sql-grimoire
收藏Hugging Face2024-11-20 更新2024-12-12 收录
下载链接:
https://huggingface.co/datasets/data-maki/sql-grimoire
下载链接
链接失效反馈官方服务:
资源简介:
Grimoire of SQL 是一个综合性的数据集,专门用于训练和评估文本到SQL模型。它整合并增强了多个现有数据集,包括 Spider、BirdBench 和 Gretel,通过纠正错误、优化自然语言查询和验证SQL查询的可运行性。该数据集特别设计用于支持像GPT-4及其变体的高质量微调,确保强大的SQL生成能力。数据集的每个示例包括数据集来源、数据库ID、修正后的用户查询、原始查询(如果可用)、修正后的可运行SQL查询、相关上下文、示例行和基于查询复杂度的难度评级。数据集强调了自然语言查询的精细化和SQL查询的验证,并提供了GPT-4o-mini生成的解释以增强可解释性。该数据集适用于微调文本到SQL模型、基准测试SQL生成性能以及开发需要强大查询翻译功能的SQL生成工具。
创建时间:
2024-11-20
原始信息汇总
Grimoire of SQL 数据集概述
概述
Grimoire of SQL 是一个专为训练和评估文本到SQL模型而设计的综合数据集。它整合并增强了多个现有数据集,包括 Spider、BirdBench 和 Gretel,通过修正错误、优化自然语言查询和验证SQL查询的可运行性。该数据集特别设计用于支持GPT-4及其变体的高质量微调,确保强大的SQL生成能力。
数据集组成
-
数据集规模:
- 样本数量: ~85k
-
数据来源:
- 修正后的查询和SQL来自 Spider、BirdBench(大量修正)和 Gretel。
- 使用 GPT-4o-mini 生成的解释以提高可解释性。
特征
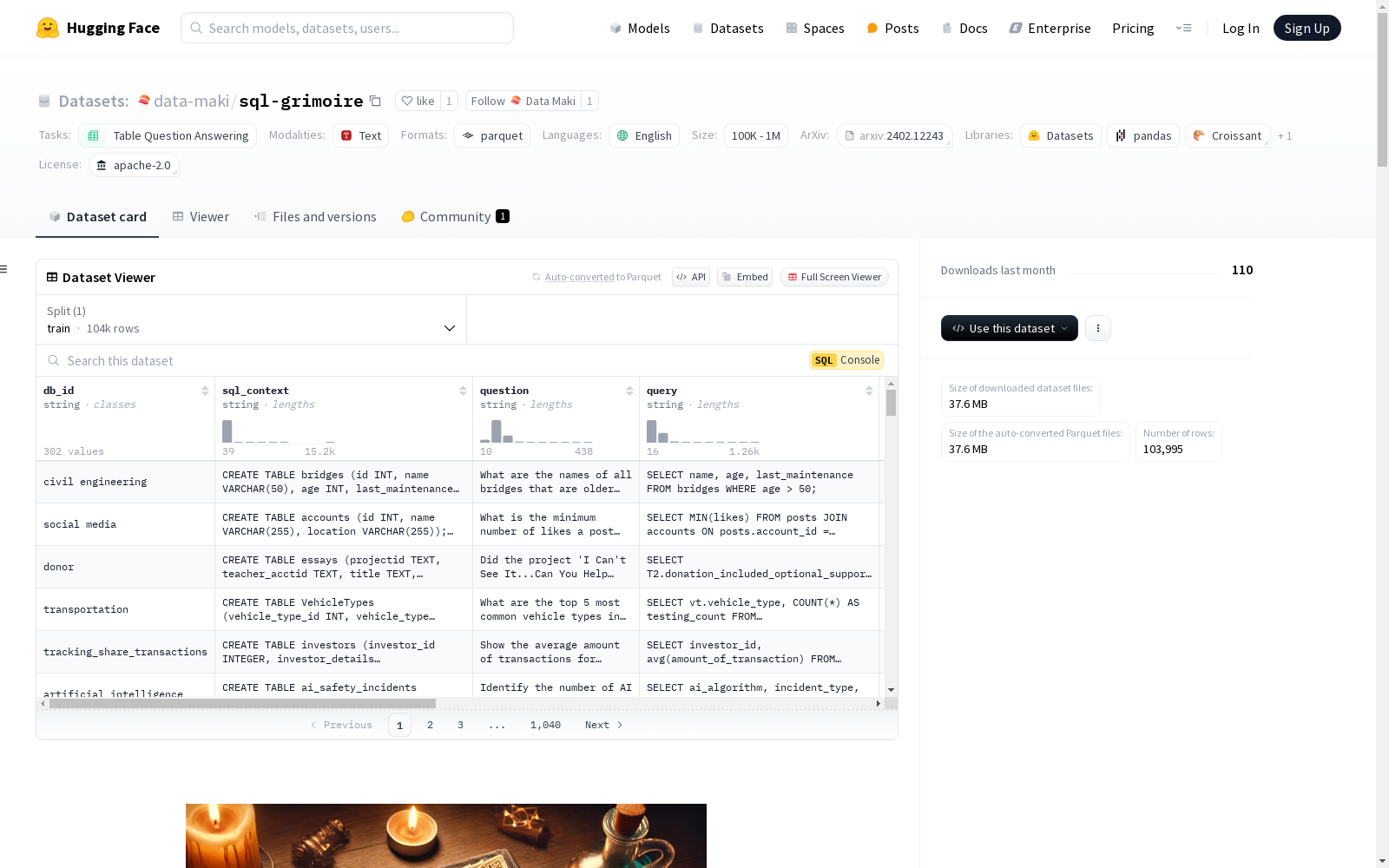
Grimoire of SQL 数据集中的每个样本包括:
dataset: 包含该样本的数据集(spider, birdbench, gretel)db_id: 对应SQL查询的数据库ID。request: 修正后的自然语言用户查询(英文)。original_request: 修正前的原始查询(如果可用)。sql: 修正后的可运行SQL查询。context: 生成SQL查询的相关上下文,包括表创建SQL命令。example_rows: 对应数据库表的示例行,以更好地理解查询。difficulty: 基于查询复杂度的难度评级(如简单、中等、困难)。
数据集亮点
- 优化后的自然语言查询: 所有查询都经过仔细审查和修正,以避免语法错误和歧义。
- 验证后的SQL查询: 每个SQL语句都经过测试,确保其在对应数据库中的语法正确性和可执行性。
- 增强的可解释性: 使用GPT-4o-mini生成的解释,提供查询到SQL生成过程的洞察。
应用
- 微调文本到SQL模型,用于自然语言数据库查询。
- 使用真实世界数据集进行SQL生成性能基准测试。
- 开发需要强大查询翻译功能的SQL生成工具。
数据清理
Grimoire of SQL 强调数据质量,解决了流行文本到SQL基准测试中常见的数据问题。主要目标是为模型训练和评估提供可靠的基础,减少源数据集中错误引起的噪声。
BirdBench 和 Spider 中的问题
BirdBench 和 Spider 是两个最广泛使用的文本到SQL基准测试,其训练和测试集中包含大量错误。通过使用大型语言模型(LLMs)和手动验证,进行了以下修正:
- 约 30% 的 BirdBench 训练集包含 错误的SQL。
- 测试集样本也包含错误(基于前20个样本的审查,4个包含错误的SQL)。
- 许多自然语言查询存在 语法错误 或使用 非标准英语,不适合通用训练。
清理方法
为解决这些问题,采取了以下步骤:
-
SQL修正:
- 所有SQL语句都经过审查和修正,确保语法准确性和逻辑正确性。
- 查询在对应数据库中进行测试,确保可执行性。
-
查询优化:
- 使用 GPT-4o 重写存在语法错误或非标准表达的自然语言查询。
- 修正后的查询存储在
request列中,原始查询(如果修改)保留在original_request列中,以保持透明度。
-
数据集特定说明:
- BirdBench: 由于数据噪声,进行了大量修正。查询和SQL示例被修正以符合数据库结构和自然语言规范。
- Spider: 需要大量修正。
- Gretel: 需要少量修正;但存在一些基本逻辑问题。
一致性增强
为确保数据集的一致性:
- 所有查询,无论其来源,都遵循标准英语语法和表达。
- 任何存在模糊表达或意图不清的问题都被澄清和重写。
通过解决这些问题,Grimoire of SQL 提供了一个高质量的数据集,减少了模型性能受噪声或错误数据影响的风险。
许可证
Grimoire of SQL 在 Apache 2 许可证下公开使用。请在使用此数据集时确保适当的归属。
搜集汇总
数据集介绍
构建方式
Grimoire of SQL数据集通过整合并优化多个现有数据集(如Spider、BirdBench和Gretel)构建而成。在构建过程中,数据集对原始数据中的错误进行了修正,优化了自然语言查询的表述,并验证了SQL查询的可执行性。通过GPT-4o-mini生成的解释进一步增强了数据集的解释性,确保了数据的高质量和一致性。
特点
Grimoire of SQL数据集的特点在于其高质量的自然语言查询和经过验证的SQL语句。每个示例包含详细的上下文信息、示例行数据以及难度评级,帮助用户更好地理解查询的复杂性。数据集还提供了原始查询和修正后的查询,增强了透明度和可追溯性。通过GPT-4o-mini生成的解释进一步提升了数据集的解释性,使其成为训练和评估文本到SQL模型的理想选择。
使用方法
Grimoire of SQL数据集可通过Hugging Face Datasets Hub轻松加载。用户只需使用`load_dataset`函数即可获取数据集,并利用其中的自然语言查询和SQL语句进行模型训练和评估。数据集的高质量和详细注释使其适用于多种应用场景,包括文本到SQL模型的微调、SQL生成性能的基准测试以及开发自然语言数据库查询工具。
背景与挑战
背景概述
Grimoire of SQL数据集是一个专门为训练和评估文本到SQL模型而设计的综合性数据集,由多个现有数据集(如Spider、BirdBench和Gretel)整合而成,并对其中的错误进行了修正,优化了自然语言查询,并验证了SQL查询的可执行性。该数据集由Evan Phibbs等人于2024年创建,旨在为GPT-4及其变体模型提供高质量微调支持,确保其生成SQL语句的鲁棒性。Grimoire of SQL的推出显著提升了文本到SQL领域的研究水平,为自然语言数据库查询、SQL生成性能的基准测试以及开发SQL生成工具提供了可靠的数据基础。
当前挑战
Grimoire of SQL数据集在构建过程中面临了多重挑战。首先,源数据集(如BirdBench和Spider)中存在大量SQL语法错误和自然语言查询的语法问题,这些问题严重影响了模型的训练效果。其次,数据集整合过程中需要对不同来源的查询进行标准化处理,以确保其语法和语义的一致性。此外,验证SQL查询的可执行性也是一个复杂且耗时的过程,需要确保每个SQL语句在其对应的数据库中能够正确执行。这些挑战通过结合大型语言模型(如GPT-4)和人工验证的方式得以解决,最终生成了一个高质量且可靠的文本到SQL数据集。
常用场景
经典使用场景
Grimoire of SQL数据集在自然语言处理领域中被广泛用于训练和评估文本到SQL的转换模型。通过整合并优化多个现有数据集,如Spider、BirdBench和Gretel,该数据集为研究人员提供了一个高质量的训练平台,特别适用于GPT-4及其变体的微调,以确保生成的SQL语句具有高度的准确性和可执行性。
衍生相关工作
Grimoire of SQL数据集的发布推动了文本到SQL转换领域的多项经典工作。基于该数据集,研究人员开发了多种先进的模型和算法,进一步提升了自然语言查询到SQL语句的转换精度。此外,该数据集还为相关领域的基准测试提供了新的标准,促进了学术界的深入研究和创新。
数据集最近研究
最新研究方向
在自然语言处理与数据库交互的领域中,Grimoire of SQL数据集为文本到SQL模型的训练与评估提供了高质量的资源。该数据集通过整合并优化Spider、BirdBench和Gretel等现有数据集,修正了其中的错误,提升了自然语言查询的清晰度,并验证了SQL查询的可执行性。近年来,随着大语言模型如GPT-4的广泛应用,Grimoire of SQL在模型微调与性能评估中展现出显著优势。其前沿研究方向聚焦于提升SQL生成的准确性与解释性,特别是在复杂查询场景下的表现。此外,该数据集还推动了SQL生成工具的开发,为自然语言数据库查询的实际应用提供了可靠支持。Grimoire of SQL的出现不仅填补了现有数据集的不足,还为文本到SQL领域的研究与实践注入了新的活力。
以上内容由遇见数据集搜集并总结生成


