xwitter
收藏Hugging Face2025-04-26 更新2025-04-27 收录
下载链接:
https://huggingface.co/datasets/0xseatedro/xwitter
下载链接
链接失效反馈官方服务:
资源简介:
xwitter-100m推文数据集包含用户名、ID、推文内容、回复数、转发数、点赞数、引用数和时间戳等字段。数据集适用于文本分类和特征提取任务,大小介于10M到100M之间,遵循MIT许可。训练集包含约8808万条推文示例,总数据集大小约为20GB。
创建时间:
2025-04-26
搜集汇总
数据集介绍
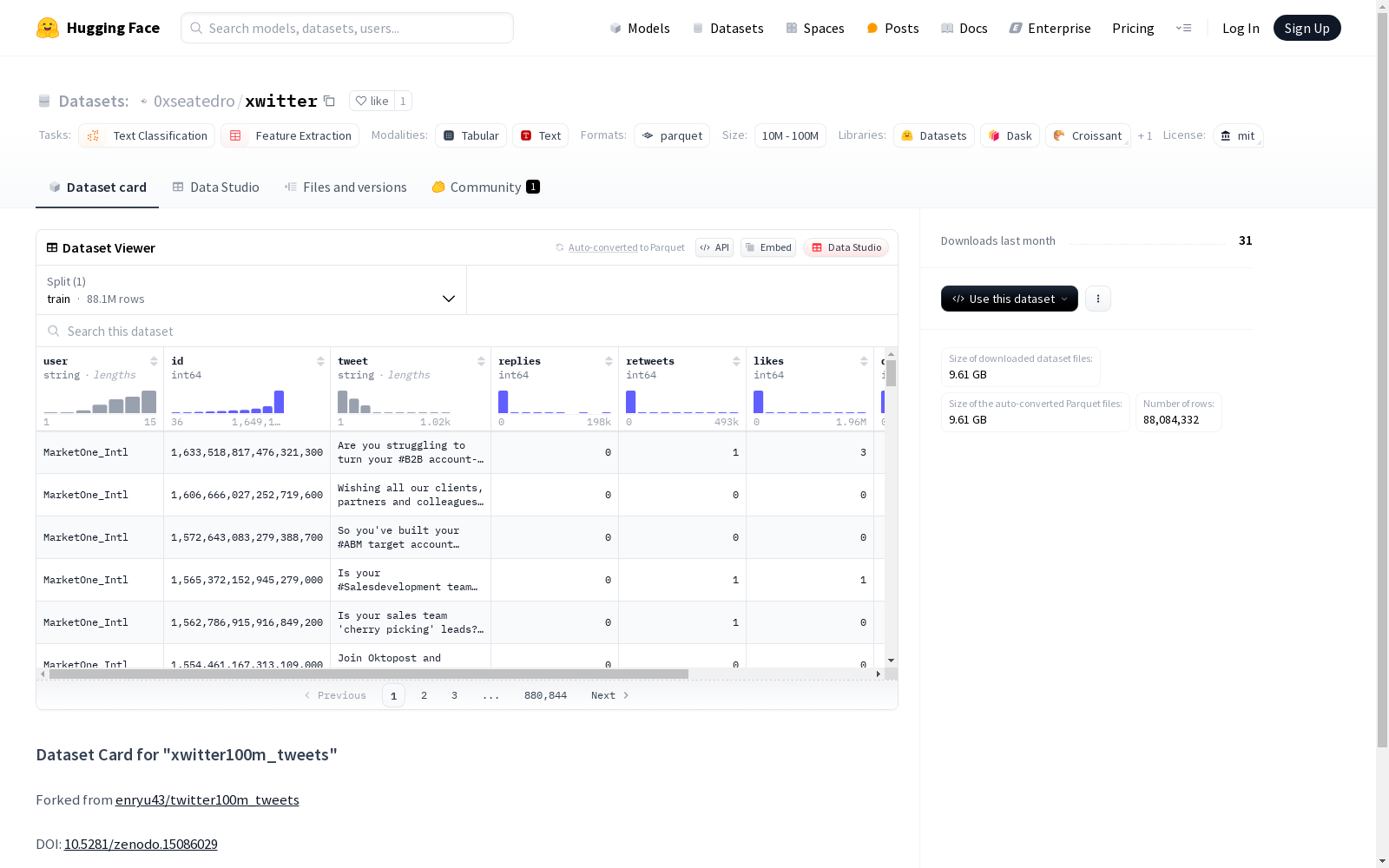
构建方式
xwitter数据集源自对enryu43/twitter100m_tweets数据集的衍生重构,其构建过程依托分布式爬虫技术对公开推文进行大规模采集。数据字段设计遵循社交媒体分析需求,涵盖用户标识、文本内容及互动指标等多维度信息,并通过严格的去标识化处理确保隐私合规。时间戳字段采用ISO 8601标准格式化,支持精确的时间序列分析。
特点
该数据集包含8800万条训练样本,完整记录了推文内容及社交互动指标,具有显著的规模优势。特征设计上同时保留文本语义特征与传播影响力量化指标,支持多模态分析任务。数据分布覆盖多样化的用户群体和话题领域,其MIT许可协议保障了学术与商业场景的灵活使用。
使用方法
研究者可通过HuggingFace数据集库直接加载该资源,适用于自然语言处理领域的预训练与微调任务。典型应用场景包括社交舆情分析、传播模式预测等,其中互动指标字段为影响力建模提供现成的监督信号。数据分片存储的设计优化了大规模处理的效率,建议配合分布式计算框架进行批处理操作。
背景与挑战
背景概述
xwitter数据集是基于enryu43/twitter100m_tweets的分支版本,由研究团队于2023年发布,旨在为自然语言处理领域提供大规模的社交媒体文本数据资源。该数据集收录了超过8800万条推文,涵盖用户信息、推文内容及互动指标等多维特征,其构建受到MIT许可证规范。作为社交网络分析的基准数据集,xwitter不仅支持文本分类和特征提取任务,还通过Zenodo平台实现了学术可追溯性,为研究在线社交行为、信息传播模式及情感分析等课题提供了重要数据支撑。
当前挑战
该数据集面临的核心挑战包括社交媒体文本固有的噪声问题,如非正式语法、多语言混杂及网络用语的不规范性,这对文本特征提取的准确性构成显著障碍。数据规模带来的存储与处理压力要求分布式计算框架的支持,而用户隐私保护需求则限制了原始元数据的完整公开。时间维度上的数据漂移现象导致模型需要持续更新以适应语言演变,平台API访问限制亦使得数据集难以实现动态扩展。
常用场景
经典使用场景
在社交媒体分析领域,xwitter数据集因其海量的推文数据和丰富的交互指标,成为研究信息传播模式的经典选择。研究者通过分析用户推文内容及其回复、转发、点赞等互动数据,能够深入挖掘社交网络中的信息扩散路径和影响力机制,为网络科学和计算社会科学提供重要实证基础。
衍生相关工作
基于xwitter数据集已衍生出多项开创性研究,包括社交机器人检测算法DeepBot、舆情预测模型TrendNet等。这些工作不仅推动了图神经网络在社交分析中的应用,其构建的基准测试集更成为领域内的评估标准。数据集还被纳入多个国际会议竞赛,持续促进算法创新和方法论进步。
数据集最近研究
最新研究方向
在社交媒体分析领域,xwitter数据集以其海量的推文数据和丰富的交互指标,成为研究信息传播模式和用户行为的重要资源。近期研究聚焦于利用该数据集探索虚假信息检测、情感分析以及社交网络影响力建模等前沿课题。特别是在全球重大事件如选举或公共卫生危机期间,学者们借助xwitter数据实时追踪舆论演变,为理解群体心理和社会动态提供了量化依据。该数据集的应用不仅推动了自然语言处理技术的进步,也为社会学、传播学等跨学科研究开辟了新的实证路径。
以上内容由遇见数据集搜集并总结生成


