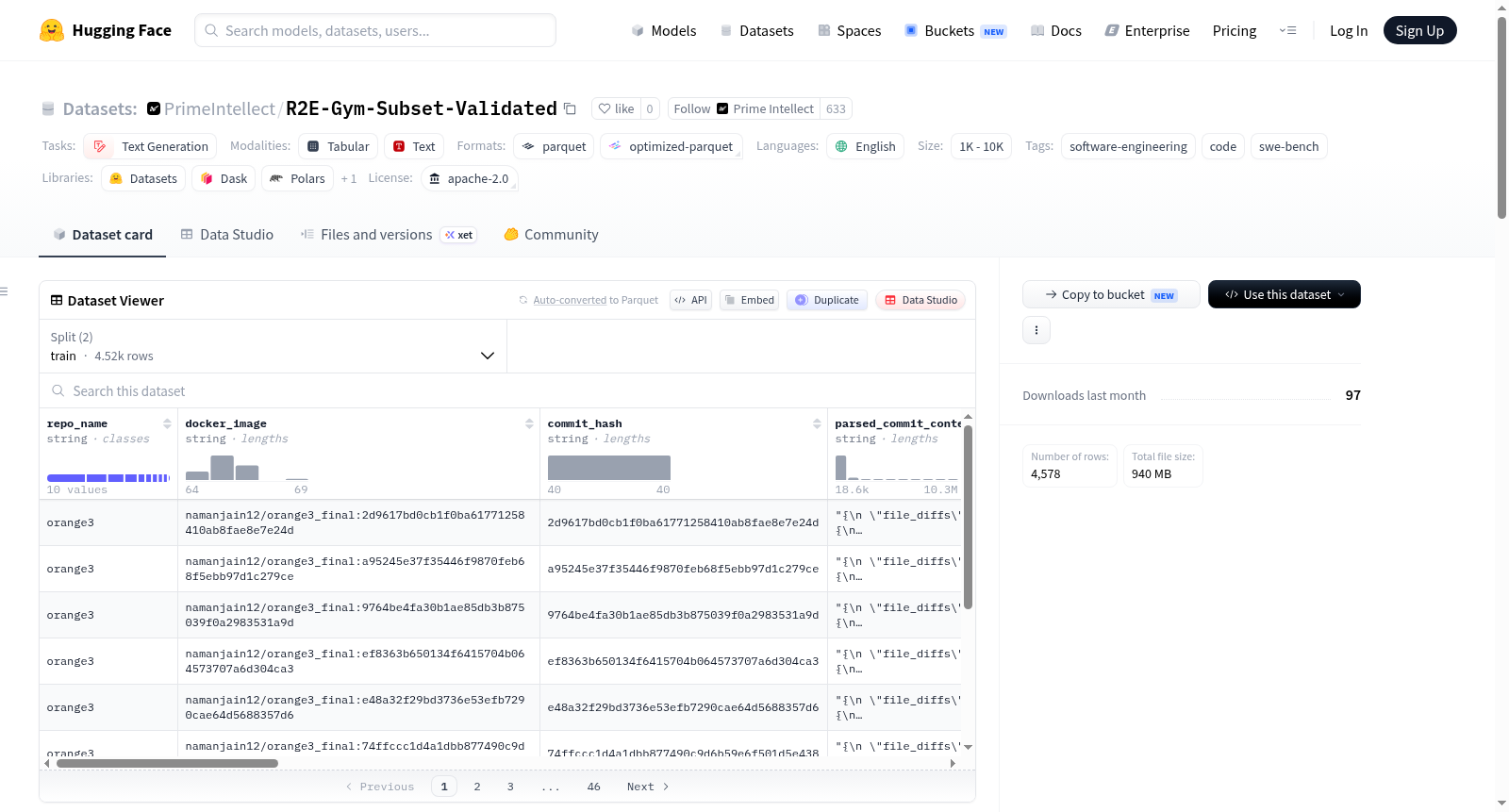
PrimeIntellect/R2E-Gym-Subset-Validated
收藏Hugging Face2026-04-30 更新2026-05-03 收录
下载链接:
https://hf-mirror.com/datasets/PrimeIntellect/R2E-Gym-Subset-Validated
下载链接
链接失效反馈官方服务:
资源简介:
R2E-Gym-Subset-Validated是R2E-Gym/R2E-Gym-Subset的一个经过金补丁验证的子集。训练集包含4522行(占总数的98.78%),这些行已验证可以进行端到端评分:应用金补丁,运行每行图像中内置的/testbed/run_tests.sh,并检查解析的测试结果是否与expected_output_json匹配。丢弃的56行(1.22%)是由于金补丁无法应用、测试无法运行或测试结果与预期不一致。数据集主要用于软件工程和代码生成任务,特别适用于那些需要精确测试结果匹配的场景。
R2E-Gym-Subset-Validated is a gold-patch–validated subset of R2E-Gym/R2E-Gym-Subset. The train split contains 4522 rows (98.78% of the total) that have been verified to be scored end-to-end: applying the gold patch, running the upstream /testbed/run_tests.sh baked into the rows image, and checking that the parsed test outcomes match expected_output_json. The dropped 56 rows (1.22%) are those that fail this precondition deterministically. The dataset is primarily used for software engineering and code generation tasks, especially those requiring exact test outcome matching.
提供机构:
PrimeIntellect
搜集汇总
数据集介绍
构建方式
R2E-Gym-Subset-Validated 是源自 R2E-Gym-Subset 的一个高质量子集,通过严格的黄金补丁验证流程构建。该流程对原始训练集的 4578 条数据逐一执行以下步骤:首先从每条数据对应的 Docker 镜像中启动全新沙箱环境;其次根据解析的提交内容重建黄金补丁并应用;随后运行沙箱内预置的标准评估脚本;最后解析 pytest 输出的测试摘要,将每个测试用例的通过/失败/错误状态与预期输出进行精确比对。对于初始验证失败的样本,研究团队进行了最多 10 次重试以区分偶然波动与确定性失败,最终仅保留在 10 次重试中均无法通过的 56 条数据进入 dropped 分片。
特点
该数据集最显著的特点是将原始子集中 98.78% 的样本(4522 条)确认为可端到端评分的有效用例。黄金补丁的应用、测试脚本的执行与结果解析均能在沙箱环境中完整复现,从而保障了基于该数据集的强化学习智能体评分结果的可靠性。被剔除的 56 条数据主要源于两大类型的问题:一是对网络或时间敏感的测试(如 aiohttp 和 tornado 项目中的连接超时测试、端口分配测试),这些测试在沙箱中本身就会随机失败;二是由于基础镜像更新导致的漂移现象,即部分测试因依赖库版本变化而意外通过,与预先标注的预期结果不符。
使用方法
用户可通过 HuggingFace Datasets 库轻松加载该数据集的训练分片与剔除分片。加载方式为 `load_dataset("PrimeIntellect/R2E-Gym-Subset-Validated")`,默认返回经过验证的 4522 条训练数据;若要获取被剔除的 56 条记录,需显式指定 `split="dropped"`。该数据集的模式与原始 R2E-Gym-Subset 完全一致,所有字段描述和来源信息均可参考原始数据集文档。此外,数据集中还附带了 `metadata/filtered_drops.json` 文件,详细记录了每个被剔除提交的仓库名称及主要失败原因,便于用户进行深入分析和选择性恢复。
背景与挑战
背景概述
在软件工程与人工智能的交叉领域,自动化代码修复与系统可靠性评估已成为关键研究方向。R2E-Gym-Subset-Validated数据集由PrimeIntellect研究团队于2024年创建,旨在为强化学习驱动的软件工程智能体提供经过严格验证的交互式训练环境。该数据集基于原始R2E-Gym-Subset构建,通过端到端的补丁验证流程,筛选出4522个可确保金补丁正确应用、测试脚本稳定运行且结果与预期输出完全匹配的代码仓库样本。数据集的核心价值在于解决了传统仿真环境中因测试不稳定、网络依赖或库版本漂移导致的分数不可比问题,为自动化程序修复与基于智能体的代码测试研究提供了高保真、可量化评估的基准平台,显著提升了软件工程领域实验结果的可靠性与可复现性。
当前挑战
该数据集所应对的领域挑战在于自动化代码修复与评估过程中的结果不可靠性问题:现有仿真环境常因测试的随机性(如网络超时测试)或环境漂移(如底层依赖库变更)导致智能体的评估分数失去意义,阻碍对模型真实性能的客观比较。在构建过程中,研究团队面临了双重技术挑战:其一,需从4578个原始样本中精准识别56个确定性失效的行,这些失效主要源于网络/时序敏感测试(如aiohttp和tornado项目占39例)以及数据集漂移导致的预期输出与实际结果不匹配;其二,需在保证高并发(200并发任务)与有限重试(10次)的前提下,设计严格的验证流水线以区分偶发性失败与确定性失效,最终将98.78%的有效样本保留为训练集,而将失败的样本独立存放以确保数据处理的透明性与可审计性。
常用场景
经典使用场景
在软件工程与人工智能的交叉领域中,R2E-Gym-Subset-Validated数据集扮演着代码智能体评估基准的核心角色。该数据集精选自R2E-Gym-Subset,经过严格的金补丁验证流程,确保每一行数据都能端到端地完成测试执行与结果比对。其经典使用场景在于为基于大语言模型的自动程序修复、代码生成及代码理解系统提供一个可靠且可复现的验证环境。研究人员可利用该数据集训练和评估智能体在真实软件仓库上应用补丁、执行测试并判断结果一致性的能力,从而衡量模型在复杂软件工程任务中的表现。这种从补丁应用到测试验证的闭环设计,使其成为评估自主编码代理性能的标准测试床。
实际应用
在实际工程应用中,R2E-Gym-Subset-Validated数据集为提升软件开发自动化水平提供了坚实支撑。企业级应用场景包括自动化代码审查系统、持续集成中的缺陷修复助手,以及智能编程助手的回归测试验证模块。例如,在DevOps流水线中,可利用该数据集训练的智能体自动定位补丁问题并验证修复效果,减少人工代码审查的重复劳动。开发团队能够借此快速评估不同的代码修复策略在真实仓库中的有效程度,从而择优部署。此外,该数据集还服务于在线编程教育平台,用于自动批改学生提交的代码补丁并给出精准反馈,大幅提升教学效率。其高可靠性使得从研究到落地的转化成本显著降低。
衍生相关工作
该数据集衍生了一系列具有影响力的经典工作。最直接的是其上游数据集R2E-Gym-Subset,为自动化评估代码智能体提供了大规模的基础数据来源。验证方法论本身催生了关于代码智能体评估可靠性的研究,包括对评估指标的稳健性分析以及沙盒环境对测试结果影响因子的探究。此外,基于该数据集的Gold-Patch验证流程,有学者提出了改进的评分器设计,允许对测试结果进行更灵活的模糊匹配而非严格精确匹配,从而保留了某些因环境漂移而本应通过的数据行。还有工作围绕该数据集的缺陷分布(如aiohttp和tornado中的网络敏感测试)展开,探索了如何构建对时序和网络不敏感的自适应评估场景。这些衍生工作共同推动了代码智能体评估从粗放式向精细化、系统化的方向演进。
以上内容由遇见数据集搜集并总结生成


