FileGram
收藏Hugging Face2026-04-03 更新2026-04-04 收录
下载链接:
https://huggingface.co/datasets/Choiszt/FileGram
下载链接
链接失效反馈官方服务:
资源简介:
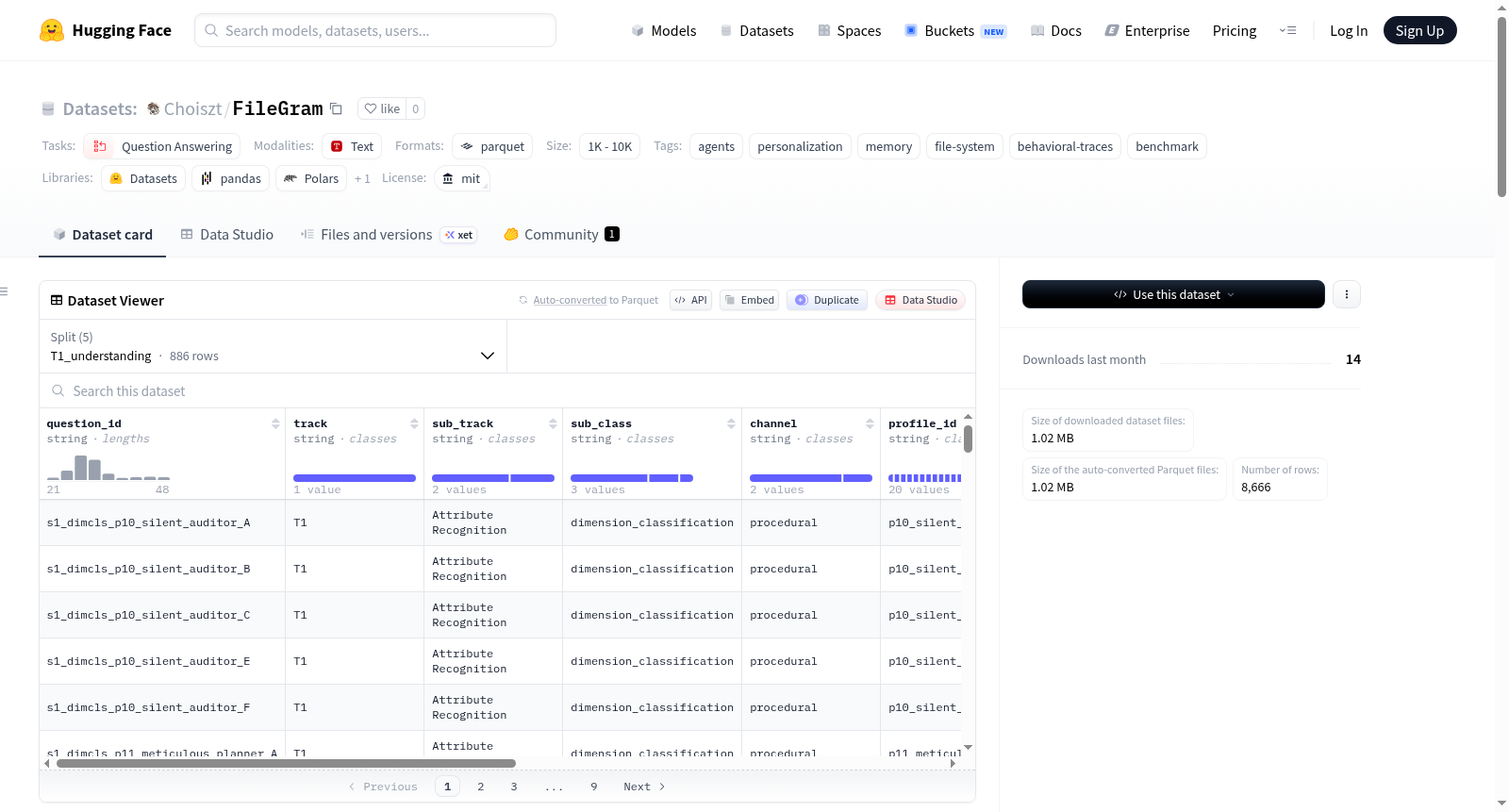
FileGram 是一个用于评估基于文件系统行为轨迹的记忆中心个性化框架的综合数据集。该数据集包含 4,333 个问答对,分布在 4 个评估轨道中,涵盖理解、推理、检测和多模态任务。数据集结构包括数据(以 parquet 格式存储,按轨道分割)、20 个用户配置文件(定义在 6 个行为维度上)、32 个任务定义以及每个任务的初始文件包。评估轨道分为 T1(理解)、T2(推理)、T3(检测)和 T4(多模态),每个轨道包含不同的子任务和问题数量。数据集适用于问答任务,特别关注代理个性化、记忆、文件系统和行为轨迹的基准测试。
创建时间:
2026-04-01
原始信息汇总
FileGram 数据集概述
基本信息
- 数据集名称: FileGram
- 托管地址: https://huggingface.co/datasets/Choiszt/FileGram
- 许可证: MIT
- 任务类别: 问答
- 标签: 智能体、个性化、记忆、文件系统、行为轨迹、基准测试
数据集内容
- 核心内容: 一个用于评估基于文件系统行为轨迹的记忆中心个性化能力的综合框架。
- 数据规模: 包含 4,333 个问答对。
- 用户画像: 定义了 20 个用户画像,每个画像由 6 个行为维度 刻画。
- 任务定义: 包含 32 个任务定义,涵盖理解、创建、组织、综合、迭代和维护。
- 工作空间: 提供 32 个工作空间包,包含用于轨迹生成的多模态文件。
数据结构与特征
数据集包含以下特征字段:
question_id: 问题IDtrack: 评估赛道sub_track: 子赛道sub_class: 子类别channel: 渠道profile_id: 画像IDinput_trajectories: 输入轨迹question: 问题choices: 选项correct: 正确答案metadata: 元数据
数据划分
数据集提供以下划分:
all: 全部数据,共 4,333 个样本。T1_understanding: 理解赛道,共 886 个样本。T2_reasoning: 推理赛道,共 1,694 个样本。T3_detection: 检测赛道,共 1,103 个样本。T4_multimodal: 多模态赛道,共 650 个样本。
评估赛道详情
| 赛道 | 子任务 | 问题数量 | 描述 |
|---|---|---|---|
| T1: 理解 | 属性识别、行为指纹 | 886 | 从行为轨迹重建用户画像 |
| T2: 推理 | 行为推断、轨迹解耦 | 1,694 | 模式推断和多用户轨迹分离 |
| T3: 检测 | 异常检测、偏移分析 | 1,103 | 行为漂移和异常识别 |
| T4: 多模态 | 文件定位、视觉定位 | 650 | 对渲染文档和屏幕录像进行推理 |
行为维度
20个用户画像由以下6个维度(左/中/右)刻画:
| 维度 | 左 | 中 | 右 |
|---|---|---|---|
| 消费 | 顺序深度阅读者 | 目标搜索者 | 广度优先扫描者 |
| 生产 | 全面型 | 平衡型 | 极简型 |
| 组织 | 深度嵌套 | 自适应 | 扁平化 |
| 迭代 | 增量式 | 平衡型 | 重写式 |
| 管理 | 选择性 | 实用主义 | 保存主义 |
| 跨模态 | 视觉主导 | 混合型 | 纯文本 |
相关资源
- 论文: FileGram: Grounding Agent Personalization in File-System Behavioral Traces
- GitHub代码库: https://github.com/Synvo-ai/FileGram
- 引用信息: bibtex @inproceedings{liu2026filegram, title = {FileGram: Grounding Agent Personalization in File-System Behavioral Traces}, author = {Liu, Shuai and Tian, Shulin and Hu, Kairui and Dong, Yuhao and Yang, Zhe and Li, Bo and Yang, Jingkang and Loy, Chen Change and Liu, Ziwei}, booktitle = {European Conference on Computer Vision (ECCV)}, year = {2026} }
搜集汇总
数据集介绍
构建方式
在智能代理个性化研究领域,FileGram数据集的构建体现了严谨的仿真与标注流程。该数据集通过模拟20个具有不同行为维度的用户配置文件,在32个涵盖理解、创建、组织等任务的工作空间中生成文件系统行为轨迹。每条数据记录均包含问题、轨迹、选项及正确答案,最终形成了跨越四个评估轨道的4,333个高质量问答对,其构建过程深度融合了行为建模与多模态文件操作的真实场景。
特点
FileGram数据集的核心特征在于其系统性地整合了行为轨迹与个性化评估。数据集不仅提供了丰富的用户行为维度标签,如消费模式、组织习惯等,还包含了从文本到视觉的多模态文件素材。其结构化的四重评估轨道——理解、推理、检测与多模态——能够全面检验智能代理在记忆与个性化任务上的能力,为研究提供了细粒度且可扩展的基准测试环境。
使用方法
研究人员可通过Hugging Face的`datasets`库便捷地加载FileGram数据集。用户可以选择加载完整的4,333个问题,或依据评估轨道(如T1_understanding)进行针对性加载。数据集支持进一步按子轨道或行为维度进行筛选,便于开展特定任务的分析与模型训练,为评估代理在文件系统行为轨迹上的个性化理解与推理能力提供了标准化的实验接口。
背景与挑战
背景概述
FileGram数据集由Synvo-ai团队于2026年提出,旨在为基于文件系统行为轨迹的智能体个性化研究提供基准评估框架。该数据集聚焦于从用户日常文件操作中提取行为模式,以支撑记忆中心型个性化代理的开发。其核心研究问题在于如何利用非结构化的文件系统交互数据,实现对用户偏好、习惯及认知风格的精准建模与推理,从而推动人机交互与个性化人工智能领域向更细粒度、更贴近真实用户行为的方向发展。
当前挑战
FileGram所针对的领域挑战在于,传统个性化系统往往依赖显式反馈或有限的行为日志,难以捕捉用户在复杂文件管理任务中隐含的多维度认知特征。数据构建过程中的挑战则体现为:需在保护用户隐私的前提下,合成既符合真实行为逻辑又覆盖多样人格维度的轨迹数据;同时,数据需平衡多模态文件内容与行为序列的关联性,以支持理解、推理、检测及多模态四个评估轨道的严谨评测。
常用场景
经典使用场景
在智能代理与个性化计算领域,FileGram数据集为基于文件系统行为轨迹的记忆中心化个性化评估提供了标准化的基准框架。该数据集通过模拟真实用户的文件操作行为,构建了涵盖理解、推理、检测与多模态四大任务的问答对,使得研究者能够系统性地测试代理模型从行为痕迹中重建用户画像、推断行为模式以及识别异常的能力。其经典使用场景在于评估代理模型如何利用文件系统的交互历史,实现个性化的任务适应与决策支持,从而推动智能代理在复杂环境中的认知与记忆能力发展。
实际应用
在实际应用层面,FileGram数据集为开发具备个性化能力的智能助手与文件管理系统提供了重要的数据支撑。基于该数据集训练的模型能够理解用户的文件使用习惯,自动优化文件组织、推荐相关资源或检测异常操作,从而提升工作效率与信息安全。例如,在办公自动化场景中,系统可根据用户的行为轨迹预测其需求,主动提供文档整理或内容检索服务;在教育与培训领域,则可利用行为分析辅助个性化学习路径的规划。这些应用彰显了行为轨迹数据在实现智能化、自适应人机协作中的实用价值。
衍生相关工作
围绕FileGram数据集,学术界已衍生出一系列经典研究工作,主要集中在行为轨迹的表示学习、个性化代理的架构设计以及多模态推理模型的开发。例如,部分研究利用该数据集探索了基于图神经网络或时序模型的行为编码方法,以提升用户画像重建的准确性;另有工作专注于设计记忆增强的代理框架,通过结合文件系统轨迹实现长期个性化的任务执行。此外,该数据集也激发了跨模态理解方面的创新,如结合视觉渲染文档与屏幕录制进行联合推理,推动了多模态智能代理在真实场景中的应用演进。
以上内容由遇见数据集搜集并总结生成


