LAR-ECHR
收藏LAR-ECHR 数据集概述
数据集详情
数据集描述
- 数据集名称: LAR-ECHR
- 语言: 英语
- 任务类别: 问答
- 标签: 法律, 法律推理, 法律论证, 多选问答
- 数据集大小: n<1K
- 许可证: CC BY-NC-SA (Creative Commons / Attribution-NonCommercial-ShareAlike)
- 维护者: Odysseas S. Chlapanis
- 资助方: Archimedes Research Unit
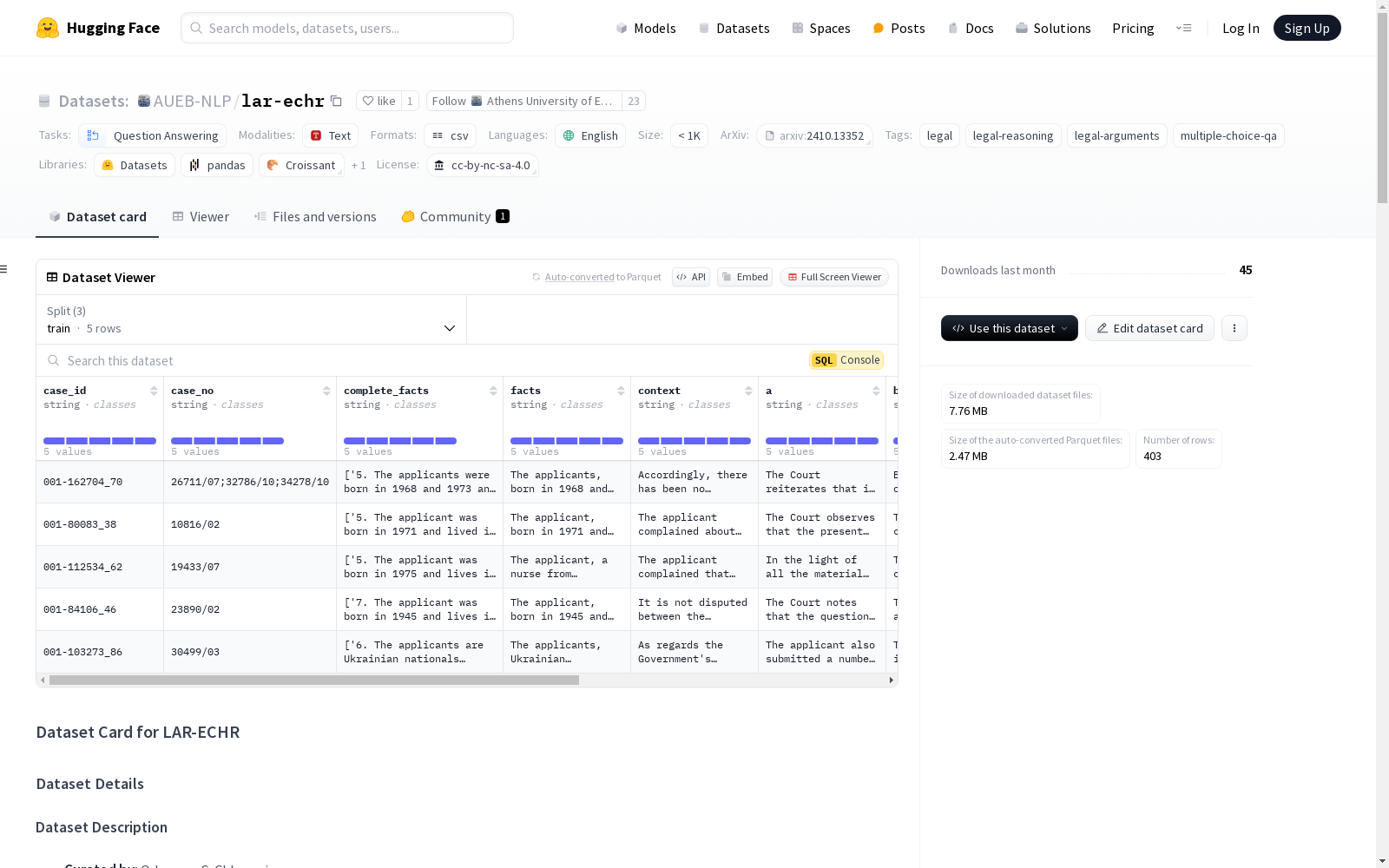
数据集结构
数据字段
case_id: (str) 案件在官方数据库中的ID,格式为 <case_id>_<paragraph_no>。case_no: (str) 案件编号。complete_facts: (List[str]) 案件完整事实的段落列表。facts: (str) 案件事实的摘要。context: (str) 前三个论证的文本。a,b,c,d: (str) 每个选项对应的论证文本。label: (str) 正确选项的大写字母 (A, B, C, D)。
数据集分割
| 分割 | 样本数量 |
|---|---|
| dev (train) | 5 |
| validation | 98 |
| test | 300 |
数据集示例
json { "case_id": "001-162704_70", "case_no": "26711/07;32710;34278/10", "complete_facts": [5. The applicants were born in 1968, 6. As established in the criminal proceedings, ...], "facts": "The applicants, born in 1968 and 1973, were involved in a criminal case", "context": "Accordingly, there has been no violation of Article 6 §§ 1", "a": "The Court reiterates that it is the master of the characterisation to be given in law", "b": "Being the master of the characterisation to be given in law to the facts", "c": "The Court recalls that it has examined the issues of fair trial under Article 6", "d": "As the requirements of Article 6 § 3 are to be seen as particular aspects of", "label": "D", }
使用说明
直接使用
[更多信息待补充]
超出范围的使用
[更多信息待补充]
数据集创建
数据集创建动机
[更多信息待补充]
源数据
数据收集与处理
[更多信息待补充]
源数据生产者
[更多信息待补充]
标注
标注过程
[更多信息待补充]
标注者
[更多信息待补充]
个人和敏感信息
[更多信息待补充]
偏差、风险和局限性
[更多信息待补充]
建议
用户应了解数据集的风险、偏差和技术局限性。更多信息待补充以提供进一步的建议。
- 1LAR-ECHR: A New Legal Argument Reasoning Task and Dataset for Cases of the European Court of Human Rights雅典经济与商业大学信息学系,语言与语音处理研究所,雅典研究与技术中心,阿基米德斯单元 · 2024年


