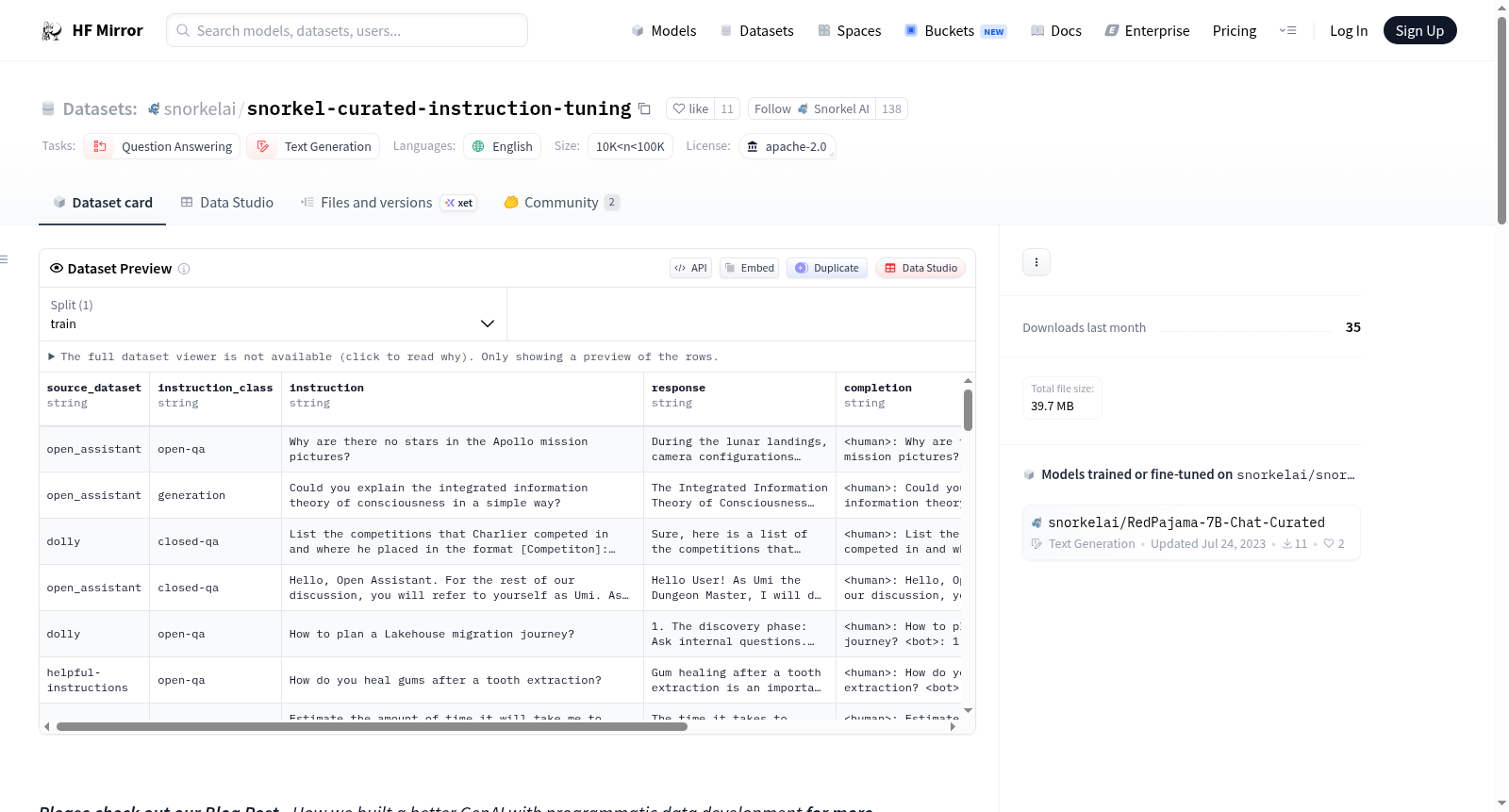
资源简介:
---
license: apache-2.0
task_categories:
- question-answering
- text-generation
language:
- en
size_categories:
- 10K<n<100K
---
***<p style="font-size: 20px">Please check out our Blog Post - [How we built a better GenAI with programmatic data development](https://snorkel.ai/how-we-built-better-genai-with-programmatic-data-development/) for more details!</p>***
## Summary
`snorkel-curated-instruction-tuning` is a curated dataset that consists of high-quality instruction-response pairs.
These pairs were programmatically filtered with weak supervision from open-source datasets [Databricks Dolly-15k](https://huggingface.co/datasets/databricks/databricks-dolly-15k),
[Open Assistant](https://huggingface.co/datasets/OpenAssistant/oasst1),
and [Helpful Instructions](https://huggingface.co/datasets/HuggingFaceH4/helpful_instructions).
To enhance the dataset, we also programmatically classified each instruction based on the InstructGPT paper.
For a more comprehensive understanding of our methodology, please visit our [blog](https://snorkel.ai/how-we-built-better-genai-with-programmatic-data-development/).
## Dataset Overview & Methodology
Instruction tuning is an important step in developing effective [large language models (LLMs)](https://snorkel.ai/large-language-models-llms/) for generative AI tasks.
While proprietary datasets have been used by LLM-backed chatbots, the open-source community has created similar datasets accessible to everyone.
However, the quality of responses collected by volunteers has been inconsistent, affecting the quality of open-source models. Furthermore, there is currently no standard classification of instructions across datasets (many lack classification altogether), which can complicate measurements of instruction diversity when compiling from multiple sources.
Snorkel, with its expertise in converting noisy signals into high-quality supervision, addressed this issue by programmatically scoring, sampling, and filtering open-source datasets.
The curated dataset and methodology are now available for public use.
Please refer to our [blog](https://snorkel.ai/how-we-built-better-genai-with-programmatic-data-development/) for more details on methods and evaluation.
## File descriptions
- `snorkel_curated_11k.jsonl`: 11k high-quality instruction-response pair selected from the mentioned open-source dataset. This is then used to instruction-tune the [snorkelai/RedPajama-7B-Chat-Curated](https://huggingface.co/snorkelai/RedPajama-7B-Chat-Curated/).
- `snorkel_hold_out_set.jsonl`: A hold-out set for evaluation, comparing human preferences between models.
## Intended Uses
- Instruction-tuning LLMs
For more detailed information, please refer to our blog post available at [How we built a better GenAI with programmatic data development](snorkel.ai/how-we-built-a-better-genai-with-programmatic-data-development).
## License/Attribution
**Copyright (2023) Snorkel AI, Inc.** This dataset was developed at [Snorkel AI](https://snorkel.ai/) and its use is subject to the Apache 2.0 license.
This work comes with the collaboration with Together Computer in releasing the [snorkelai/RedPajama-7B-Chat-Curated](https://huggingface.co/snorkelai/RedPajama-7B-Chat-Curated/) model.
Please refer to the licenses of the data subsets you use.
- [Open Assistant](https://huggingface.co/datasets/OpenAssistant/oasst1) is under Apache 2.0 license.
- [Helpful Instructions](https://huggingface.co/datasets/HuggingFaceH4/helpful_instructions) is under Apache 2.0 license.
- [Databricks Dolly-15k](https://huggingface.co/datasets/databricks/databricks-dolly-15k) is under CC BY-SA 3.0 license.
Certain categories of material in the dataset include materials from the following sources, licensed under the CC BY-SA 3.0 license:
Wikipedia (various pages) - https://www.wikipedia.org/ Copyright © Wikipedia editors and contributors.
Databricks (https://www.databricks.com) Copyright © Databricks
## Language
English
## Version
Version: 1.0
To cite this dataset, please use:
```
@software{snorkel2023instructiontuning,
author = {Snorkel AI},
title = {Applying programmatic data development to Generative AI with Snorkel},
month = June,
year = 2023,
url = {https://huggingface.co/datasets/snorkelai/snorkel-curated-instruction-tuning}
}
```
**Owner: Snorkel AI, Inc.**
## Community
Join us on [Snorkel AI Slack](snorkel.ai/slack)