engine-predictive-maintenance-dataset
收藏Hugging Face2026-05-01 更新2026-05-02 收录
下载链接:
https://huggingface.co/datasets/premswan/engine-predictive-maintenance-dataset
下载链接
链接失效反馈官方服务:
资源简介:
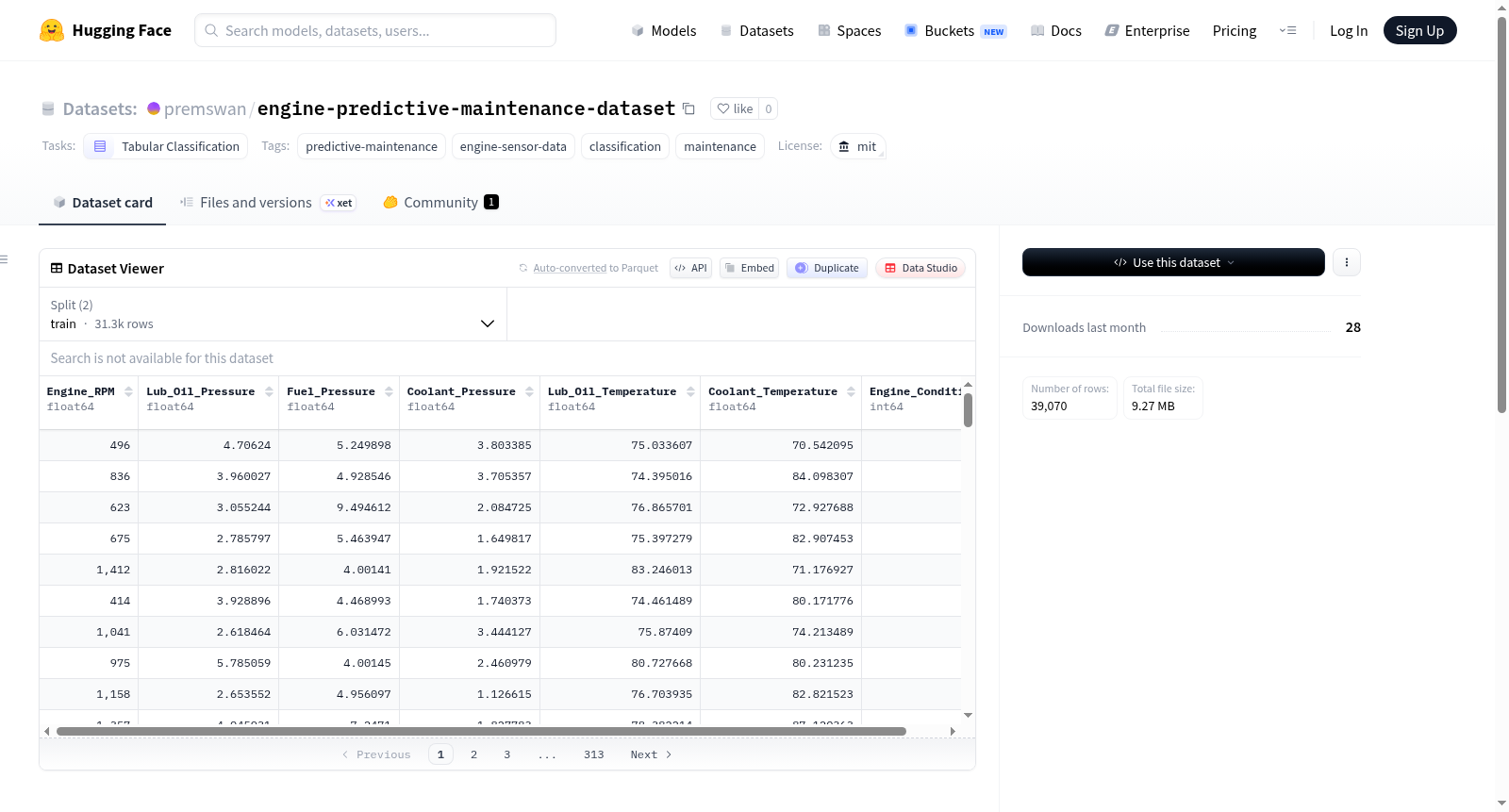
Engine Predictive Maintenance Dataset 是一个用于构建预测性维护模型的数据集,旨在通过传感器读数分类引擎是正常运行还是需要维护。数据集包含原始数据、预处理数据和清理数据三个配置。原始数据文件为 `data/engine_data.csv`,预处理数据分为训练集(`data/train.csv`)和测试集(`data/test.csv`),清理数据文件为 `data/cleaned_engine_data.csv`。数据预处理步骤包括列名标准化、重复值删除、数值类型转换、二进制目标验证、基本物理检查、分层训练/测试分割和基于训练集的极端值裁剪。目标变量为 `Engine_Condition`,其中 `0` 表示正常/活跃类别,`1` 表示故障/需要维护类别。数据集最后更新时间为 2026-04-29 18:55:32。
The Engine Predictive Maintenance Dataset is a dataset for building predictive maintenance models, designed to classify whether an engine is operating normally or requires maintenance based on sensor readings. The dataset includes three configurations: raw data, preprocessed data, and cleaned data. The raw data file is `data/engine_data.csv`, the preprocessed data is divided into training set (`data/train.csv`) and test set (`data/test.csv`), and the cleaned data file is `data/cleaned_engine_data.csv`. The data preprocessing steps include column name standardization, duplicate value removal, numerical type conversion, binary target validation, basic physical checks, stratified train/test split, and extreme value clipping based on the training set. The target variable is `Engine_Condition`, where `0` represents the normal/active class and `1` represents the fault/needs maintenance class. The dataset was last updated on 2026-04-29 18:55:32.
创建时间:
2026-04-29
原始信息汇总
数据集概述
该数据集名为 Engine Predictive Maintenance Dataset(引擎预测性维护数据集),旨在通过传感器读数构建一个分类模型,判断引擎是正常运行还是需要维护。
数据集配置
数据集包含三个配置,分别对应不同处理阶段的数据:
- raw:原始数据,文件为
data/engine_data.csv,一个拆分。 - prepared:经准备后的训练/测试数据,文件包括
data/train.csv(训练集)和data/test.csv(测试集)。 - cleaned:清洗后的数据,文件为
data/cleaned_engine_data.csv,一个拆分。
数据清洗与准备
数据准备过程中执行了以下步骤:
- 列名标准化
- 删除重复项
- 数值类型转换
- 二元目标验证
- 基本物理合理性检查
- 分层训练/测试集划分
- 基于训练集的极端值裁剪
目标变量
目标变量为 Engine_Condition,含义如下:
0:正常 / 活跃状态1:故障 / 需要维护状态
最后更新日期
该数据集最后更新于 2026-04-29 18:55:32。
搜集汇总
数据集介绍
构建方式
该数据集面向工业设备预测性维护场景,旨在通过传感器读数实现发动机运行状态分类。原始数据存储于单一CSV文件(engine_data.csv),涵盖多维度传感器测量数值。构建过程经由标准化处理流水线:首先进行列名规范化与重复数据消除,接着实施数值类型转换与二元目标变量(Engine_Condition)验证,并通过基础物理合理性检测剔除异常值。采用分层采样策略将数据划分为训练集与测试集,进一步以训练集极值作为裁剪边界完成特征缩放,最终生成cleaned、prepared等多版本数据子集。
使用方法
数据集通过HuggingFace Datasets库实现灵活加载,支持raw、prepared与cleaned三种配置。研究者可选用原始版本进行自定义预处理,或直接调用预处理完备的子集以聚焦模型开发。训练/测试分离设计兼容scikit-learn等框架的交叉验证流程,无需额外分割。典型工作流包括:加载prepared配置获取train/test划分,基于Engine_Condition列训练分类模型,最终在测试集上评估预测性维护性能。此结构化设计显著降低了工业机器学习项目的实施门槛。
背景与挑战
背景概述
随着工业4.0与物联网技术的深度融合,预测性维护已成为工业智能化转型的关键环节。该发动机预测性维护数据集于2026年创建,旨在利用传感器读数构建分类模型,以判别发动机运行状态属于正常抑或需要维护。该数据集围绕二元分类任务设计,将发动机状态划分为正常(0)与故障(1)两类,为工业设备健康管理提供了标准化的数据基准。通过公开划分的原始、预处理及清洗版本,该数据集降低了研究门槛,推动了预测性维护算法在真实工业场景中的验证与优化,对智能制造领域的数据驱动决策具有重要促进意义。
当前挑战
该数据集所解决的领域核心挑战在于,工业设备失效模式复杂且数据噪声高,传统基于阈值的维护策略往往导致误判或漏判,亟需可靠的机器学习模型实现精准分类。在构建过程中,面临的主要挑战包括:传感器数据中的列名不一致与重复记录问题,需进行标准化与去重;多源数值型传感器读数的类型转换与异常值识别,要求实施基于训练集的极值裁剪;以及类别不平衡现象,需通过分层采样划分训练集与测试集,确保模型泛化能力。此外,物理合理性校验(如传感器读数是否超出工程极限)亦为数据预处理增添了难度,需在清洗流程中集成领域知识。
常用场景
经典使用场景
在工业4.0与智能制造蓬勃发展的时代浪潮中,设备预测性维护已成为降低运维成本、保障生产安全的关键技术。engine-predictive-maintenance-dataset数据集正是为此而生,其最经典的使用场景聚焦于构建基于传感器读数对发动机运行状态进行二分类的模型。研究人员利用准备好的训练与测试数据,通过特征工程与机器学习算法,精准判断发动机是否处于正常运作或需要维护的故障状态,为工业预测性维护研究提供了标准化的基准测试平台。
解决学术问题
该数据集核心解决了设备健康管理中故障预警不及时与过度维护并存的两难困境。在学术层面,它推动了一系列围绕不平衡分类、时序特征提取、传感器数据异常检测等经典问题的探索。通过提供经过清洗与物理合理性校验的结构化数据,它使研究者能够专注于模型性能的优化,而非数据预处理的繁琐细节,从而加速了预测性维护算法从理论到可复现验证的转化进程,对于推动工业AI领域的方法论演进具有深远意义。
实际应用
在实际工业场景中,该数据集为航空发动机、重型机械等昂贵设备的运维决策提供了数据驱动的解决方案。基于该数据集训练的模型可部署于实时监控系统,通过持续分析振动、温度、压力等传感器数据,提前数小时甚至数天发出维护预警。这不仅避免了计划外停机导致的生产中断,还将传统的定期维修模式升级为按需维护,显著延长了设备使用寿命,降低了备件库存与人力成本,在现代智能工厂中发挥着不可替代的作用。
数据集最近研究
最新研究方向
该数据集聚焦于工业设备预测性维护这一前沿领域,通过采集发动机多维度传感器读数,构建二分类模型以精准区分正常运行与需维护状态。当前研究热点包括结合深度学习与时序分析捕捉传感器数据的潜在退化模式,以及利用迁移学习解决工业场景中标注样本稀缺的问题。该数据集提供标准化预处理流程(如极值裁剪、分层采样)和清晰的基准划分,为对比不同算法在设备健康管理中的鲁棒性与泛化能力提供了可靠测试床。随着物联网与工业4.0的深度融合,此类数据集在推动预测性维护从规则驱动向数据驱动转型中扮演关键角色,有望降低非计划停机风险并优化维护成本,对智能制造系统的可靠性与经济性具有实质性影响。
以上内容由遇见数据集搜集并总结生成


