An open dataset of multidimensional signals based on different speech patterns in pragmatic Mandarin
收藏DataCite Commons2026-04-02 更新2025-05-18 收录
下载链接:
https://www.scidb.cn/detail?dataSetId=00fead6aa5dc4f2cb03d98fd29c5aad4
下载链接
链接失效反馈官方服务:
资源简介:
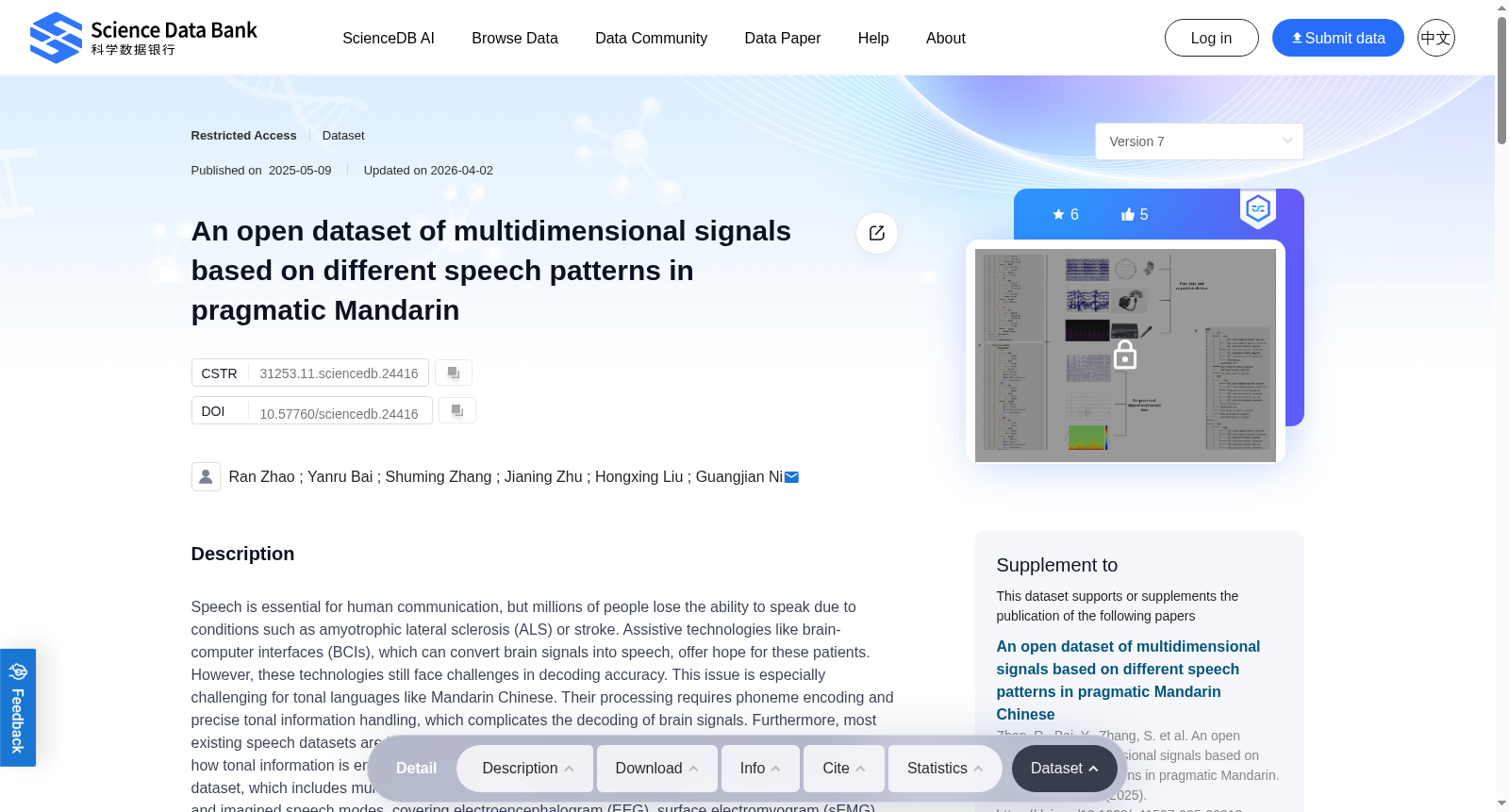
Speech is essential for human communication, but millions of people lose the ability to speak due to conditions such as amyotrophic lateral sclerosis (ALS) or stroke. Assistive technologies like brain-computer interfaces (BCIs), which can convert brain signals into speech, offer hope for these patients. However, these technologies still face challenges in decoding accuracy. This issue is especially challenging for tonal languages like Mandarin Chinese. Their processing requires phoneme encoding and precise tonal information handling, which complicates the decoding of brain signals. Furthermore, most existing speech datasets are based on Indo-European languages, which hinders our understanding of how tonal information is encoded in the brain. To address this, we introduce a comprehensive open dataset, which includes multimodal signals from 30 subjects using Mandarin Chinese across overt, silent, and imagined speech modes, covering electroencephalogram (EEG), surface electromyogram (sEMG), and speech recordings. Unlike many datasets that focus on a single speech mode, this one integrates three speech modes, providing a more comprehensive view of speech-related activity. Incorporating Mandarin facilitates an in-depth examination of the inner mechanisms that encode tonal variations and their interaction with motor and auditory speech representations. This is crucial for enhancing tonal language decoding in BCIs. Beyond BCI applications, this dataset lays a valuable groundwork for exploring the neural encoding of tonal languages, investigating tone-related brain dynamics, and improving assistive communication strategies. It supports cross-linguistic speech processing research and contributes to data-driven neural speech decoding technology innovations.
言语是人类沟通的核心媒介,但全球数百万人群因罹患肌萎缩侧索硬化症(amyotrophic lateral sclerosis, ALS)、脑卒中(stroke)等疾病而丧失言语能力。诸如脑机接口(brain-computer interfaces, BCIs)这类可将脑信号转换为言语输出的辅助技术,为这类患者带来了康复希望。然而此类技术在解码准确率层面仍存在诸多挑战,而对于汉语这类声调语言而言,该难题尤为突出。
声调语言的脑信号解码需同时兼顾音素编码与精准的声调信息处理,这极大地复杂化了脑信号解码流程。此外,现有主流言语数据集均基于印欧语系,这极大阻碍了学界对声调信息在大脑中编码机制的深入探究。
为应对这一挑战,本研究公开了一套多模态综合数据集:该数据集涵盖30名受试者使用汉语完成的三种言语模式(出声言语、无声唇语、想象言语)的多模态信号,具体包括脑电图(electroencephalogram, EEG)、表面肌电图(surface electromyogram, sEMG)以及言语录音数据。
与多数仅聚焦单一言语模式的数据集不同,本数据集整合了三种言语模式,能够更全面地呈现与言语相关的脑活动特征。纳入汉语语料,有助于深入解析声调变异的神经编码机制,及其与言语运动、听觉表征的交互作用,这对提升脑机接口声调语言解码性能至关重要。
除脑机接口应用场景外,本数据集还为探索声调语言的神经编码机制、研究声调相关脑动态特性、优化辅助沟通策略奠定了宝贵的研究基础。同时,其可为跨语言言语处理研究提供数据支撑,并助力数据驱动的神经言语解码技术创新。
提供机构:
Science Data Bank
创建时间:
2025-05-09
搜集汇总
数据集介绍
背景与挑战
背景概述
T-MSPD是一个包含30名受试者多模态信号的开放数据集,专注于汉语普通话在不同语音模式(公开、默读、想象)下的神经编码研究。该数据集特别针对声调语言处理,旨在推动脑机接口技术中声调解码的进步,并为跨语言语音处理研究提供宝贵资源。
以上内容由遇见数据集搜集并总结生成


