SAMM
收藏Hugging Face2025-07-19 更新2025-07-20 收录
下载链接:
https://huggingface.co/datasets/SJJ0854/SAMM
下载链接
链接失效反馈官方服务:
资源简介:
SAMM数据集是一个大规模的数据集,用于检测和定位语义协调的多模态操作。它包含文本和图像,以及指示操作类型、操作区域和操作位置的注释。
创建时间:
2025-07-18
原始信息汇总
数据集概述
基本信息
- 名称: SAMM
- 许可证: Apache-2.0
- 任务类别:
- 标记分类 (Token Classification)
- 文本分类 (Text Classification)
- 语言: 英语 (en)
- 规模: 100K < n < 1M
数据集简介
SAMM 是一个用于检测和定位语义协调的多模态操纵的大规模数据集。
数据集统计
- 统计信息见数据集详情页中的统计图表。
标注信息
- 文本 (
text): 原始或操纵的文本标题。 - 图像 (
image): 原始或操纵图像的相对路径。 - 操纵类型 (
fake_cls): 表示操纵的类型(例如伪造、编辑)。 - 图像操纵区域 (
fake_image_box): 图像中操纵区域的边界框坐标。 - 文本操纵位置 (
fake_text_pos): 指定text字符串中操纵标记位置的索引列表。 - CAP文本信息 (
cap_texts): 从上下文辅助提示 (CAP) 标注中提取的文本信息。 - CAP图像信息 (
cap_images): CAP 标注中视觉信息的相对路径。 - CAP文本操纵标记 (
idx_cap_texts): 二进制数组,指示cap_texts中的名人是否被篡改(1 = 篡改,0 = 未篡改)。 - CAP图像操纵标记 (
idx_cap_images): 二进制数组,指示cap_images中的名人是否被篡改(1 = 篡改,0 = 未篡改)。
示例标注
json { "text": "Lachrymose Terri Butler, whose letter prompted Peter Dutton to cancel Troy Newmans visa, was clearly upset.", "fake_cls": "attribute_manipulation", "image": "emotion_jpg/65039.jpg", "id": 13, "fake_image_box": [665, 249, 999, 671], "cap_texts": { "Terri Butler": "Terri Butler Gender: Female, Occupation: Politician, Birth year: 1977, Main achievement: Member of Australian Parliament.", "Peter Dutton": "Peter Dutton Gender: Male, Occupation: Politician, Birth year: 1970, Main achievement: Australian Minister for Defence." }, "cap_images": { "Terri Butler": "Terri Butler", "Peter Dutton": "Peter Dutton" }, "idx_cap_texts": [1, 0], "idx_cap_images": [1, 0], "fake_text_pos": [0, 11, 13, 14, 15] }
搜集汇总
数据集介绍
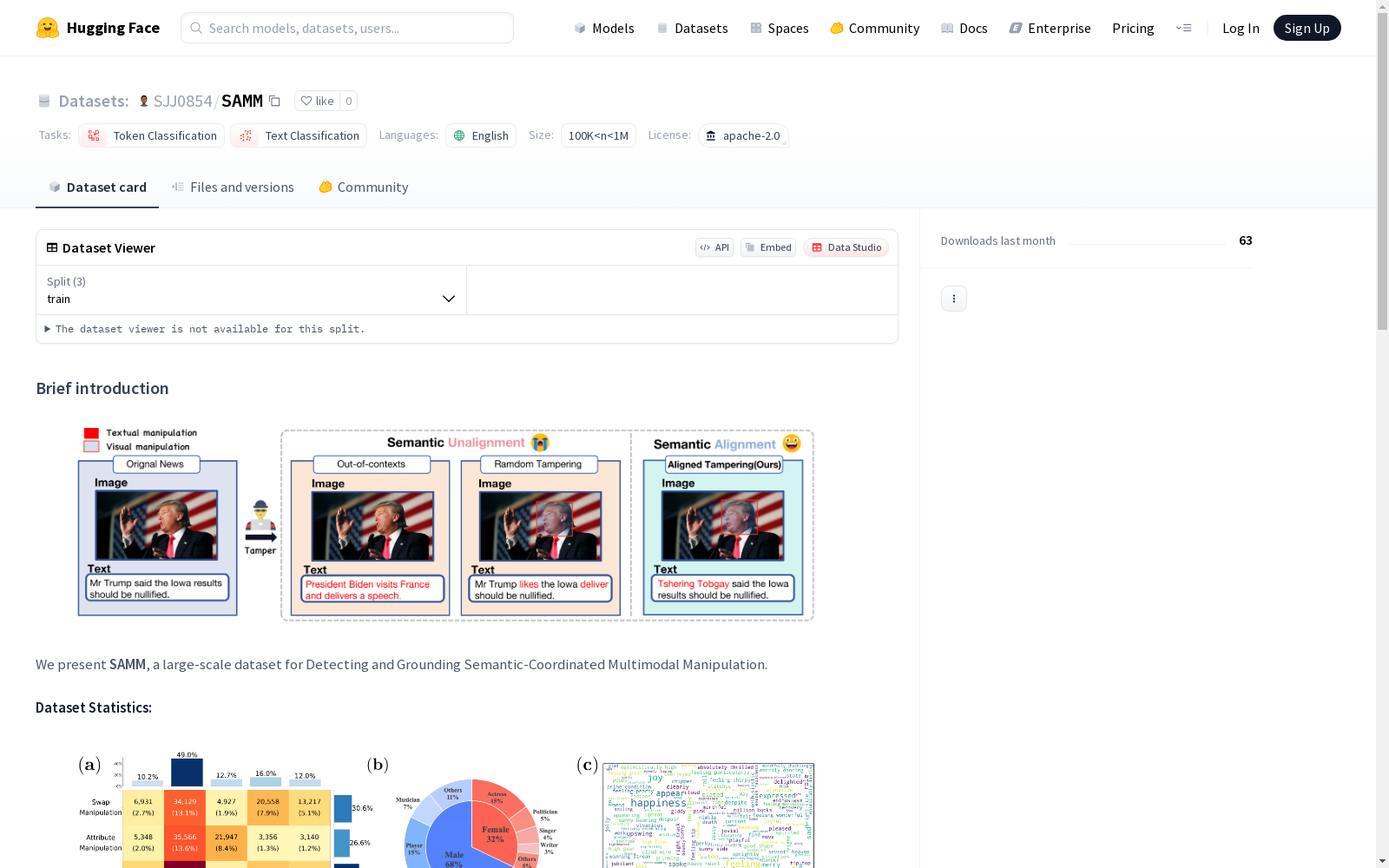
构建方式
SAMM数据集作为多模态操纵检测领域的重要资源,其构建过程体现了严谨的学术规范。研究团队通过系统采集包含文本-图像对的原始数据,采用半自动标注与人工校验相结合的方式,对语义协同的多模态操纵现象进行细粒度标注。每项数据样本均包含原始图像路径、文本描述以及详细的操纵类型标记(如属性篡改等),同时通过边界框坐标和文本位置索引实现篡改区域的精确定位。标注过程中引入上下文辅助提示(CAP)机制,为名人实体补充职业、成就等结构化背景信息,显著提升了数据集的语义丰富度。
特点
该数据集最突出的特点是其多维度标注体系与大规模数据体量的有机结合。在内容维度上,同时涵盖文本层面的词级篡改标注(fake_text_pos)和图像层面的区域级篡改标注(fake_image_box),并配备9种细粒度操纵类型分类(fake_cls)。在结构维度上,创新性地引入CAP双通道标注系统,通过cap_texts和cap_images分别提供文本与视觉的辅助上下文,配合idx_cap系列索引实现篡改目标的交叉验证。统计显示数据集包含10万至100万样本量级,且文本篡改位置与图像篡改区域存在显著的语义关联性。
使用方法
研究者可通过标准数据加载接口快速获取多模态样本,其中文本数据适用于序列标注或文本分类任务,图像数据支持目标检测或区域分类任务。使用fake_cls字段可进行操纵类型识别研究,结合fake_text_pos和fake_image_box能开展跨模态篡改定位实验。CAP标注系统特别适用于需要实体背景知识的细粒度分析场景,如通过cap_texts构建知识图谱辅助推理。建议预处理时注意保持文本分词与标注位置的对应关系,对于图像操作建议采用归一化坐标处理。
背景与挑战
背景概述
SAMM数据集作为一项专注于检测与定位语义协调多模态操纵的大规模数据集,由研究团队在多媒体内容安全领域推出,旨在应对数字时代下日益增长的虚假信息挑战。该数据集通过整合文本与图像的篡改标注,为研究者提供了丰富的多模态操纵案例,涵盖了属性篡改、情感误导等多种操纵类型。其独特的CAP(Contextual Auxiliary Prompt)标注体系不仅标注了篡改内容,还提供了上下文辅助信息,显著提升了数据集的科研价值与应用潜力。SAMM的构建标志着多媒体内容真实性验证研究从单一模态向多模态协同分析的重要跨越,为虚假新闻检测、深度伪造防御等关键领域提供了基准数据支持。
当前挑战
SAMM数据集面临的挑战主要体现在多模态语义对齐的复杂性上。文本与图像篡改的协同检测需要解决跨模态特征不一致问题,例如篡改文本描述与视觉篡改区域之间的语义鸿沟。数据构建过程中,精确标注多模态篡改边界存在技术难度,特别是当篡改涉及细粒度属性(如人物身份、情感表达)时,人工标注的可靠性易受主观判断影响。此外,CAP标注系统虽然增强了上下文信息,但如何平衡标注粒度与数据处理效率仍待优化。在应用层面,多模态篡改模式的动态演变要求数据集持续更新以覆盖新型攻击手法,这对版本迭代机制提出了较高要求。
常用场景
经典使用场景
在多媒体内容真实性验证领域,SAMM数据集为检测和定位语义协调的多模态操纵提供了重要基准。该数据集通过标注图像和文本中的篡改区域及语义变化,支持研究者开发跨模态一致性验证模型,尤其在虚假新闻检测和深度伪造识别等场景中展现出独特价值。其精细的边界框标注和文本位置索引,使得模型能够精准捕捉图文不匹配的异常模式。
衍生相关工作
基于SAMM数据集已衍生出多篇顶会论文,包括跨模态对比学习框架CMCL、基于图神经网络的篡改传播分析模型GTP等经典工作。这些研究在ICCV和ACL等会议上提出的多模态注意力对齐机制、语义一致性度量方法等创新,显著推进了多媒体取证领域的发展。
数据集最近研究
最新研究方向
在多媒体内容真实性验证领域,SAMM数据集因其大规模标注的语义协调多模态操纵样本而备受关注。该数据集通过精细标注的图像篡改区域和文本篡改位置,为检测跨模态一致性破坏提供了关键研究基础。近期研究聚焦于多模态联合表征学习框架的构建,旨在捕捉文本描述与视觉内容间的微妙不一致特征。随着深度伪造技术和生成式AI的快速发展,该数据集在政治人物言论验证、新闻可信度评估等场景的应用价值日益凸显,相关成果已被用于构建新一代多模态内容安全防护系统。
以上内容由遇见数据集搜集并总结生成


