HumanEval-V-Benchmark
收藏Hugging Face2024-10-17 更新2024-12-12 收录
下载链接:
https://huggingface.co/datasets/HumanEval-V/HumanEval-V-Benchmark
下载链接
链接失效反馈官方服务:
资源简介:
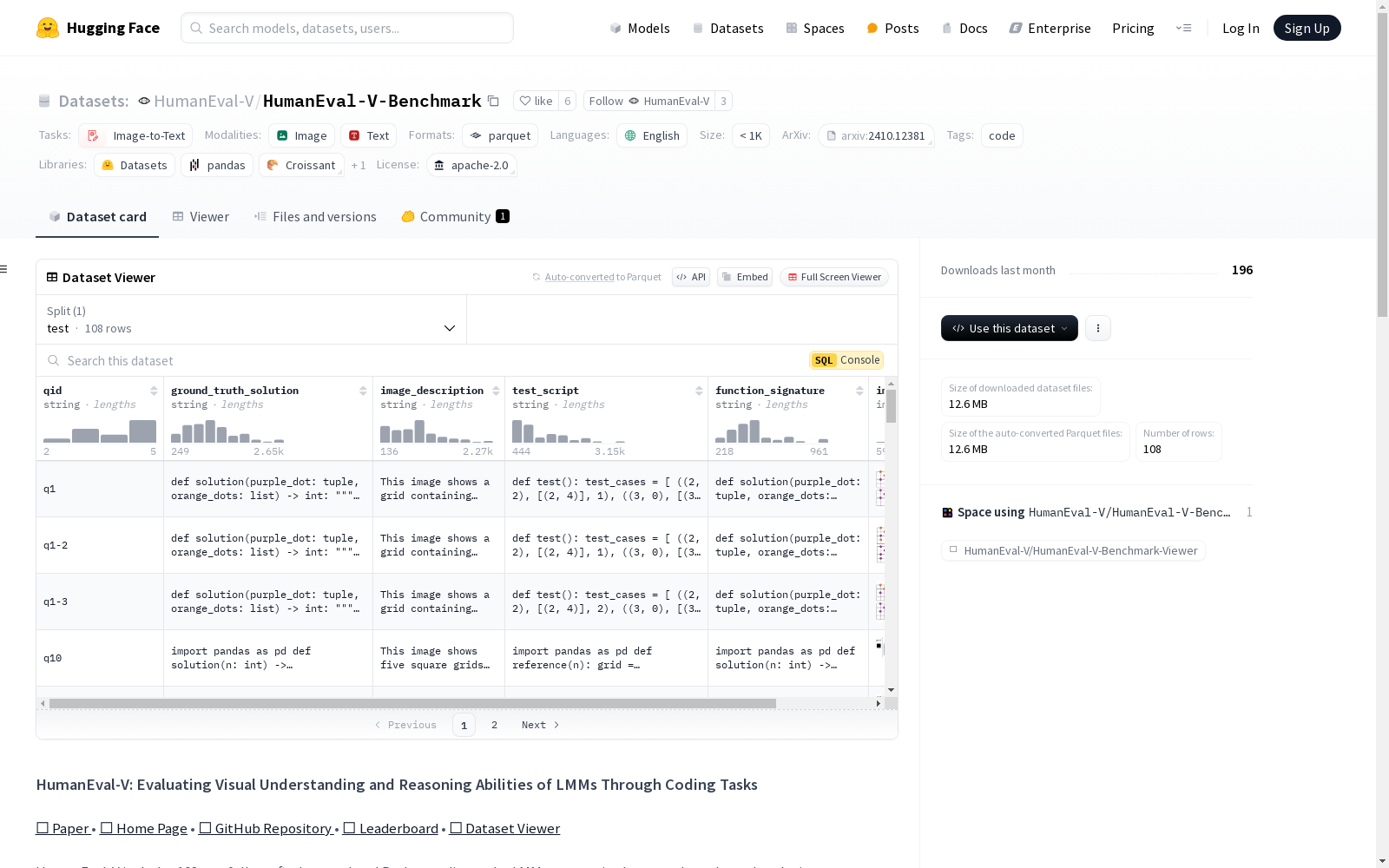
HumanEval-V数据集包含108个精心设计的Python编程任务,旨在评估大型多模态模型(LMMs)的视觉理解和推理能力。每个任务基于提供的视觉上下文和预定义的Python函数签名来完成代码解决方案。数据集的每个任务包括以下字段:qid(任务的唯一标识符)、image(包含解决任务所需的关键视觉上下文的单个图像)、function_signature(包括问题描述、必要的导入和LMMs必须完成的函数签名)、test_script(用于验证生成代码正确性的测试用例)、ground_truth_solution(专家制作的参考解决方案,不用于评估过程)和image_description(图像的人类标注描述,用于实验分析,不包括在基准评估中)。数据集的评估过程包括从代码块中提取内容、使用抽象语法树(AST)解析器解析生成的代码、形成最终预测解决方案并测试其正确性,以及通过执行基于的度量标准(特别是pass@k)评估生成的代码解决方案。
The HumanEval-V dataset comprises 108 meticulously designed Python programming tasks, which are crafted to evaluate the visual comprehension and reasoning capabilities of Large Multimodal Models (LMMs). Each task requires completing a code solution based on the provided visual context and a predefined Python function signature. Every task in the dataset includes the following fields: qid (the unique identifier of the task), image (a single image containing the critical visual context necessary for solving the task), function_signature (encompassing the problem description, required imports, and the function signature that LMMs must complete), test_script (test cases used to validate the correctness of the generated code), ground_truth_solution (reference solutions developed by experts, not utilized in the evaluation process), and image_description (human-annotated descriptions of the image, intended for experimental analysis and excluded from benchmark evaluation). The evaluation workflow for the dataset involves extracting content from code blocks, parsing the generated code using an Abstract Syntax Tree (AST) parser, formulating the final predicted solution and testing its correctness, as well as evaluating the generated code solutions via execution-based metrics, most notably pass@k.
创建时间:
2024-10-11
原始信息汇总
HumanEval-V 数据集概述
数据集信息
- 特征:
qid: 字符串类型,每个编码任务的唯一标识符。ground_truth_solution: 字符串类型,专家提供的参考解决方案,不用于评估过程。image_description: 字符串类型,图像的人工标注描述,用于实验分析,不参与基准评估。test_script: 字符串类型,用于验证生成代码正确性的测试用例。function_signature: 字符串类型,包含问题描述、必要的导入和函数签名,模型需根据此完成代码。image: 图像类型,包含解决任务所需的关键视觉上下文。
- 分割:
test: 包含108个示例,数据大小为12840101字节。
- 下载大小: 12571814字节
- 数据集大小: 12840101字节
- 配置:
default: 数据文件路径为data/test-*。
- 许可证: Apache 2.0
- 任务类别: 图像到文本
- 语言: 英语
- 标签: 代码
- 显示名称: humanevalv
数据集结构
每个任务包含以下字段:
qid: 唯一标识符。image: 单张图像,包含解决任务所需的关键视觉上下文。function_signature: 包含问题描述、必要的导入和函数签名。test_script: 用于验证生成代码正确性的测试用例。ground_truth_solution: 专家提供的参考解决方案。image_description: 图像的人工标注描述。
提示格式
每个任务包含清晰的指令和提供的函数签名,指导模型生成代码解决方案。
使用方法
使用Hugging Face的datasets库加载数据集:
python
from datasets import load_dataset
humaneval_v = load_dataset("HumanEval-V/HumanEval-V-Benchmark", split="test")
引用
bibtex @article{zhang2024humanevalv, title={HumanEval-V: Evaluating Visual Understanding and Reasoning Abilities of Large Multimodal Models Through Coding Tasks}, author={Zhang, Fengji and Wu, Linquan and Bai, Huiyu and Lin, Guancheng and Li, Xiao and Yu, Xiao and Wang, Yue and Chen, Bei and Keung, Jacky}, journal={arXiv preprint arXiv:2410.12381}, year={2024}, }
搜集汇总
数据集介绍
构建方式
HumanEval-V-Benchmark数据集通过精心设计的108个初级Python编程任务构建而成,旨在评估大型多模态模型(LMMs)在视觉理解和推理能力方面的表现。每个任务均包含一个图像、函数签名、测试脚本以及专家编写的参考解决方案。数据集的结构设计确保了任务的多样性和复杂性,涵盖了从图像描述到代码生成的完整流程。
特点
该数据集的特点在于其任务设计的多样性和严谨性。每个任务均配备了详细的图像描述、函数签名和测试脚本,确保了评估的全面性和准确性。此外,数据集还提供了专家编写的参考解决方案,尽管这些解决方案不直接用于评估,但为研究提供了宝贵的参考。数据集的结构清晰,便于研究人员快速理解和使用。
使用方法
使用HumanEval-V-Benchmark数据集时,研究人员可以通过Hugging Face的`datasets`库轻松加载数据。加载后,数据集中的每个任务均包含图像、函数签名、测试脚本等关键信息,研究人员可以根据这些信息进行模型训练和评估。评估过程中,生成的代码将通过执行测试脚本进行验证,确保评估结果的准确性和可靠性。
背景与挑战
背景概述
HumanEval-V-Benchmark数据集由Fengji Zhang等研究人员于2024年提出,旨在评估大型多模态模型(LMMs)在视觉理解和推理能力方面的表现。该数据集包含108个精心设计的入门级Python编程任务,要求模型根据提供的视觉上下文和预定义的函数签名完成代码解决方案。每个任务均配备了手工编写的测试用例,用于基于执行的pass@k评估。该数据集的推出为多模态模型在编程任务中的性能评估提供了新的基准,推动了视觉与代码结合领域的研究进展。
当前挑战
HumanEval-V-Benchmark面临的挑战主要体现在两个方面。首先,在领域问题层面,如何准确评估多模态模型在视觉理解和代码生成任务中的综合能力是一个复杂的问题,需要设计既能反映模型真实性能又具有普适性的评估指标。其次,在数据集构建过程中,确保每个任务的视觉上下文与代码任务之间的逻辑一致性,以及手工编写测试用例的全面性和准确性,均对数据质量提出了较高要求。此外,如何平衡任务的难度,使其既能覆盖基础能力又能挑战模型的极限,也是构建过程中需要解决的关键问题。
常用场景
经典使用场景
HumanEval-V-Benchmark数据集主要用于评估大型多模态模型(LMMs)在视觉理解和推理能力方面的表现。通过提供108个精心设计的Python编程任务,模型需要根据给定的视觉上下文和预定义的函数签名生成代码解决方案。每个任务都配备了手工编写的测试用例,用于执行基于pass@k的评估。这一数据集在学术界和工业界被广泛用于验证模型在结合视觉和编程任务中的综合能力。
解决学术问题
HumanEval-V-Benchmark解决了多模态模型在视觉理解和代码生成任务中的评估难题。传统方法往往难以量化模型在结合视觉和编程任务中的表现,而该数据集通过提供标准化的测试任务和评估指标,填补了这一空白。它不仅帮助研究者更准确地衡量模型的性能,还为多模态模型的优化和改进提供了明确的方向,推动了该领域的研究进展。
衍生相关工作
HumanEval-V-Benchmark的发布催生了一系列相关研究工作,特别是在多模态模型和代码生成领域。许多研究者基于该数据集提出了新的模型架构和训练方法,以提升模型在视觉和编程任务中的表现。此外,该数据集还启发了其他类似基准的构建,进一步推动了多模态模型在复杂任务中的应用和发展。
以上内容由遇见数据集搜集并总结生成


