pixparse/cc12m-wds
收藏Hugging Face2023-12-15 更新2024-03-04 收录
下载链接:
https://hf-mirror.com/datasets/pixparse/cc12m-wds
下载链接
链接失效反馈官方服务:
资源简介:
---
license: other
license_name: conceptual-12m
license_link: LICENSE
task_categories:
- image-to-text
size_categories:
- 10M<n<100M
---
# Dataset Card for Conceptual Captions 12M (CC12M)
## Dataset Description
- **Repository:** [Conceptual 12M repository](https://github.com/google-research-datasets/conceptual-12m)
- **Paper:** [Conceptual 12M: Pushing Web-Scale Image-Text Pre-Training To Recognize Long-Tail Visual Concepts](https://arxiv.org/abs/2102.08981)
- **Point of Contact:** [Conceptual Captions e-mail](mailto:conceptual-captions@google.com)
### Dataset Summary
Conceptual 12M (CC12M) is a dataset with 12 million image-text pairs specifically meant to be used for visionand-language pre-training.
Its data collection pipeline is a relaxed version of the one used in Conceptual Captions 3M (CC3M).
### Usage
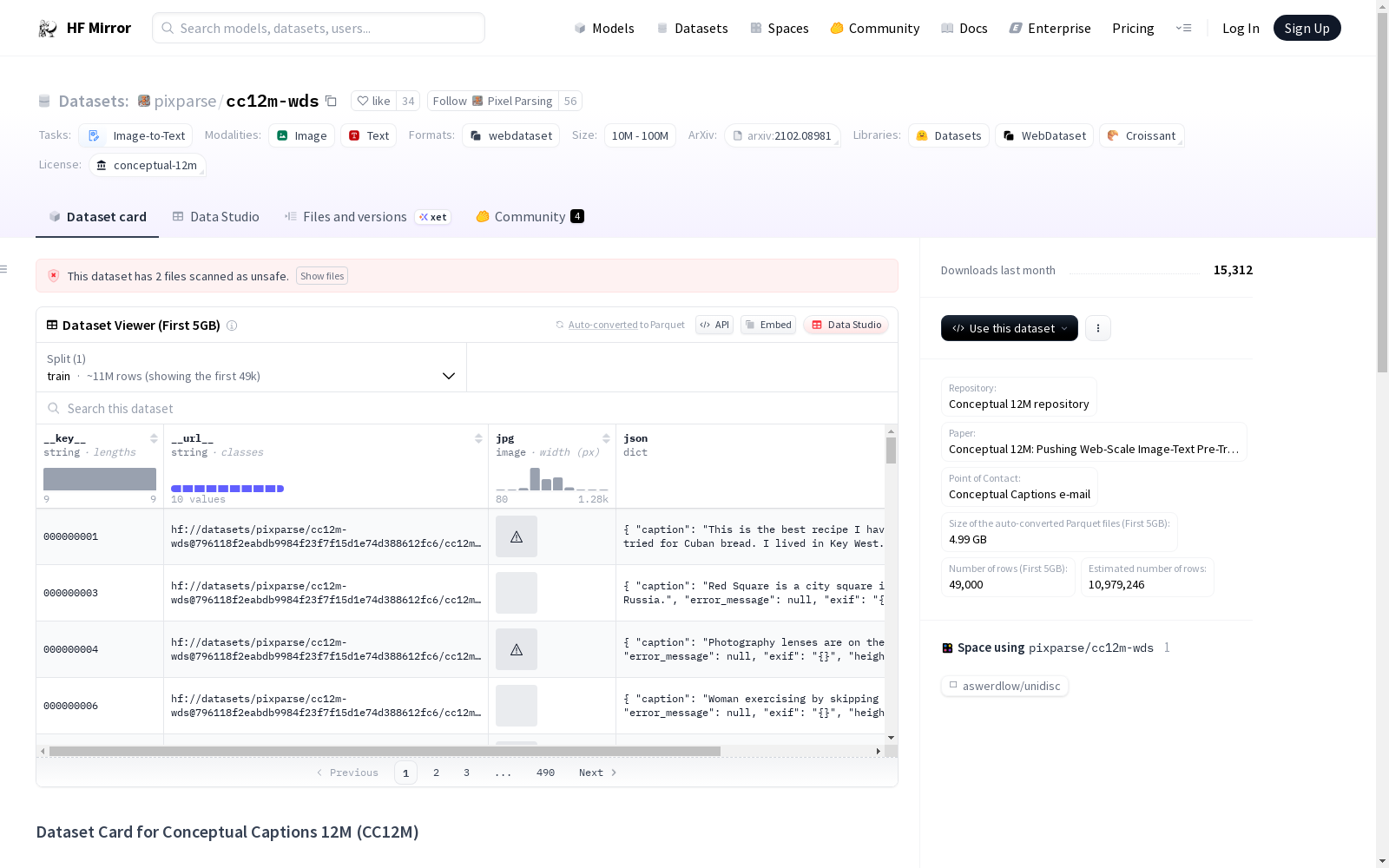
This instance of Conceptual Captions is in [webdataset](https://github.com/webdataset/webdataset/commits/main) .tar format. It can be used with webdataset library or upcoming releases of Hugging Face `datasets`.
...More Detail TBD
### Data Splits
This dataset was downloaded using img2dataset. Images resized on download if shortest edge > 512 to shortest edge = 512.
#### Train
* `cc12m-train-*.tar`
* Downloaded on 2021/18/22
* 2176 shards, 10968539 samples
## Additional Information
### Dataset Curators
Soravit Changpinyo, Piyush Sharma, Nan Ding and Radu Soricut.
### Licensing Information
The dataset may be freely used for any purpose, although acknowledgement of
Google LLC ("Google") as the data source would be appreciated. The dataset is
provided "AS IS" without any warranty, express or implied. Google disclaims all
liability for any damages, direct or indirect, resulting from the use of the
dataset.
### Citation Information
```bibtex
@inproceedings{changpinyo2021cc12m,
title = {{Conceptual 12M}: Pushing Web-Scale Image-Text Pre-Training To Recognize Long-Tail Visual Concepts},
author = {Changpinyo, Soravit and Sharma, Piyush and Ding, Nan and Soricut, Radu},
booktitle = {CVPR},
year = {2021},
}
```
license: 其他
license_name: conceptual-12m
license_link: LICENSE
task_categories:
- 图像到文本
size_categories:
- 1000万<样本量<1亿
# 概念性字幕1200万(CC12M)数据集卡片
## 数据集说明
- **仓库地址**:[Conceptual 12M 仓库](https://github.com/google-research-datasets/conceptual-12m)
- **相关论文**:[概念性字幕1200万:推进网页级图像-文本预训练以识别长尾视觉概念](https://arxiv.org/abs/2102.08981)
- **联络方式**:[概念性字幕官方邮箱](mailto:conceptual-captions@google.com)
### 数据集概述
概念性字幕1200万(CC12M)是一个包含1200万图像-文本对的数据集,专为视觉-语言预训练任务设计。其数据收集流程是概念性字幕300万(CC3M)所使用流程的简化版本。
### 使用方式
本版本的概念性字幕数据集采用[webdataset](https://github.com/webdataset/webdataset/commits/main)格式的.tar打包文件。可通过webdataset库或即将推出的拥抱脸(Hugging Face)`datasets`库进行使用。
...更多细节待补充
### 数据划分
本数据集通过img2dataset工具下载。下载过程中,若图像最短边大于512像素,则将其最短边调整为512像素。
#### 训练集
* `cc12m-train-*.tar`
* 下载时间:2021/18/22
* 共2176个分片,包含10968539条样本
## 补充信息
### 数据集维护者
Soravit Changpinyo, Piyush Sharma, Nan Ding and Radu Soricut.
### 许可信息
本数据集可免费用于任何用途,若能注明谷歌有限责任公司(Google LLC,简称"谷歌")为数据来源,将不胜感激。本数据集按"现状"提供,不附带任何明示或暗示的担保。谷歌对因使用本数据集所导致的任何直接或间接损害不承担任何责任。
### 引用信息
bibtex
@inproceedings{changpinyo2021cc12m,
title = {{Conceptual 12M}: Pushing Web-Scale Image-Text Pre-Training To Recognize Long-Tail Visual Concepts},
author = {Changpinyo, Soravit and Sharma, Piyush and Ding, Nan and Soricut, Radu},
booktitle = {CVPR},
year = {2021},
}
提供机构:
pixparse
原始信息汇总
数据集卡片 for Conceptual Captions 12M (CC12M)
数据集描述
- 数据集概述: Conceptual 12M (CC12M) 是一个包含1200万张图像-文本对的数据集,专门用于视觉和语言预训练。其数据收集流程是Conceptual Captions 3M (CC3M)的一个宽松版本。
使用方法
该版本的Conceptual Captions以webdataset .tar格式提供。可以使用webdataset库或即将发布的Hugging Face datasets进行使用。
数据分割
该数据集使用img2dataset下载,下载时如果最短边大于512,则调整为最短边为512。
训练集
cc12m-train-*.tar- 下载日期:2021/18/22
- 2176个分片,10968539个样本
附加信息
数据集策展人
Soravit Changpinyo, Piyush Sharma, Nan Ding 和 Radu Soricut。
许可信息
该数据集可自由用于任何目的,尽管对Google LLC ("Google")作为数据源的认可将受到赞赏。数据集以“AS IS”形式提供,没有任何明示或暗示的保证。Google不承担使用该数据集导致的任何直接或间接损害的责任。
引用信息
bibtex @inproceedings{changpinyo2021cc12m, title = {{Conceptual 12M}: Pushing Web-Scale Image-Text Pre-Training To Recognize Long-Tail Visual Concepts}, author = {Changpinyo, Soravit and Sharma, Piyush and Ding, Nan and Soricut, Radu}, booktitle = {CVPR}, year = {2021}, }
搜集汇总
数据集介绍
构建方式
Conceptual 12M(CC12M)数据集的构建,采取了对Conceptual Captions 3M(CC3M)数据收集流程的放松版本。该数据集包含1200万张图像-文本对,旨在用于视觉与语言预训练。数据采集过程中,图像与文本的配对基于互联网上的大规模无监督收集,进而形成了一个适用于深度学习模型的丰富资源库。
特点
该数据集的特点在于其大规模的图像-文本对,覆盖了广泛的主题和视觉概念,特别是那些尾部分布的长尾视觉概念。CC12M不仅继承了CC3M的优势,而且在数据量和多样性上有所增强,为视觉与语言任务提供了更为全面的预训练素材。此外,其遵循的开放许可使得研究界可以自由使用这一资源,促进了学术研究的开放性和共享性。
使用方法
使用CC12M数据集时,用户需通过webdataset格式或即将发布的Hugging Face datasets库来加载.tar格式的数据。该数据集已被划分为训练集,并可在下载时对图像大小进行调整以适应不同的处理需求。详细的加载和使用方法可参照相关库的文档说明,确保数据的高效利用和模型的准确训练。
背景与挑战
背景概述
在视觉与语言预训练领域,Conceptual 12M(CC12M)数据集的构建标志着对大规模图像-文本对资源的进一步拓展。该数据集由谷歌研究团队于2021年推出,主要研究人员包括Soravit Changpinyo、Piyush Sharma、Nan Ding和Radu Soricut。CC12M旨在推动对长尾视觉概念识别的图像-文本预训练,其数据采集流程在Conceptual Captions 3M(CC3M)的基础上进行了适当放松。该数据集对视觉与语言领域的模型训练与算法研究产生了重要影响,成为领域内重要的资源之一。
当前挑战
CC12M数据集在构建过程中面临的挑战主要包括:如何在大规模数据采集时保持数据质量与多样性,以及如何在预训练中有效识别并处理长尾视觉概念。此外,数据集的应用挑战体现在如何利用这些图像-文本对进行高效的视觉概念学习,并在此基础上提升模型的泛化能力。在数据集的实际应用中,研究者还需克服数据许可与版权问题,确保数据使用的合规性。
常用场景
经典使用场景
在当前的计算机视觉与自然语言处理交叉领域,Conceptual 12M (CC12M) 数据集以其庞大的图像-文本对资源,成为推动视觉概念预训练任务的重要基石。该数据集的经典使用场景在于,研究人员通过其提供的12百万图像-文本对,进行深度学习模型的训练,旨在实现图像内容与自然语言描述的有效对应,进而提升模型在图像描述生成、视觉问答等任务上的表现。
实际应用
在实际应用中,CC12M 数据集的图像-文本预训练模型已被广泛应用于社交媒体内容审核、智能医疗图像分析、自动驾驶系统中的环境理解等多个领域。这些模型能够准确识别并描述图像内容,为智能决策提供了重要的数据支持,极大地推动了人工智能技术在现实世界的应用。
衍生相关工作
基于CC12M数据集的研究成果,已经衍生出一系列相关的工作,如针对特定领域的细粒度图像识别、跨模态检索任务中的模型改进等。这些研究不仅深化了对视觉与语言交互机制的理解,也推动了相关技术在多媒体处理、机器翻译等领域的融合与创新。
以上内容由遇见数据集搜集并总结生成


