GymID
收藏arXiv2024-06-27 更新2024-07-23 收录
下载链接:
https://ambrosia-benchmark.github.io/
下载链接
链接失效反馈官方服务:
资源简介:
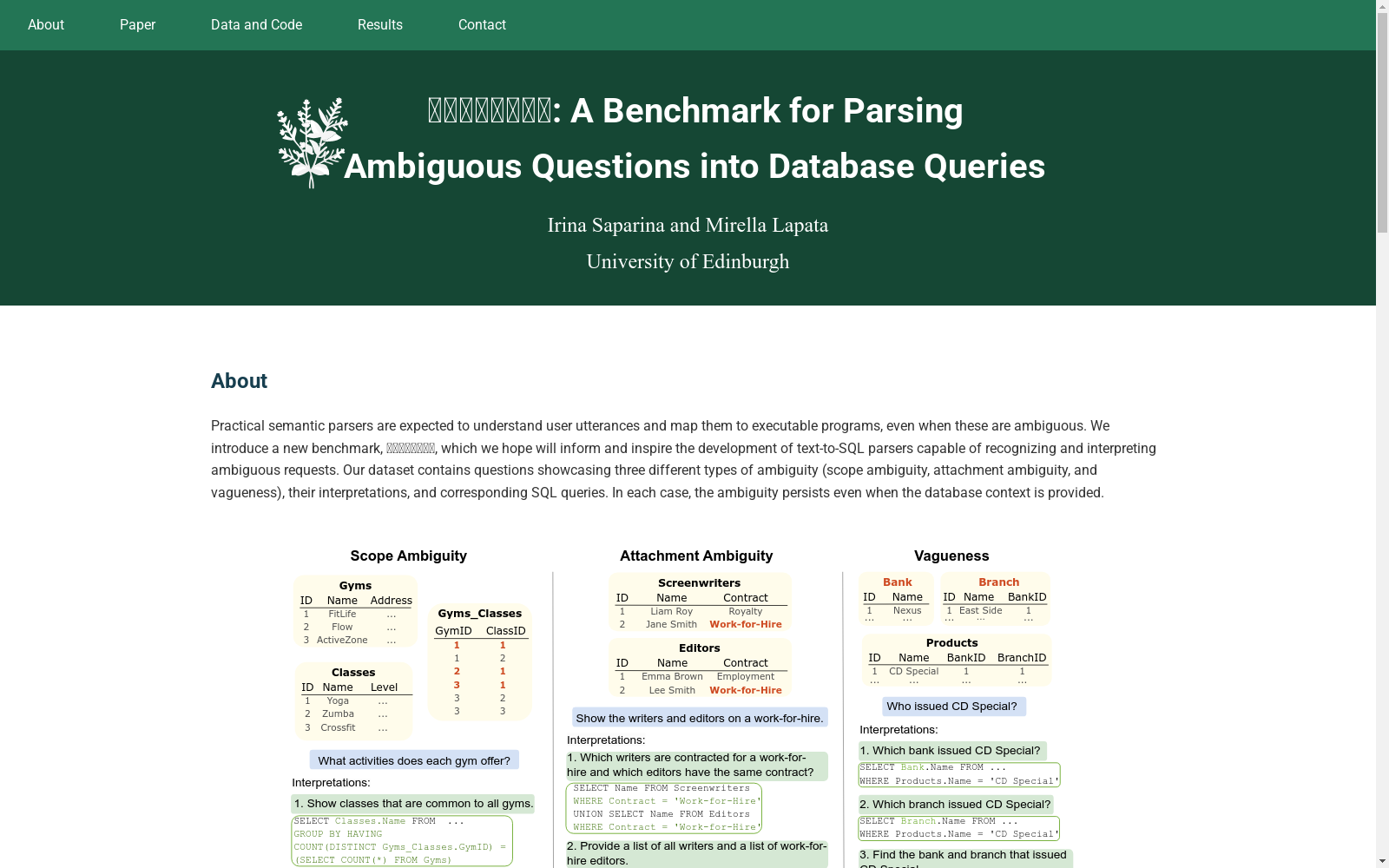
GymID数据集由爱丁堡大学信息学院语言、认知与计算研究所创建,旨在测试文本到SQL解析器处理模糊查询的能力。该数据集包含846个多表数据库,涵盖16个不同领域,包含模糊问题及其清晰解释和复杂的SQL查询。数据集通过自动生成数据库和人工注释相结合的方式创建,涉及范围模糊、附件模糊和模糊性三种类型。主要应用于自然语言处理领域,解决模糊查询的解析问题。
提供机构:
爱丁堡大学信息学院语言、认知与计算研究所
创建时间:
2024-06-27
搜集汇总
数据集介绍
构建方式
GymID 数据集的构建方式涉及了三个关键步骤。首先,确定一个感兴趣的领域,例如银行、教育或娱乐等。其次,生成关键概念和关系,这些概念和关系将作为数据库中潜在歧义性的来源。这一步骤确保了数据库结构能够支持特定类型的歧义。最后,通过 SQL 语句生成数据库的表结构,包括 CREATE TABLE 和 INSERT INTO 语句。为了确保数据库的真实性和歧义性,研究人员使用大型语言模型 OpenChat 进行自动生成,并手动验证和过滤生成的数据库。
特点
GymID 数据集的特点包括包含 16 个不同领域的 846 个多表数据库,以及 1,277 个包含歧义的问题和它们的人类提供的无歧义解释。数据集涵盖了三种类型的歧义:范围歧义、附着歧义和模糊性,并展示了多样的 SQL 查询。每个问题都对应多个可能的解释,每个解释都对应一个或多个 SQL 查询。此外,数据集还包含了针对每种歧义类型的不同数据库配置,以模拟真实世界的语义解析场景。
使用方法
使用 GymID 数据集时,首先需要理解数据集中的歧义类型和相应的数据库结构。然后,可以根据问题编写 SQL 查询,并使用数据集中的解释来验证查询的正确性。数据集还可以用于评估和改进文本到 SQL 语义解析模型的能力,特别是在处理歧义问题方面的表现。研究人员可以使用数据集中的数据库和查询来训练和测试他们的模型,并分析模型的性能和失败模式。
背景与挑战
背景概述
��������数据集是由爱丁堡大学语言、认知与计算研究所的Irina Saparina和Mirella Lapata共同创建的。该数据集旨在为文本到SQL解析器提供一个基准,以识别和解释模糊的用户请求。数据集包含展示了三种不同类型模糊性(范围模糊性、附着模糊性和模糊性)的问题、它们的解释和相应的SQL查询。��������数据集涵盖了16个不同的领域,包含846个多表数据库、1277个模糊问题、由人类提供的无歧义解释和复杂的SQL查询(总计2965个)。数据集的创建涉及从零开始控制生成数据库的新方法,旨在模仿现实世界的语义解析场景。该数据集对于研究模糊性在自然语言处理中的应用具有重要影响,并为文本到SQL解析器的发展提供了新的方向。
当前挑战
��������数据集面临的挑战包括:1)解决领域问题的挑战:尽管文本到SQL解析在现实世界应用中非常重要,但模糊性仍然是一个普遍存在的挑战。��������数据集揭示了即使是先进的模型在识别和解释模糊问题方面也存在困难。2)构建过程中的挑战:��������数据集的构建涉及到自动生成支持模糊性问题的数据库,这需要使用大型语言模型(LLM)来生成数据库元素。然而,LLM生成的数据库可能不够真实,需要人工验证和筛选。此外,��������数据集的构建还涉及到人工标注模糊问题和解释,这可能存在标注错误或不一致性的问题。
常用场景
经典使用场景
在文本到SQL解析领域,GymID数据集提供了一个基准,用于测试和评估模型在解析具有歧义的查询时的能力。该数据集包含了展示三种不同类型歧义(范围歧义、附着歧义和模糊性)的问题、它们的解释以及相应的SQL查询。这些问题即使在数据库上下文被提供的情况下,歧义仍然存在。GymID数据集通过从零开始控制生成数据库的独特方法来实现这一点。
衍生相关工作
GymID数据集的发布推动了文本到SQL解析领域的研究进展,并为后续相关工作提供了重要的参考。例如,研究者可以利用GymID数据集来评估和改进他们的模型在处理歧义查询方面的能力,或者开发新的算法和技术来更好地理解和解释自然语言查询。此外,GymID数据集还可能被用于其他相关领域,如自然语言理解和机器翻译,以帮助提高这些领域的模型性能和准确性。
数据集最近研究
最新研究方向
在文本到SQL解析领域,��������数据集的引入为理解和解释模糊请求的解析器开发提供了一个新的基准。该数据集包含展示三种不同类型模糊性(范围模糊性、附着模糊性和模糊性)的问题、它们的解释和相应的SQL查询。��������通过从零开始控制生成数据库的新方法来实现这一点,其中每个数据库都支持特定类型的模糊性。研究人员在��������上对各种LLMs进行了基准测试,发现即使是最高级的模型也难以识别和解释问题中的模糊性。��������的引入对于语义解析领域具有重要意义,它不仅为模型评估提供了一个新的基准,而且为理解和解决自然语言处理中的模糊性问题提供了宝贵的数据。
相关研究论文
- 1AMBROSIA: A Benchmark for Parsing Ambiguous Questions into Database Queries爱丁堡大学信息学院语言、认知与计算研究所 · 2024年
以上内容由遇见数据集搜集并总结生成


