KoCulture-Dialogues-v2
收藏Hugging Face2025-06-23 更新2025-06-24 收录
下载链接:
https://huggingface.co/datasets/huggingface-KREW/KoCulture-Dialogues-v2
下载链接
链接失效反馈官方服务:
资源简介:
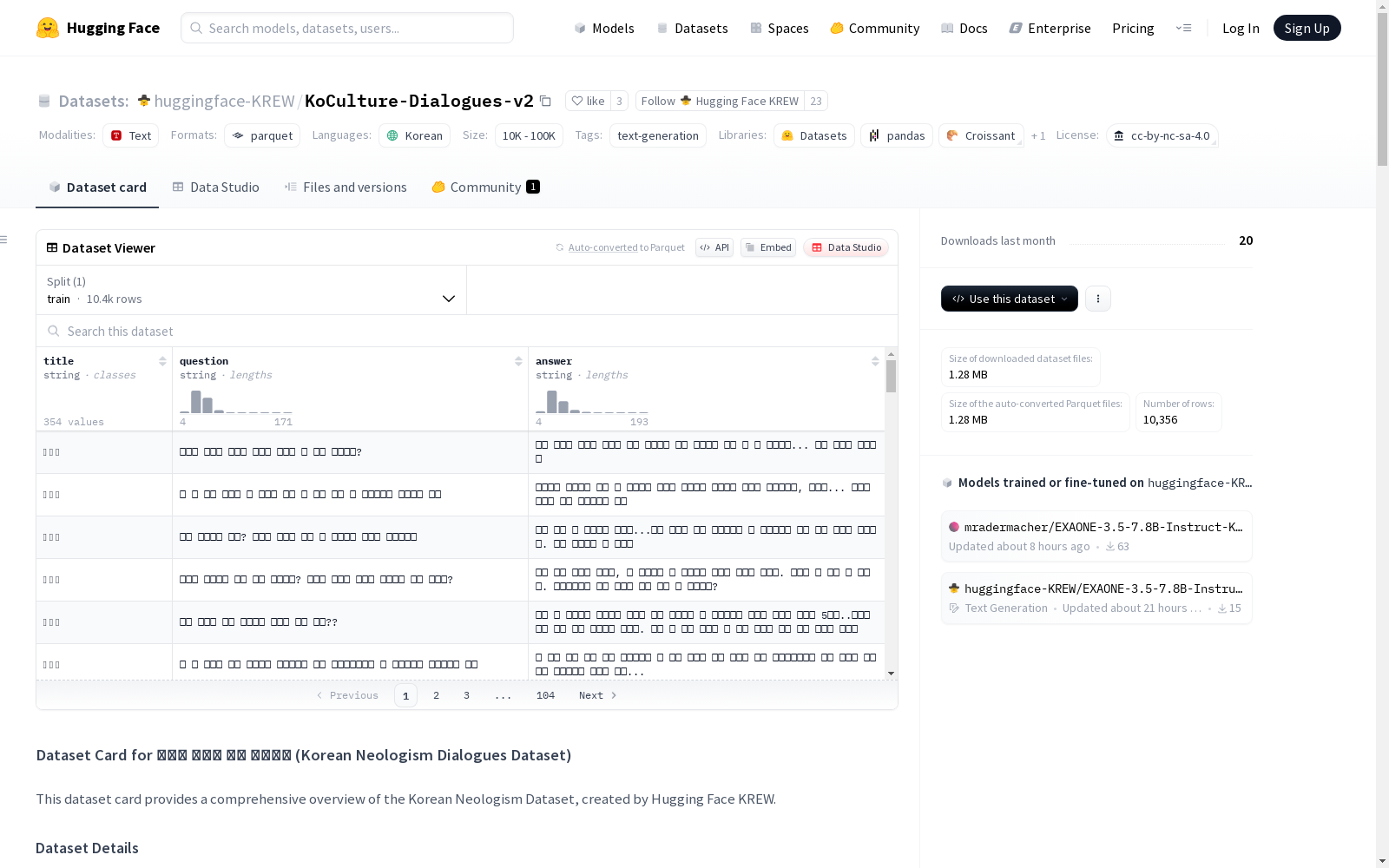
本数据集包含最新的韩国语新造词、流行语、梗等,旨在提升大型语言模型(LLM)在韩国语理解和生成方面的能力。数据集基于从Namuwiki和TrendAward等来源收集的原始数据,通过多个LLM生成初始数据,并由Hugging Face KREW成员进行审查和净化。数据集包含三个主要特征:标题(title)、问题(question)和答案(answer),分别代表核心新造词或梗的名称、可能使用这些新造词或梗的场景或对话起始部分,以及包含这些新造词或梗的回应内容。数据集遵循CC BY-NC-SA 4.0国际许可证,仅适用于非商业用途。
创建时间:
2025-06-23
搜集汇总
数据集介绍
构建方式
KoCulture-Dialogues-v2数据集的构建过程体现了对韩国网络文化的深度挖掘与系统整理。研究团队从Namuwiki和TrendAward等权威平台获取原始语料,运用先进的OCR技术处理图像文本,并采用Claude Sonnet 3.7、GPT-4o等多模态大模型进行数据增强。通过严谨的人工审核流程,参与者对生成内容进行语义校验和文化适配性调整,最终形成包含3456条高质量对话样本的数据集,每条数据均包含标题、问题、回答三个结构化字段,完整呈现韩国新造词在不同语境下的使用范式。
特点
该数据集最显著的特征在于其对韩国网络流行语的时效性和文化特异性捕捉。数据集精准收录了如'추구미'、'어쩔티비'等典型新造词,通过精心设计的问答对展现这些词汇在真实社交场景中的动态应用。每个词条平均配备多个语境案例,既包含文字表面的语义表达,也蕴含韩国特有的网络亚文化内涵。数据采用CC BY-NC-SA 4.0协议开放,在保证学术研究可用性的同时,严格限制商业用途和衍生作品的授权范围。
使用方法
研究人员可将该数据集直接用于提升大语言模型的韩语文化理解能力,特别是在处理网络新生词汇方面具有独特价值。使用时应遵循分层抽样原则,将训练集用于模型微调时注意保持语境完整性。建议配合韩国传统语料库进行对比研究,以区分网络用语与标准韩语的语法差异。对于应用开发,可提取问答对构建韩国特色聊天机器人的对话模板,但需定期更新以应对网络用语的快速演变特性。所有使用场景都必须严格遵守非商业用途协议,并明确标注数据来源。
背景与挑战
背景概述
KoCulture-Dialogues-v2数据集由Hugging Face KREW团队于2025年构建,旨在解决大语言模型(LLM)在韩语新词理解和生成方面的局限性。该数据集聚焦于韩国网络文化中的新兴流行语、网络迷因等动态语言现象,通过整合Namuwiki和TrendAward等来源的原始数据,并利用Claude、GPT-4等先进模型进行数据增强,最终由专业团队人工校验完成。作为首个系统化收录韩语网络流行文化的对话数据集,它不仅填补了韩语自然语言处理领域的数据空白,更为提升AI模型对韩语文化语境的理解提供了重要资源。
当前挑战
该数据集面临双重挑战:在领域问题层面,韩语新词具有时效性强、语义变化快的特点,要求模型具备动态语义捕捉能力;网络流行文化特有的隐晦表达和亚文化圈层差异也给语义理解带来困难。在构建过程中,数据收集面临网络非结构化数据清洗难题,需开发专门的OCR处理流程;质量管控方面需平衡语言创意性与内容规范性,通过多轮人工校验消除攻击性内容;此外还需解决CC BY-NC-SA许可下数据来源合规性问题。
常用场景
经典使用场景
在自然语言处理领域,KoCulture-Dialogues-v2数据集为研究韩国流行文化和语言变迁提供了重要资源。该数据集通过收录韩国网络社区中的新造词、流行语和网络迷因,构建了包含3456组对话样本的高质量语料库。研究人员可以借助该数据集深入分析韩国年轻一代的语言使用习惯,探索网络文化对语言演化的影响机制。数据集采用title-question-answer的三元组结构,能够完整呈现特定流行语在不同语境下的使用方式。
实际应用
在实际应用层面,该数据集显著提升了韩国语智能服务的文化适应性。基于该数据训练的对话系统能够准确理解'폼 미쳤다'等流行表达,使AI助手在韩国本土市场的交互更加自然流畅。教育科技领域可利用该数据集开发韩国语学习应用,帮助外国学习者掌握最新的生活用语。内容审核系统也可借助数据集识别网络社区中的新兴表达,区分创意用语与潜在有害内容。数据集遵循CC BY-NC-SA协议,确保在非商业场景下的广泛传播与应用。
衍生相关工作
围绕该数据集已产生多项创新研究。部分学者将其与BERTopic等主题建模技术结合,建立了韩国网络文化的分类体系;另有研究利用对比学习框架,基于该数据集开发了专门识别新造词的KoSBERT模型。在跨文化研究领域,有团队将该数据集与日本网络用语库进行对比分析,揭示了东北亚地区网络语言的传播规律。数据集还促进了Human-in-the-loop标注方法的发展,其多阶段清洗流程已成为处理网络语料的典范。
以上内容由遇见数据集搜集并总结生成


