NaturalConv
收藏Hugging Face2024-11-07 更新2024-12-12 收录
下载链接:
https://huggingface.co/datasets/xywang1/NaturalConv
下载链接
链接失效反馈官方服务:
资源简介:
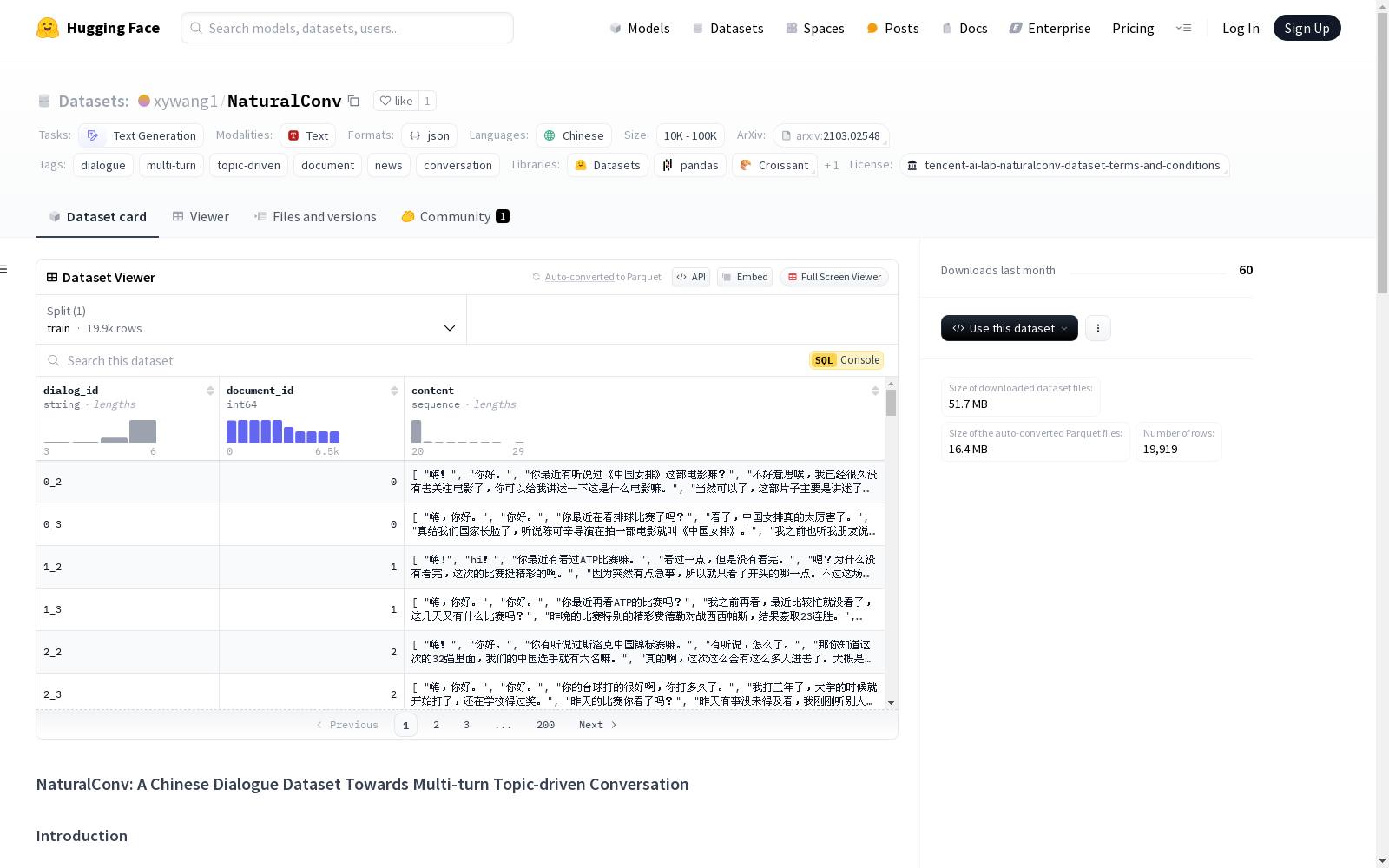
NaturalConv是一个面向多轮话题驱动对话的中文对话数据集。数据集包含5个文件,其中dialog_release.json包含19,919个对话,约40万条对话语句。每个对话由唯一的dialog_id标识,并与一个document_id关联,content包含整个对话会话。document_url_release.json包含6,500个文档,每个文档由唯一的document_id标识,并关联一个topic和url。train.txt、dev.txt和test.txt分别包含训练、开发和测试的dialog_id。数据集用于文本生成任务,适用于对话、多轮对话、话题驱动、文档和新闻等标签。
NaturalConv is a Chinese dialogue dataset oriented towards multi-turn topic-driven conversations. The dataset includes five files, among which dialog_release.json contains 19,919 dialogues and approximately 400,000 conversational utterances. Each dialogue is identified by a unique dialog_id and associated with a document_id, with the "content" field containing the entire conversation session. The document_url_release.json includes 6,500 documents, each identified by a unique document_id and linked to a topic and a URL. The train.txt, dev.txt, and test.txt respectively contain the dialog_id lists for the training, development, and test splits. This dataset is intended for text generation tasks, and is applicable to labels such as dialogue, multi-turn dialogue, topic-driven, document, and news.
创建时间:
2024-11-07
原始信息汇总
NaturalConv: A Chinese Dialogue Dataset Towards Multi-turn Topic-driven Conversation
概述
- 数据集名称: NaturalConv
- 语言: 中文
- 任务类别: 文本生成
- 标签: 对话, 多轮, 主题驱动, 文档, 新闻, 会话
- 数据规模: 10K<n<100K
- 配置:
- 配置名称: default
- 数据文件: dialog_release.json
数据文件
-
dialog_release.json:
- 包含19,919个对话,约40万条对话语句。
- 每个对话包含三个键: "dialog_id", "document_id", "content"。
- "dialog_id": 对话的唯一ID。
- "document_id": 对话所基于的文档ID。
- "content": 整个对话会话的列表。
-
document_url_release.json:
- 包含6,500个文档。
- 每个文档包含三个键: "document_id", "topic", "url"。
- "document_id": 文档的唯一ID。
- "topic": 文档所属的主题。
- "url": 原始文档的URL。
-
train.txt, dev.txt, test.txt:
- 分别包含训练、开发和测试的"dialog_id"。
文档下载
- 仅用于研究目的,可通过提供的代码库下载文档文本。
引用
- 如果使用该数据集,请引用相关论文。
许可证
- 数据集仅用于非商业用途。
- 商业用途授权请联系ailab@tencent.com。
免责声明
- 数据集按“原样”提供,不提供任何明示或暗示的保证。
- 数据集中的观点和意见不代表腾讯或作者的观点。
搜集汇总
数据集介绍
构建方式
NaturalConv数据集的构建基于多轮主题驱动的对话场景,旨在模拟真实世界中的中文对话。该数据集通过收集与特定主题相关的文档,并基于这些文档生成对话内容。具体而言,数据集包含19,919个对话,每个对话均与6,500个文档中的某一篇相关联。对话内容通过人工或半自动方式生成,确保对话的自然性和连贯性。数据集的构建过程注重对话的多样性和主题的广泛覆盖,涵盖了新闻、时事等多个领域。
使用方法
使用NaturalConv数据集时,首先通过加载`dialog_release.json`文件获取对话内容,每个对话包含唯一的`dialog_id`、关联的`document_id`以及完整的对话内容`content`。用户还可以通过`document_url_release.json`文件获取与对话相关的文档信息。数据集提供了`train.txt`、`dev.txt`和`test.txt`文件,分别用于训练、验证和测试。研究人员可以通过提供的代码库下载原始文档文本,进一步丰富对话的背景信息。
背景与挑战
背景概述
NaturalConv数据集由腾讯AI实验室于2021年发布,旨在推动中文多轮主题驱动对话系统的研究。该数据集由Xiaoyang Wang、Chen Li、Jianqiao Zhao和Dong Yu等研究人员共同开发,并在第35届AAAI人工智能会议上首次亮相。数据集包含19,919个对话和6,500个文档,涵盖了新闻、话题驱动对话等多个领域。其核心研究问题是如何在对话系统中有效引入外部知识,以提升对话的连贯性和信息量。NaturalConv的发布为中文对话系统的研究提供了重要的数据支持,推动了该领域的技术进步。
当前挑战
NaturalConv数据集在解决中文多轮主题驱动对话问题时面临多重挑战。首先,对话的连贯性和上下文理解是核心难题,尤其是在引入外部文档作为知识源时,如何确保对话的自然流畅性成为关键。其次,数据集的构建过程中,研究人员需要从大量文档中提取相关信息,并将其与对话内容进行有效关联,这一过程不仅耗时且容易引入噪声。此外,数据集的规模和质量也对模型的训练和评估提出了较高要求,如何在保证数据多样性的同时避免偏差,是构建过程中不可忽视的挑战。
常用场景
经典使用场景
NaturalConv数据集在中文多轮主题驱动对话研究中具有重要应用。该数据集通过提供基于新闻文档的多轮对话,为研究者提供了一个丰富的语料库,用于训练和评估对话生成模型。其经典使用场景包括对话系统的开发与优化,尤其是在主题连贯性和上下文理解方面的研究。
解决学术问题
NaturalConv数据集解决了中文多轮对话研究中数据稀缺的问题,尤其是在主题驱动对话领域。通过提供大量基于新闻文档的对话数据,该数据集为研究者提供了丰富的语料,用于探索对话生成、主题连贯性、上下文理解等关键问题。其发布显著推动了中文对话系统的研究进展,为相关领域的学术研究提供了重要支持。
实际应用
在实际应用中,NaturalConv数据集被广泛用于开发智能客服、虚拟助手等对话系统。通过利用该数据集中的多轮对话数据,开发者能够训练出更加智能、连贯的对话模型,提升用户体验。此外,该数据集还可用于新闻推荐系统的开发,通过分析用户与系统的对话,提供个性化的新闻推荐服务。
数据集最近研究
最新研究方向
在自然语言处理领域,多轮对话系统的研究正逐渐成为热点,而NaturalConv数据集的推出为这一领域提供了重要的资源支持。该数据集以中文多轮主题驱动对话为核心,涵盖了新闻、文档等多种主题,为研究者提供了丰富的对话场景。近年来,基于该数据集的研究主要集中在对话生成模型的优化、主题连贯性保持以及上下文理解能力的提升等方面。特别是在生成式预训练模型(如GPT、BERT)的背景下,如何利用NaturalConv数据集进行更精准的对话生成和主题切换,已成为学术界和工业界共同关注的焦点。此外,该数据集还被广泛应用于对话系统的评估和基准测试,推动了中文对话系统技术的快速发展。
以上内容由遇见数据集搜集并总结生成


