Anindita1979/Phantom_Hallucination_Detection
收藏Hugging Face2026-04-25 更新2026-04-26 收录
下载链接:
https://hf-mirror.com/datasets/Anindita1979/Phantom_Hallucination_Detection
下载链接
链接失效反馈官方服务:
资源简介:
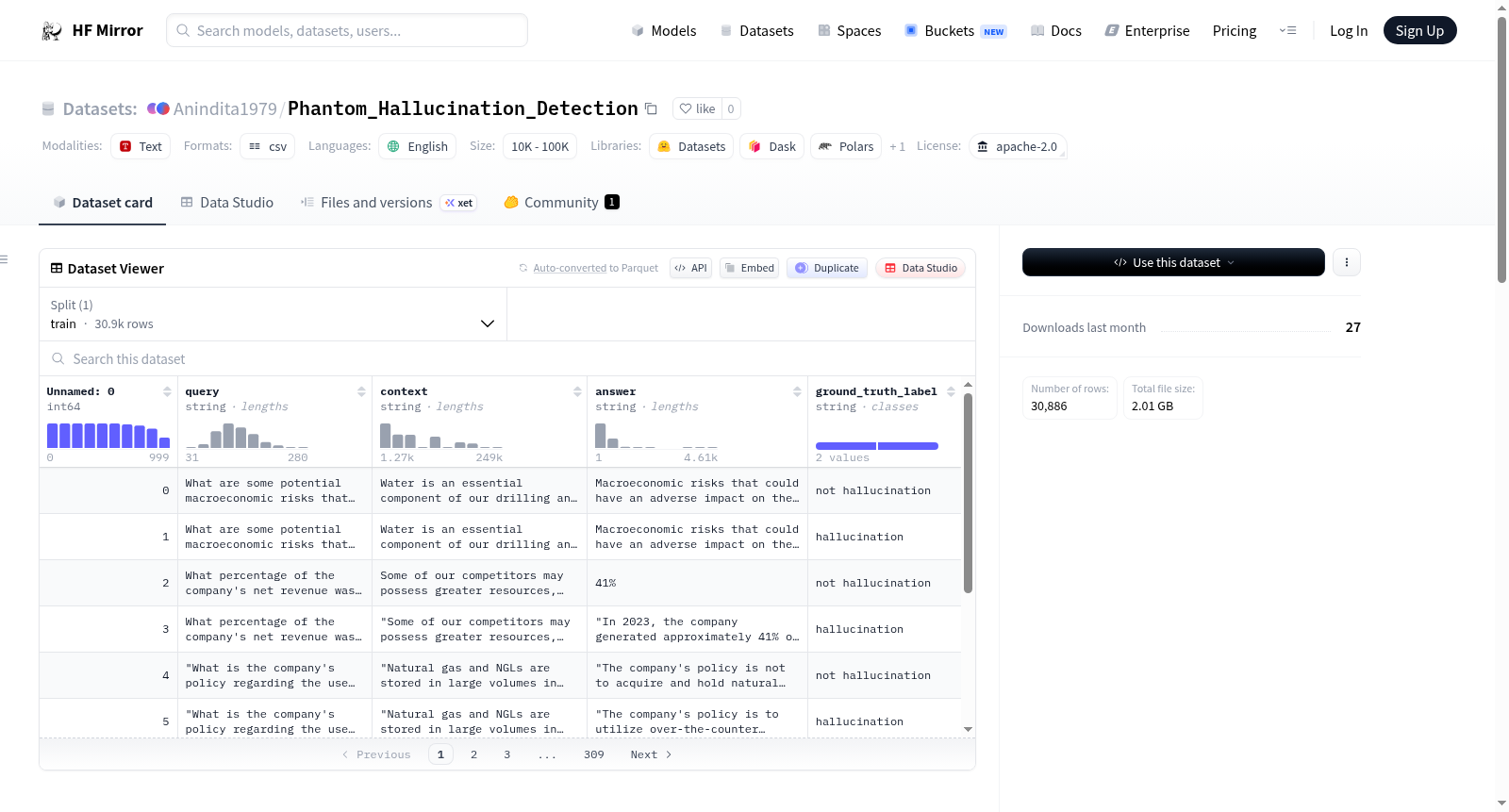
该数据集名为Phantom,是一个用于金融长上下文问答中幻觉检测的基准数据集。它包含多个不同版本的*Phantom*数据集,具有不同的令牌长度(seed, 2k, 5K, 10K, 20K, 30K)以进行长上下文实验,不同的段落位置(开始、中间、结束),以及不同的文件类型(如10K、DEF14A)。数据集结构由多个CSV文件组成,每个文件代表一个特定的数据集版本,例如10K_seed、def14A_5000tokens_middle等,每个数据集仅包含训练集分割。
The dataset is named Phantom: A Benchmark for Hallucination Detection in Financial Long-Context QA. It is designed for hallucination detection in language models and includes multiple variants of the *Phantom* dataset with different token lengths (seed, 2k, 5K, 10K, 20K, 30K) for long context experiments, segments (beginning, middle, end), and filing types (e.g., 10K, DEF14A). The dataset is organized into multiple files, each representing a specific dataset version, such as 10K_seed, def14A_5000tokens_middle, etc., and each dataset is a single CSV file with only a train split.
提供机构:
Anindita1979
搜集汇总
数据集介绍
构建方式
在金融领域长文本问答的复杂语境中,幻觉现象对语言模型的可靠性构成严峻挑战。为解决这一问题,Phantom_Hallucination_Detection数据集应运而生。该数据集由研究团队精心构建,涵盖多种变体,依据不同的令牌长度(如种子、2K、5K、10K、20K、30K)进行划分,以模拟长上下文场景。同时,数据集还按文本片段的位置(开头、中间、结尾)和归档类型(如10K、DEF14A)进行细分,每个变体以独立的CSV文件形式存储,并仅提供训练集划分。
特点
该数据集的核心特色在于其精细化的多维设计。通过调节令牌长度,它能够系统评估语言模型在不同上下文深度下对幻觉的敏感度。而片段位置与归档类型的组合,则揭示了幻觉在文档不同区域及不同文件格式中的分布规律。这种结构化设计使Phantom成为金融长文本问答领域幻觉检测的权威基准,为研究模型在复杂信息密度下的可信度提供了标尺。
使用方法
研究人员可借助Hugging Face的datasets库便捷调用该数据集。具体操作时,通过load_dataset函数指定数据集标识符,并利用data_files参数指向目标CSV文件,例如加载10K文本对应10000令牌且片段位于中间位置的数据。该流程简洁高效,使得针对特定语境配置的幻觉检测实验得以迅速开展,从而有效评估和提升模型在金融长文本问答中的鲁棒性。
背景与挑战
背景概述
Phantom数据集诞生于金融领域对长文本问答中语言模型幻觉检测的迫切需求,由Lanlan Ji、Dominic Seyler等研究人员于2025年在NeurIPS会议上提出。该数据集聚焦于金融监管文件(如10-K、DEF14A)的长上下文问答场景,旨在系统评估模型在复杂金融信息中生成事实性错误答案的倾向。作为首个专门针对金融长文本问答幻觉检测的基准,Phantom通过构建不同token长度(从种子到30K)和文档段落位置(开头、中间、结尾)的多样化样本,为评估长上下文语言模型在专业领域的可靠性提供了关键工具,其影响力延伸至金融风控、合规审查等实际应用场景。
当前挑战
Phantom数据集面对的核心挑战在于金融长上下文问答中的双重复杂性。领域问题层面,语言模型在处理长达数万token的财务报告时,常因信息冗长、专业术语密集而产生无中生有的事实幻觉或上下文引用错误,严重威胁金融决策的准确性。构建过程中,研究人员需克服金融文档的语义稀疏性,设计涵盖不同文件类型、信息分布位置及token长度的精细化样本,确保数据能真实反映模型在关键段落(如财务数据披露)的幻觉表现,同时平衡数据规模和标注成本,避免引入标注者偏见影响幻觉判定的客观性。
常用场景
经典使用场景
在金融领域的长文本问答场景中,语言模型往往面临信息稠密与上下文冗长的双重挑战,幻觉现象因而频发。Phantom数据集专为检测此类场景下的模型幻觉而设计,通过构建涵盖不同文档长度(如2K至30K令牌)、信息位置(段首、段中、段末)及财务文件类型(如10-K年报、DEF14A委托书声明)的多维评测样本,为研究者提供了一个系统性的评估框架。其经典用法是作为基准测试集,用于衡量各类语言模型在金融长文档问答任务中生成内容的忠实度与准确性,从而揭示模型在长上下文推理中的脆弱环节。
实际应用
在实际应用中,Phantom数据集直接服务于金融领域的智能问答系统开发与质量评估。金融机构在投研分析、合规审查、财报解读等环节日益依赖大语言模型进行长文档摘要与关键信息抽取,但模型的幻觉风险可能引发严重误判。Phantom通过模拟真实金融文件(如10-K年报和DEF14A委托书)中不同长度与信息分布的问答,能够为系统开发者在模型部署前提供精准的幻觉检测能力。这不仅帮助工程师优化模型架构与提示策略,还为合规部门提供量化依据,以评估模型输出的可信度,从而降低因信息失真导致的决策风险与监管合规问题。
衍生相关工作
Phantom数据集的发布催生了一系列衍生研究工作,主要集中在两个方向:一是基于该基准开发更先进的幻觉检测方法,例如利用对比学习或检索增强机制识别模型对长文档中特定细节的编造行为;二是将其作为评估工具,用于验证长上下文语言模型(如Transformer类架构的改进版)在处理财务文档时的鲁棒性。此外,研究者们还借鉴其多维设计思路(如变长、变位、变文件类型),构建了面向法律、医学等其他专业领域的类似基准,从而推动了跨领域长文本可信推理的通用评估框架发展。这些工作共同强化了高性能AI系统在高风险行业中的实用价值。
以上内容由遇见数据集搜集并总结生成


