---
annotations_creators:
- crowdsourced
- machine-generated
language_creators:
- found
language:
- en
license:
- cc-by-nc-4.0
multilinguality:
- monolingual
size_categories:
- 100K<n<1M
source_datasets:
- original
- extended|hotpot_qa
task_categories:
- text-classification
task_ids:
- natural-language-inference
- multi-input-text-classification
paperswithcode_id: anli
pretty_name: Adversarial NLI
dataset_info:
config_name: plain_text
features:
- name: uid
dtype: string
- name: premise
dtype: string
- name: hypothesis
dtype: string
- name: label
dtype:
class_label:
names:
'0': entailment
'1': neutral
'2': contradiction
- name: reason
dtype: string
splits:
- name: train_r1
num_bytes: 8006888
num_examples: 16946
- name: dev_r1
num_bytes: 573428
num_examples: 1000
- name: test_r1
num_bytes: 574917
num_examples: 1000
- name: train_r2
num_bytes: 20801581
num_examples: 45460
- name: dev_r2
num_bytes: 556066
num_examples: 1000
- name: test_r2
num_bytes: 572639
num_examples: 1000
- name: train_r3
num_bytes: 44720719
num_examples: 100459
- name: dev_r3
num_bytes: 663148
num_examples: 1200
- name: test_r3
num_bytes: 657586
num_examples: 1200
download_size: 26286748
dataset_size: 77126972
configs:
- config_name: plain_text
data_files:
- split: train_r1
path: plain_text/train_r1-*
- split: dev_r1
path: plain_text/dev_r1-*
- split: test_r1
path: plain_text/test_r1-*
- split: train_r2
path: plain_text/train_r2-*
- split: dev_r2
path: plain_text/dev_r2-*
- split: test_r2
path: plain_text/test_r2-*
- split: train_r3
path: plain_text/train_r3-*
- split: dev_r3
path: plain_text/dev_r3-*
- split: test_r3
path: plain_text/test_r3-*
default: true
---
# Dataset Card for "anli"
## Table of Contents
- [Dataset Description](#dataset-description)
- [Dataset Summary](#dataset-summary)
- [Supported Tasks and Leaderboards](#supported-tasks-and-leaderboards)
- [Languages](#languages)
- [Dataset Structure](#dataset-structure)
- [Data Instances](#data-instances)
- [Data Fields](#data-fields)
- [Data Splits](#data-splits)
- [Dataset Creation](#dataset-creation)
- [Curation Rationale](#curation-rationale)
- [Source Data](#source-data)
- [Annotations](#annotations)
- [Personal and Sensitive Information](#personal-and-sensitive-information)
- [Considerations for Using the Data](#considerations-for-using-the-data)
- [Social Impact of Dataset](#social-impact-of-dataset)
- [Discussion of Biases](#discussion-of-biases)
- [Other Known Limitations](#other-known-limitations)
- [Additional Information](#additional-information)
- [Dataset Curators](#dataset-curators)
- [Licensing Information](#licensing-information)
- [Citation Information](#citation-information)
- [Contributions](#contributions)
## Dataset Description
- **Homepage:**
- **Repository:** [https://github.com/facebookresearch/anli/](https://github.com/facebookresearch/anli/)
- **Paper:** [Adversarial NLI: A New Benchmark for Natural Language Understanding](https://arxiv.org/abs/1910.14599)
- **Point of Contact:** [More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
- **Size of downloaded dataset files:** 18.62 MB
- **Size of the generated dataset:** 77.12 MB
- **Total amount of disk used:** 95.75 MB
### Dataset Summary
The Adversarial Natural Language Inference (ANLI) is a new large-scale NLI benchmark dataset,
The dataset is collected via an iterative, adversarial human-and-model-in-the-loop procedure.
ANLI is much more difficult than its predecessors including SNLI and MNLI.
It contains three rounds. Each round has train/dev/test splits.
### Supported Tasks and Leaderboards
[More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
### Languages
English
## Dataset Structure
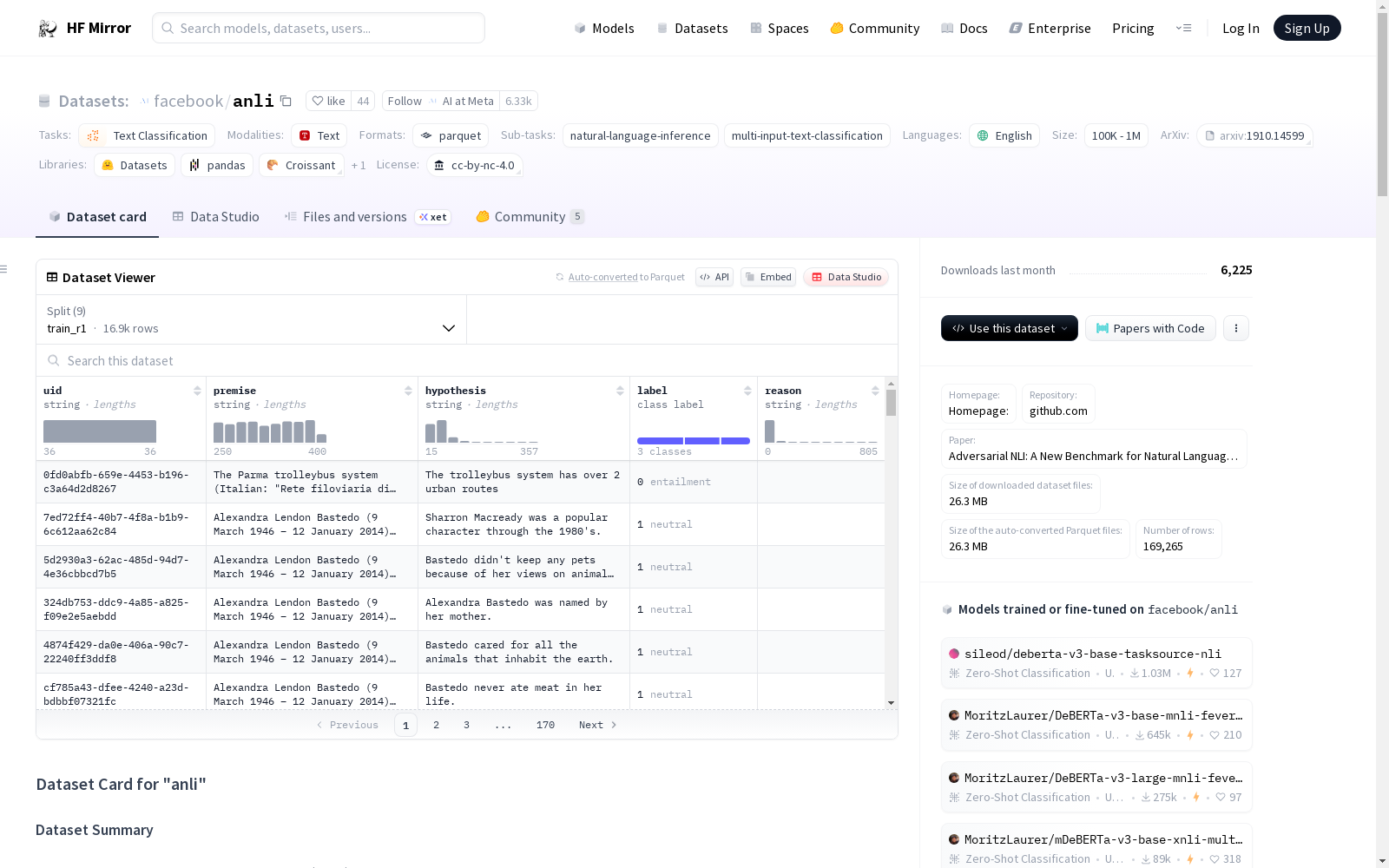
### Data Instances
#### plain_text
- **Size of downloaded dataset files:** 18.62 MB
- **Size of the generated dataset:** 77.12 MB
- **Total amount of disk used:** 95.75 MB
An example of 'train_r2' looks as follows.
```
This example was too long and was cropped:
{
"hypothesis": "Idris Sultan was born in the first month of the year preceding 1994.",
"label": 0,
"premise": "\"Idris Sultan (born January 1993) is a Tanzanian Actor and comedian, actor and radio host who won the Big Brother Africa-Hotshot...",
"reason": "",
"uid": "ed5c37ab-77c5-4dbc-ba75-8fd617b19712"
}
```
### Data Fields
The data fields are the same among all splits.
#### plain_text
- `uid`: a `string` feature.
- `premise`: a `string` feature.
- `hypothesis`: a `string` feature.
- `label`: a classification label, with possible values including `entailment` (0), `neutral` (1), `contradiction` (2).
- `reason`: a `string` feature.
### Data Splits
| name |train_r1|dev_r1|train_r2|dev_r2|train_r3|dev_r3|test_r1|test_r2|test_r3|
|----------|-------:|-----:|-------:|-----:|-------:|-----:|------:|------:|------:|
|plain_text| 16946| 1000| 45460| 1000| 100459| 1200| 1000| 1000| 1200|
## Dataset Creation
### Curation Rationale
[More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
### Source Data
#### Initial Data Collection and Normalization
[More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
#### Who are the source language producers?
[More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
### Annotations
#### Annotation process
[More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
#### Who are the annotators?
[More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
### Personal and Sensitive Information
[More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
## Considerations for Using the Data
### Social Impact of Dataset
[More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
### Discussion of Biases
[More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
### Other Known Limitations
[More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
## Additional Information
### Dataset Curators
[More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
### Licensing Information
[cc-4 Attribution-NonCommercial](https://github.com/facebookresearch/anli/blob/main/LICENSE)
### Citation Information
```
@InProceedings{nie2019adversarial,
title={Adversarial NLI: A New Benchmark for Natural Language Understanding},
author={Nie, Yixin
and Williams, Adina
and Dinan, Emily
and Bansal, Mohit
and Weston, Jason
and Kiela, Douwe},
booktitle = "Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics",
year = "2020",
publisher = "Association for Computational Linguistics",
}
```
### Contributions
Thanks to [@thomwolf](https://github.com/thomwolf), [@easonnie](https://github.com/easonnie), [@lhoestq](https://github.com/lhoestq), [@patrickvonplaten](https://github.com/patrickvonplaten) for adding this dataset.
---
annotations_creators:
- 众包
- 机器生成
language_creators:
- 现有语料采集
language:
- 英语
license:
- 知识共享署名-非商业性使用4.0国际许可协议(CC BY-NC 4.0)
multilinguality:
- 单语言
size_categories:
- 10万<n<100万
source_datasets:
- 原始数据集
- 扩展自HotpotQA
task_categories:
- 文本分类
task_ids:
- 自然语言推理
- 多输入文本分类
paperswithcode_id: anli
pretty_name: 对抗性自然语言推理(Adversarial NLI)
dataset_info:
config_name: 纯文本
features:
- name: 唯一标识符(UID)
dtype: 字符串
- name: 前提句
dtype: 字符串
- name: 假设句
dtype: 字符串
- name: 标签
dtype:
类别标签:
可选值:
'0': 蕴含(entailment)
'1': 中立(neutral)
'2': 矛盾(contradiction)
- name: 推理依据
dtype: 字符串
splits:
- name: 第一轮训练集(train_r1)
字节数: 8006888
样本数量: 16946
- name: 第一轮验证集(dev_r1)
字节数: 573428
样本数量: 1000
- name: 第一轮测试集(test_r1)
字节数: 574917
样本数量: 1000
- name: 第二轮训练集(train_r2)
字节数: 20801581
样本数量: 45460
- name: 第二轮验证集(dev_r2)
字节数: 556066
样本数量: 1000
- name: 第二轮测试集(test_r2)
字节数: 572639
样本数量: 1000
- name: 第三轮训练集(train_r3)
字节数: 44720719
样本数量: 100459
- name: 第三轮验证集(dev_r3)
字节数: 663148
样本数量: 1200
- name: 第三轮测试集(test_r3)
字节数: 657586
样本数量: 1200
下载大小: 26286748
生成数据集大小: 77126972
configs:
- config_name: 纯文本
data_files:
- split: 第一轮训练集(train_r1)
路径: 纯文本/train_r1-*
- split: 第一轮验证集(dev_r1)
路径: 纯文本/dev_r1-*
- split: 第一轮测试集(test_r1)
路径: 纯文本/test_r1-*
- split: 第二轮训练集(train_r2)
路径: 纯文本/train_r2-*
- split: 第二轮验证集(dev_r2)
路径: 纯文本/dev_r2-*
- split: 第二轮测试集(test_r2)
路径: 纯文本/test_r2-*
- split: 第三轮训练集(train_r3)
路径: 纯文本/train_r3-*
- split: 第三轮验证集(dev_r3)
路径: 纯文本/dev_r3-*
- split: 第三轮测试集(test_r3)
路径: 纯文本/test_r3-*
默认配置: true
---
# 数据集卡片:"anli"
## 目录
- [数据集描述](#数据集描述)
- [数据集概述](#数据集概述)
- [支持任务与基准排行榜](#支持任务与基准排行榜)
- [语言](#语言)
- [数据集结构](#数据集结构)
- [数据样例](#数据样例)
- [数据字段](#数据字段)
- [数据划分](#数据划分)
- [数据集构建流程](#数据集构建流程)
- [构建初衷](#构建初衷)
- [源数据](#源数据)
- [标注信息](#标注信息)
- [个人与敏感信息](#个人与敏感信息)
- [数据集使用须知](#数据集使用须知)
- [数据集的社会影响](#数据集的社会影响)
- [偏见分析](#偏见分析)
- [已知其他局限](#已知其他局限)
- [附加信息](#附加信息)
- [数据集维护团队](#数据集维护团队)
- [授权协议](#授权协议)
- [引用信息](#引用信息)
- [贡献致谢](#贡献致谢)
## 数据集描述
- **主页:**
- **代码仓库:** [https://github.com/facebookresearch/anli/](https://github.com/facebookresearch/anli/)
- **相关论文:** [对抗性自然语言推理:自然语言理解新基准](https://arxiv.org/abs/1910.14599)
- **联系人:** [更多信息待补充](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
- **下载数据集文件大小:** 18.62 MB
- **生成数据集大小:** 77.12 MB
- **总磁盘占用:** 95.75 MB
### 数据集概述
对抗性自然语言推理(Adversarial NLI,简称ANLI)是一款大规模标准化自然语言推理基准数据集。该数据集通过迭代式人机协同对抗流程采集所得,其难度远超SNLI、MNLI等前代自然语言推理数据集。数据集共包含三轮划分,每一轮均配有训练、验证与测试子集。
### 支持任务与基准排行榜
[更多信息待补充](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
### 语言
英语
## 数据集结构
### 数据样例
#### 纯文本配置
- **下载数据集文件大小:** 18.62 MB
- **生成数据集大小:** 77.12 MB
- **总磁盘占用:** 95.75 MB
以下是`train_r2`划分的一条数据样例:
该样例过长已被截断:
{
"hypothesis": "Idris Sultan was born in the first month of the year preceding 1994.",
"label": 0,
"premise": ""Idris Sultan (born January 1993) is a Tanzanian Actor and comedian, actor and radio host who won the Big Brother Africa-Hotshot...",
"reason": "",
"uid": "ed5c37ab-77c5-4dbc-ba75-8fd617b19712"
}
### 数据字段
所有划分的数据字段均保持一致。
#### 纯文本配置
- `uid`:字符串类型特征,即唯一标识符
- `premise`:字符串类型特征,即前提句
- `hypothesis`:字符串类型特征,即假设句
- `label`:分类标签,可选值包括`entailment`(蕴含,对应0)、`neutral`(中立,对应1)、`contradiction`(矛盾,对应2)
- `reason`:字符串类型特征,即推理依据
### 数据划分
| 配置名称 | train_r1 | dev_r1 | train_r2 | dev_r2 | train_r3 | dev_r3 | test_r1 | test_r2 | test_r3 |
|----------|---------:|-------:|---------:|-------:|---------:|-------:|--------:|--------:|--------:|
| plain_text | 16946 | 1000 | 45460 | 1000 | 100459 | 1200 | 1000 | 1000 | 1200 |
## 数据集构建流程
### 构建初衷
[更多信息待补充](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
### 源数据
#### 初始数据采集与标准化
[更多信息待补充](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
#### 源语言生成者是谁?
[更多信息待补充](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
### 标注信息
#### 标注流程
[更多信息待补充](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
#### 标注人员是谁?
[更多信息待补充](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
### 个人与敏感信息
[更多信息待补充](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
## 数据集使用须知
### 数据集的社会影响
[更多信息待补充](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
### 偏见分析
[更多信息待补充](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
### 已知其他局限
[更多信息待补充](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
## 附加信息
### 数据集维护团队
[更多信息待补充](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
### 授权协议
[知识共享署名-非商业性使用4.0国际许可协议](https://github.com/facebookresearch/anli/blob/main/LICENSE)
### 引用信息
@InProceedings{nie2019adversarial,
title={对抗性自然语言推理:自然语言理解的新基准},
author={Nie, Yixin
and Williams, Adina
and Dinan, Emily
and Bansal, Mohit
and Weston, Jason
and Kiela, Douwe},
booktitle = "第58届国际计算语言学协会年会论文集",
year = "2020",
publisher = "国际计算语言学协会",
}
### 贡献致谢
感谢[@thomwolf](https://github.com/thomwolf)、[@easonnie](https://github.com/easonnie)、[@lhoestq](https://github.com/lhoestq)、[@patrickvonplaten](https://github.com/patrickvonplaten)为本数据集的收录提供支持。