 |
每个文件的每一行是一个图,包含以下字段:
node_feat (列表: #节点 x #节点特征): 节点edge_index (列表: 2 x #边): 构成边的节点对edge_attr (列表: #边 x #边特征): 上述边的特征y (列表: 1 x #标签): 可预测的标签数量(这里为1,等于零或一)num_nodes (整数): 图的节点数量该数据集未分割,应使用交叉验证。数据来自 PyGeometric 版本的数据集。
数据集的许可未知。
@inproceedings{Morris+2020, title={TUDataset: A collection of benchmark datasets for learning with graphs}, author={Christopher Morris and Nils M. Kriege and Franka Bause and Kristian Kersting and Petra Mutzel and Marion Neumann}, booktitle={ICML 2020 Workshop on Graph Representation Learning and Beyond (GRL+ 2020)}, archivePrefix={arXiv}, eprint={2007.08663}, url={www.graphlearning.io}, year={2020} }
@InProceedings{10.1007/978-3-540-89689-0_33, author="Riesen, Kaspar and Bunke, Horst", editor="da Vitoria Lobo, Niels and Kasparis, Takis and Roli, Fabio and Kwok, James T. and Georgiopoulos, Michael and Anagnostopoulos, Georgios C. and Loog, Marco", title="IAM Graph Database Repository for Graph Based Pattern Recognition and Machine Learning", booktitle="Structural, Syntactic, and Statistical Pattern Recognition", year="2008", publisher="Springer Berlin Heidelberg", address="Berlin, Heidelberg", pages="287--297", abstract="In recent years the use of graph based representation has gained popularity in pattern recognition and machine learning. As a matter of fact, object representation by means of graphs has a number of advantages over feature vectors. Therefore, various algorithms for graph based machine learning have been proposed in the literature. However, in contrast with the emerging interest in graph based representation, a lack of standardized graph data sets for benchmarking can be observed. Common practice is that researchers use their own data sets, and this behavior cumbers the objective evaluation of the proposed methods. In order to make the different approaches in graph based machine learning better comparable, the present paper aims at introducing a repository of graph data sets and corresponding benchmarks, covering a wide spectrum of different applications.", isbn="978-3-540-89689-0" }
GME Data
关于2021年GameStop股票活动的数据,包括每日合并的GME短期成交量数据、每日失败交付数据、可借股数、期权链数据以及不同时间框架的开盘/最高/最低/收盘/成交量条形图。
github 收录
中国区域交通网络数据集
该数据集包含中国各区域的交通网络信息,包括道路、铁路、航空和水路等多种交通方式的网络结构和连接关系。数据集详细记录了各交通节点的位置、交通线路的类型、长度、容量以及相关的交通流量信息。
data.stats.gov.cn 收录
中国交通事故深度调查(CIDAS)数据集
交通事故深度调查数据通过采用科学系统方法现场调查中国道路上实际发生交通事故相关的道路环境、道路交通行为、车辆损坏、人员损伤信息,以探究碰撞事故中车损和人伤机理。目前已积累深度调查事故10000余例,单个案例信息包含人、车 、路和环境多维信息组成的3000多个字段。该数据集可作为深入分析中国道路交通事故工况特征,探索事故预防和损伤防护措施的关键数据源,为制定汽车安全法规和标准、完善汽车测评试验规程、
北方大数据交易中心 收录
CIFAR-10
CIFAR-10 数据集由 10 个类别的 60000 个 32x32 彩色图像组成,每个类别包含 6000 个图像。有 50000 个训练图像和 10000 个测试图像。 数据集分为五个训练批次和一个测试批次,每个批次有 10000 张图像。测试批次恰好包含来自每个类别的 1000 个随机选择的图像。训练批次包含随机顺序的剩余图像,但一些训练批次可能包含来自一个类的图像多于另一个。在它们之间,训练批次恰好包含来自每个类别的 5000 张图像。
OpenDataLab 收录
OpenSonarDatasets
OpenSonarDatasets是一个致力于整合开放源代码声纳数据集的仓库,旨在为水下研究和开发提供便利。该仓库鼓励研究人员扩展当前的数据集集合,以增加开放源代码声纳数据集的可见性,并提供一个更容易查找和比较数据集的方式。
github 收录