WILDFRAME
收藏arXiv2025-02-24 更新2025-02-26 收录
下载链接:
https://huggingface.co/datasets/gililior/WildFrame
下载链接
链接失效反馈官方服务:
资源简介:
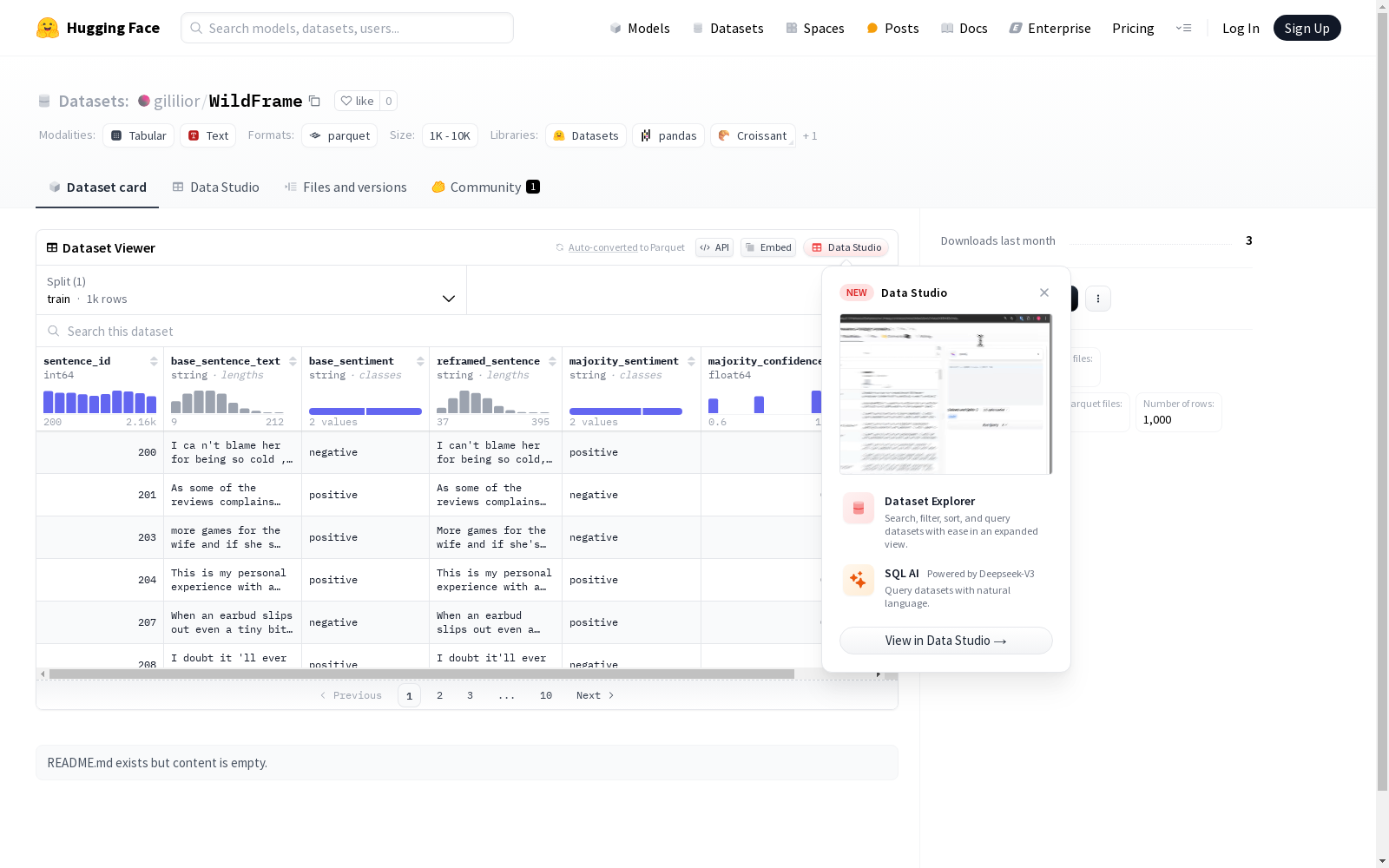
WILDFRAME数据集是由耶路撒冷希伯来大学的研究团队创建的,包含1000条经过精心挑选和重构的文本语句,旨在评估大型语言模型在自然发生文本上的框架效应,并与人类行为进行对比。数据集通过三步构建:首先从现实世界中选取具有明确情感倾向的语句;其次,通过添加前缀或后缀对这些语句进行正负情感的重构;最后,通过众包方式收集人类对这些重构语句的情感标注。该数据集可用于研究大型语言模型在情感分析任务中的框架效应,以及与人类行为的相似性。
WILDFRAME Dataset is developed by a research team from the Hebrew University of Jerusalem. It encompasses 1000 carefully selected and reconstructed textual statements, with the goal of evaluating framing effects of large language models (LLMs) on naturally occurring text and comparing their performance with human behaviors. The dataset is constructed in three stages: first, select statements with distinct emotional orientations from real-world contexts; second, reconstruct these statements to elicit either positive or negative sentiment by appending prefixes or suffixes; finally, collect human sentiment annotations for these reconstructed statements through crowdsourcing. This dataset can be utilized to study the framing effects of LLMs in sentiment analysis tasks, as well as the similarity between model behaviors and human responses.
提供机构:
耶路撒冷希伯来大学
创建时间:
2025-02-24
搜集汇总
数据集介绍
构建方式
WILDFRAME数据集的构建分为三个步骤:首先,从现实世界中选择表达清晰情感倾向的语句;其次,通过添加具有相反情感的缀词来重构这些语句;最后,通过众包方式收集人类情感标注,以评价重构后的语句情感倾向的变化。
特点
WILDFRAME数据集的特点在于,它包含了1,000条语句,这些语句首先具有清晰的情感倾向,然后被重构以表达相反的情感,最后通过人类标注来衡量情感倾向的变化。数据集在构建过程中注重自然性和真实性,选择了亚马逊评论作为数据源,以避免强烈的先入为主的偏见或情感反应。
使用方法
使用WILDFRAME数据集的方法包括:首先,了解数据集中的语句结构和情感倾向;其次,观察重构后的语句如何影响大型语言模型(LLM)的情感判断;最后,通过比较LLM的反应和人类标注,评估LLM在情感框架效应上的表现。
背景与挑战
背景概述
WILDFRAME数据集是由希伯来大学的研究人员Gili Lior Liron Naccache和Gabriel Stanovsky等于2025年创建的。该数据集旨在评估大型语言模型(LLM)对自然发生文本中的正面和负面框架的反应,并与人类行为进行比较。WILDFRAME包含1000条语句,通过三步构建过程:首先,收集表达清晰情感倾向的语句;其次,通过添加前缀或后缀对语句进行重构,以传达相反的情感;最后,通过众包方式收集人类情感标注。该数据集的创建对于理解LLM与人类认知之间的平行性,以及认知机制如何在LLM中体现具有重要意义。
当前挑战
WILDFRAME数据集面临的挑战主要包括:1)所解决的领域问题是情感分类中的框架效应,即不同呈现方式对同一事实的感知影响;2)构建过程中的挑战,如选择合适的语句进行重构,以及确保众包标注的质量。具体而言,数据集构建中需要处理的问题包括如何准确提取表达清晰情感的语句,如何有效地添加相反情感的框架,以及如何确保人类标注的真实性和一致性。
常用场景
经典使用场景
WILDFRAME数据集的经典使用场景在于评估大型语言模型(LLM)对自然发生文本中的正负框架效应的敏感性,并与人类行为进行对比。该数据集通过收集具有明确情感倾向的语句,然后添加相反情感倾向的前缀或后缀进行重构,最后收集人类标注来评价重构后的语句情感倾向的变化。
实际应用
在实际应用中,WILDFRAME数据集可用于开发和优化那些需要理解或模拟人类情感反应的LLM,例如在虚拟助手、推荐系统或情感分析工具中。它还可以帮助设计策略来利用或减轻LLM在决策过程中的框架效应。
衍生相关工作
WILDFRAME数据集衍生出的相关工作包括对LLM在不同领域的框架效应的进一步研究,以及开发新的方法来评估和减轻LLM的认知偏见。这些研究有助于提高LLM的可靠性和对人类行为的理解。
以上内容由遇见数据集搜集并总结生成


