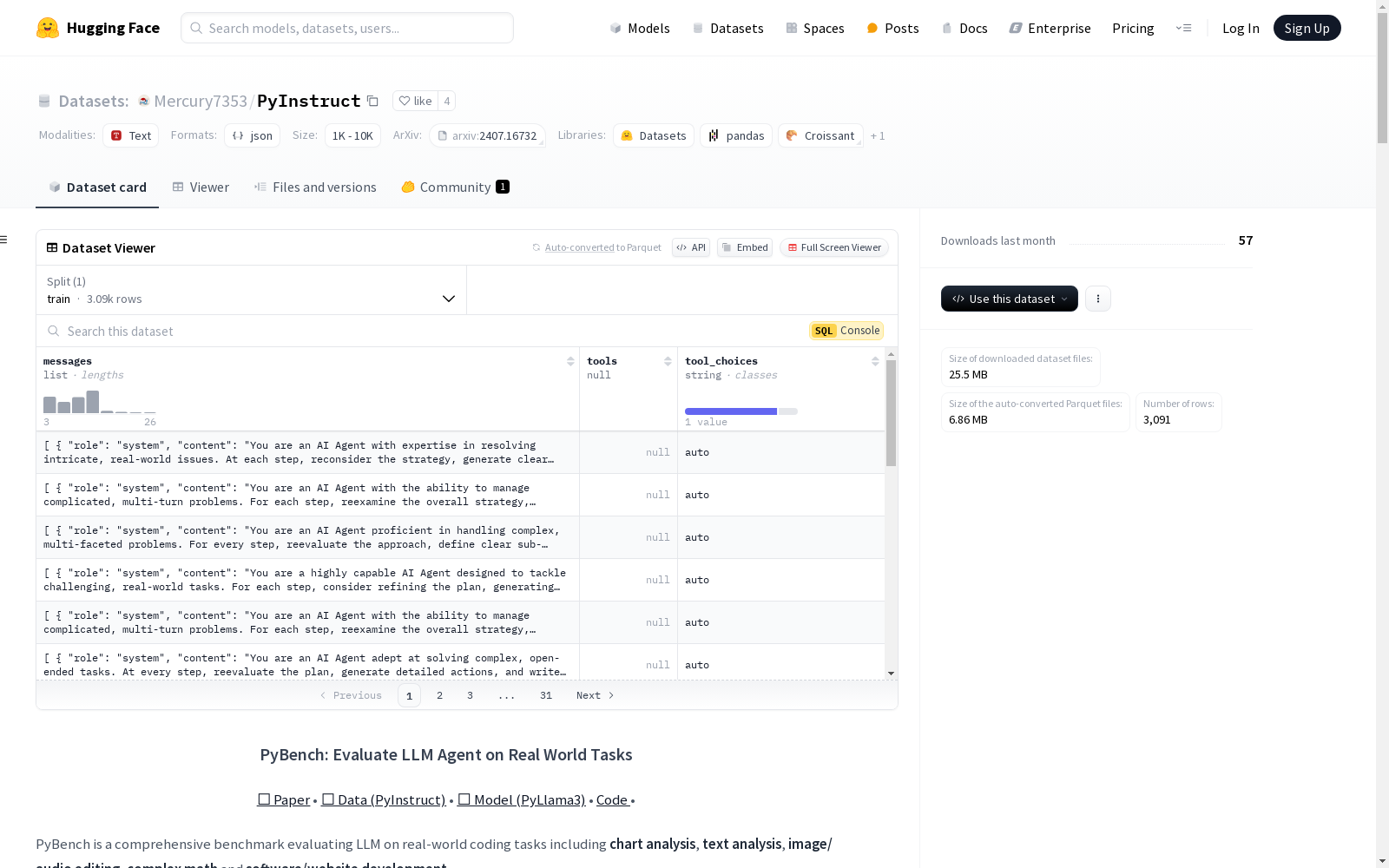
PyInstruct
收藏PyBench: Evaluate LLM Agent on Real World Tasks
数据集概述
PyBench 是一个全面的基准测试,用于评估大型语言模型(LLM)在真实世界编程任务中的表现,包括图表分析、文本分析、图像/音频编辑、复杂数学问题和软件/网站开发。该数据集从 Kaggle、arXiv 和其他来源收集文件,并根据文件的类型和内容自动生成查询。
数据集结构
- 配置名称: default
- 数据文件:
- 分割: train
- 路径: "PyInstruct.jsonl"
PyInstruct 数据集
为了提升模型在 PyBench 上的表现,我们生成了一个同源数据集:PyInstruct。PyInstruct 包含模型与文件之间的多轮交互,模拟模型在编程、调试和多轮复杂任务解决方面的能力。与其他专注于多轮编程能力的数据集相比,PyInstruct 具有更长的轮次和每个轨迹的令牌数。
数据统计
- 令牌统计: 使用 Llama-2 分词器计算。
模型训练
我们使用 PyInstruct、CodeActInstruct、CodeFeedback 和 Jupyter Notebook Corpus 对 Llama3-8B-base 进行训练,得到了 PyLlama3,该模型在 PyBench 上表现出色。
模型评估
通过 PyBench 进行模型评估,包括环境设置、模型配置、配置调整和执行过程。
引用
bibtex @misc{zhang2024pybenchevaluatingllmagent, title={PyBench: Evaluating LLM Agent on various real-world coding tasks}, author={Yaolun Zhang and Yinxu Pan and Yudong Wang and Jie Cai and Zhi Zheng and Guoyang Zeng and Zhiyuan Liu}, year={2024}, eprint={2407.16732}, archivePrefix={arXiv}, primaryClass={cs.SE}, url={https://arxiv.org/abs/2407.16732}, }