---
licence: unknown
task_categories:
- graph-ml
---
# Dataset Card for AIDS
## Table of Contents
- [Table of Contents](#table-of-contents)
- [Dataset Description](#dataset-description)
- [Dataset Summary](#dataset-summary)
- [Supported Tasks and Leaderboards](#supported-tasks-and-leaderboards)
- [External Use](#external-use)
- [PyGeometric](#pygeometric)
- [Dataset Structure](#dataset-structure)
- [Data Properties](#data-properties)
- [Data Fields](#data-fields)
- [Data Splits](#data-splits)
- [Additional Information](#additional-information)
- [Licensing Information](#licensing-information)
- [Citation Information](#citation-information)
- [Contributions](#contributions)
## Dataset Description
- **[Homepage](https://wiki.nci.nih.gov/display/NCIDTPdata/AIDS+Antiviral+Screen+Data)**
- **Paper:**: (see citation)
- **Leaderboard:**: [Papers with code leaderboard](https://paperswithcode.com/sota/graph-classification-on-aids)
### Dataset Summary
The `AIDS` dataset is a dataset containing compounds checked for evidence of anti-HIV activity..
### Supported Tasks and Leaderboards
`AIDS` should be used for molecular classification, a binary classification task. The score used is accuracy with cross validation.
## External Use
### PyGeometric
To load in PyGeometric, do the following:
```python
from datasets import load_dataset
from torch_geometric.data import Data
from torch_geometric.loader import DataLoader
dataset_hf = load_dataset("graphs-datasets/<mydataset>")
# For the train set (replace by valid or test as needed)
dataset_pg_list = [Data(graph) for graph in dataset_hf["train"]]
dataset_pg = DataLoader(dataset_pg_list)
```
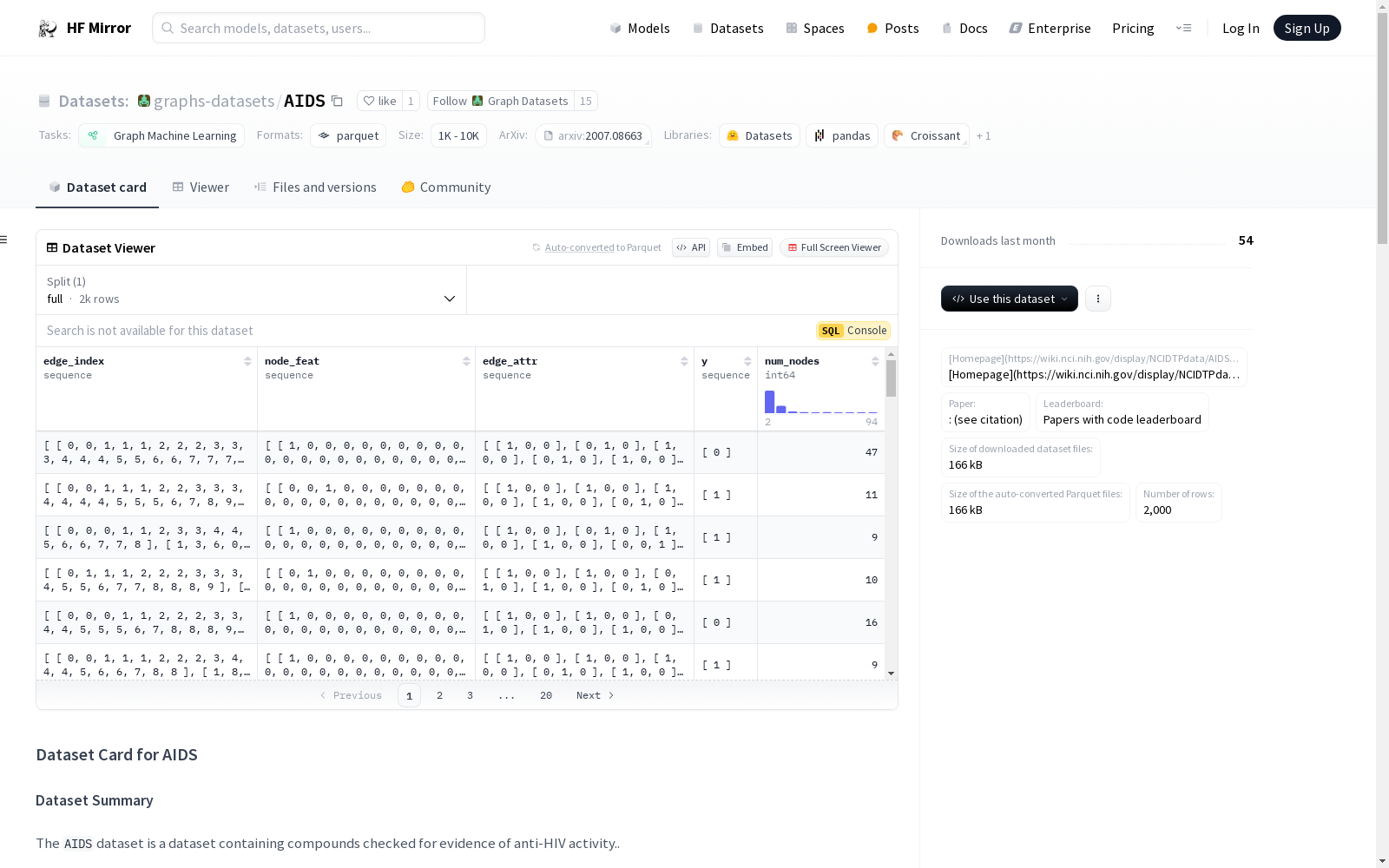
## Dataset Structure
### Data Properties
| property | value |
|---|---|
| scale | medium |
| #graphs | 1999 |
| average #nodes | 15.5875 |
| average #edges | 32.39 |
### Data Fields
Each row of a given file is a graph, with:
- `node_feat` (list: #nodes x #node-features): nodes
- `edge_index` (list: 2 x #edges): pairs of nodes constituting edges
- `edge_attr` (list: #edges x #edge-features): for the aforementioned edges, contains their features
- `y` (list: 1 x #labels): contains the number of labels available to predict (here 1, equal to zero or one)
- `num_nodes` (int): number of nodes of the graph
### Data Splits
This data is not split, and should be used with cross validation. It comes from the PyGeometric version of the dataset.
## Additional Information
### Licensing Information
The dataset has been released under license unknown.
### Citation Information
```
@inproceedings{Morris+2020,
title={TUDataset: A collection of benchmark datasets for learning with graphs},
author={Christopher Morris and Nils M. Kriege and Franka Bause and Kristian Kersting and Petra Mutzel and Marion Neumann},
booktitle={ICML 2020 Workshop on Graph Representation Learning and Beyond (GRL+ 2020)},
archivePrefix={arXiv},
eprint={2007.08663},
url={www.graphlearning.io},
year={2020}
}
```
```
@InProceedings{10.1007/978-3-540-89689-0_33,
author="Riesen, Kaspar
and Bunke, Horst",
editor="da Vitoria Lobo, Niels
and Kasparis, Takis
and Roli, Fabio
and Kwok, James T.
and Georgiopoulos, Michael
and Anagnostopoulos, Georgios C.
and Loog, Marco",
title="IAM Graph Database Repository for Graph Based Pattern Recognition and Machine Learning",
booktitle="Structural, Syntactic, and Statistical Pattern Recognition",
year="2008",
publisher="Springer Berlin Heidelberg",
address="Berlin, Heidelberg",
pages="287--297",
abstract="In recent years the use of graph based representation has gained popularity in pattern recognition and machine learning. As a matter of fact, object representation by means of graphs has a number of advantages over feature vectors. Therefore, various algorithms for graph based machine learning have been proposed in the literature. However, in contrast with the emerging interest in graph based representation, a lack of standardized graph data sets for benchmarking can be observed. Common practice is that researchers use their own data sets, and this behavior cumbers the objective evaluation of the proposed methods. In order to make the different approaches in graph based machine learning better comparable, the present paper aims at introducing a repository of graph data sets and corresponding benchmarks, covering a wide spectrum of different applications.",
isbn="978-3-540-89689-0"
}
```
---
许可证:未知
任务类别:
- 图机器学习(graph-ml)
---
# 数据集卡片:AIDS
## 目录
- [目录](#目录)
- [数据集描述](#数据集描述)
- [数据集概述](#数据集概述)
- [支持任务与排行榜](#支持任务与排行榜)
- [外部使用](#外部使用)
- [PyGeometric](#pygeometric)
- [数据集结构](#数据集结构)
- [数据属性](#数据属性)
- [数据字段](#数据字段)
- [数据划分](#数据划分)
- [附加信息](#附加信息)
- [许可证信息](#许可证信息)
- [引用信息](#引用信息)
- [贡献说明](#贡献说明)
## 数据集描述
- **[主页](https://wiki.nci.nih.gov/display/NCIDTPdata/AIDS+Antiviral+Screen+Data)**
- **论文:**:(详见引用信息)
- **排行榜:**:[Papers with code排行榜](https://paperswithcode.com/sota/graph-classification-on-aids)
### 数据集概述
`AIDS`数据集为经抗HIV活性验证的化合物数据集。
### 支持任务与排行榜
`AIDS`数据集适用于分子分类任务,该任务属于二分类任务,评估指标为带交叉验证的准确率。
## 外部使用
### PyGeometric
若需在PyGeometric中加载该数据集,请执行如下代码:
python
from datasets import load_dataset
from torch_geometric.data import Data
from torch_geometric.loader import DataLoader
dataset_hf = load_dataset("graphs-datasets/<mydataset>")
# 针对训练集(可根据需要替换为验证集或测试集)
dataset_pg_list = [Data(graph) for graph in dataset_hf["train"]]
dataset_pg = DataLoader(dataset_pg_list)
## 数据集结构
### 数据属性
| 属性 | 取值 |
|---|---|
| 数据规模 | 中等 |
| 图总数 | 1999 |
| 平均节点数 | 15.5875 |
| 平均边数 | 32.39 |
### 数据字段
每个文件的每一行对应一张图,包含以下字段:
- `node_feat`(列表:节点数 × 节点特征数):节点特征
- `edge_index`(列表:2 × 边数):构成边的节点对
- `edge_attr`(列表:边数 × 边特征数):对应上述边的特征信息
- `y`(列表:1 × 标签数):待预测的标签集合(此处标签数为1,取值为0或1)
- `num_nodes`(整数):该图的节点总数
### 数据划分
该数据集未进行预划分,建议通过交叉验证开展实验,其源自PyGeometric版本的数据集。
## 附加信息
### 许可证信息
该数据集的许可证类型未知。
### 引用信息
@inproceedings{Morris+2020,
title={TUDataset: A collection of benchmark datasets for learning with graphs},
author={Christopher Morris and Nils M. Kriege and Franka Bause and Kristian Kersting and Petra Mutzel and Marion Neumann},
booktitle={ICML 2020 Workshop on Graph Representation Learning and Beyond (GRL+ 2020)},
archivePrefix={arXiv},
eprint={2007.08663},
url={www.graphlearning.io},
year={2020}
}
@InProceedings{10.1007/978-3-540-89689-0_33,
author="Riesen, Kaspar and Bunke, Horst",
editor="da Vitoria Lobo, Niels and Kasparis, Takis and Roli, Fabio and Kwok, James T. and Georgiopoulos, Michael and Anagnostopoulos, Georgios C. and Loog, Marco",
title="IAM Graph Database Repository for Graph Based Pattern Recognition and Machine Learning",
booktitle="Structural, Syntactic, and Statistical Pattern Recognition",
year="2008",
publisher="Springer Berlin Heidelberg",
address="Berlin, Heidelberg",
pages="287--297",
abstract="In recent years the use of graph based representation has gained popularity in pattern recognition and machine learning. As a matter of fact, object representation by means of graphs has a number of advantages over feature vectors. Therefore, various algorithms for graph based machine learning have been proposed in the literature. However, in contrast with the emerging interest in graph based representation, a lack of standardized graph data sets for benchmarking can be observed. Common practice is that researchers use their own data sets, and this behavior cumbers the objective evaluation of the proposed methods. In order to make the different approaches in graph based machine learning better comparable, the present paper aims at introducing a repository of graph data sets and corresponding benchmarks, covering a wide spectrum of different applications.",
isbn="978-3-540-89689-0"
}