ViOCRVQA Dataset
收藏github2024-04-25 更新2024-05-31 收录
下载链接:
https://github.com/qhnhynmm/ViOCRVQA-Dataset
下载链接
链接失效反馈官方服务:
资源简介:
Welcome to ViOCRVQA (Vietnamese Optical Character Recognition - Visual Question Answering ) dataset! This dataset is the largest scale dataset in Vietnamese specializing in understanding text appearing in images.
ViOCRVQA contains over consisting of 28,000+ images and 120,000+ question-answer pairs. In this dataset, all the images contain text and questions about the information relevant to the text in the images.
欢迎使用越南光学字符识别-视觉问答(ViOCRVQA)数据集!该数据集是规模最大的越南语专业数据集,专注于理解图像中出现的文本。ViOCRVQA数据集包含超过28,000张图像以及120,000对问答,其中所有图像均含有与图像文本相关的信息。
创建时间:
2024-04-16
原始信息汇总
ViOCRVQA 数据集概述
数据集简介
ViOCRVQA(越南语光学字符识别 - 视觉问答)数据集是越南语中专门用于理解图像中出现的文本的最大规模数据集。
数据集内容
- 图像数量:28,282张
- 问题与答案对:123,781对
- 特点:所有图像包含文本,问题涉及图像中文本的相关信息。
数据集目的
ViOCRVQA旨在为评估越南语视觉问答(VQA)模型的阅读理解能力提供基准。
数据集重要性
理解图像中的文本对于许多实际应用至关重要,如辅助视觉障碍者、增强图像搜索引擎和提升AI对多媒体内容的理解。
数据集使用
研究人员和开发者可以使用ViOCRVQA来训练和评估他们的VQA模型,分析不同方法的性能,并推动该领域的研究进展。
数据集贡献
- 创建了越南语中针对图像中出现的文本的最大规模VQA任务数据集。
- 通过评估OCR系统的性能,分析了ViOCRVQA数据集的挑战。
- 实验表明,构建图像中对象与文本信息之间的关系是有效的。
数据集可用性
ViOCRVQA数据集将在文章被接受后提供下载。
数据集引用
如在研究中使用ViOCRVQA数据集,请引用相关论文。
搜集汇总
数据集介绍
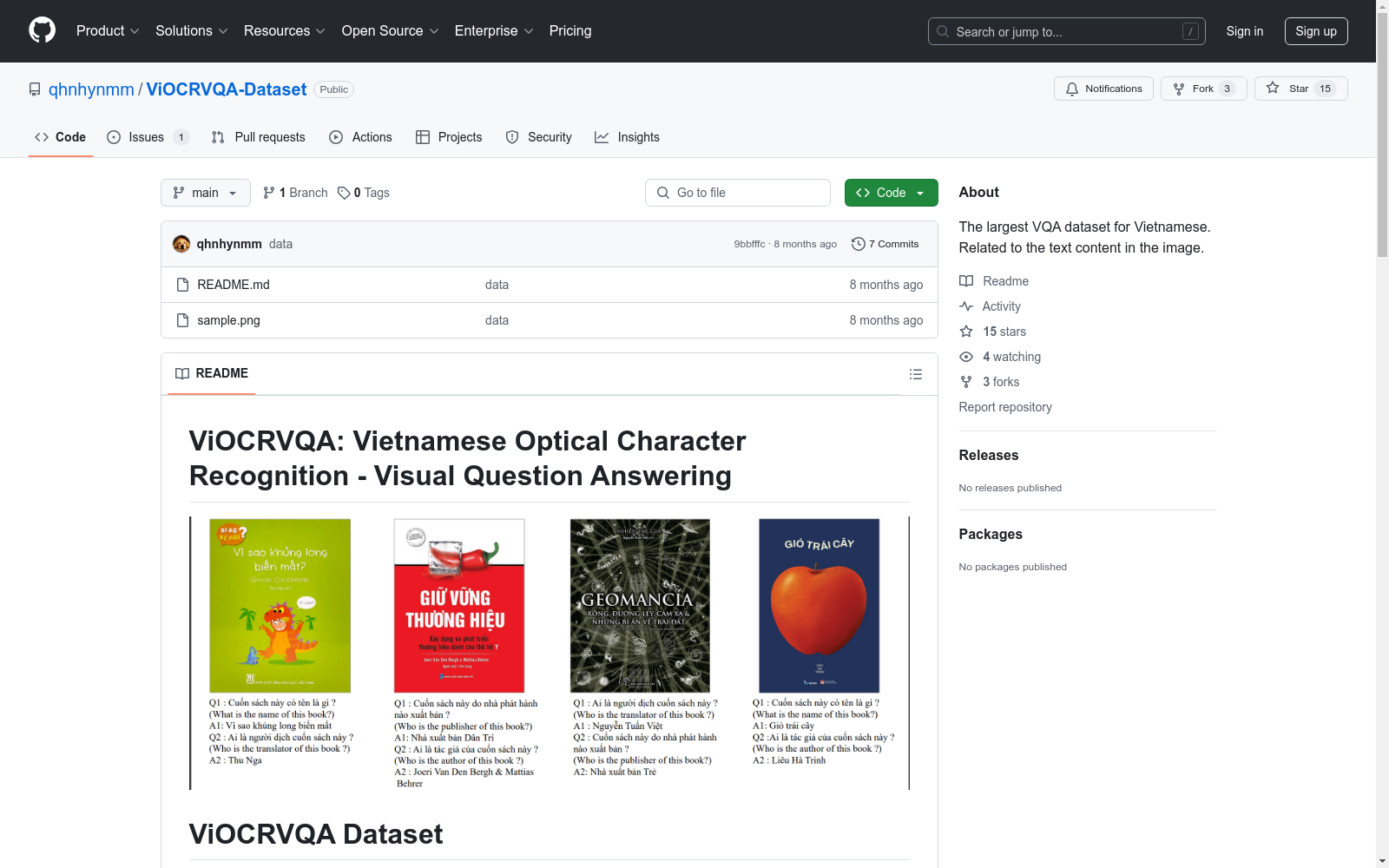
构建方式
ViOCRVQA数据集的构建旨在为越南语环境下的光学字符识别与视觉问答任务提供一个大规模的基准。该数据集精心收集了超过28,000张包含越南语文本的图像,并配以120,000多个与图像中文本信息相关的问题-答案对。通过确保图像中文字的多样性和问题的挑战性,ViOCRVQA数据集为模型理解和回答与图像文本相关的问题提供了丰富的资源。
特点
ViOCRVQA数据集的核心特点在于其专注于越南语文本的理解与视觉问答任务,填补了该领域大规模数据集的空白。数据集不仅包含大量图像和问题-答案对,还特别强调了文本与图像中其他对象之间的关系,从而提升了模型的综合理解能力。此外,数据集的多样性和挑战性使其成为评估和提升视觉问答模型性能的理想选择。
使用方法
研究人员和开发者可以利用ViOCRVQA数据集来训练和评估视觉问答模型,特别是在越南语环境下的文本理解任务。通过分析不同模型在该数据集上的表现,可以深入探讨模型在处理复杂文本与图像关系时的优缺点。此外,该数据集的开放性为学术界和工业界提供了共同推进视觉问答技术发展的平台。
背景与挑战
背景概述
ViOCRVQA数据集是由越南信息科学与工程学院的研究团队创建的,旨在推动越南语在视觉问答(VQA)领域的研究。该数据集包含超过28,000张图像和120,000多对问答对,专注于图像中文字的理解与问答任务。作为越南首个大规模的文本视觉问答数据集,ViOCRVQA填补了该领域的空白,为越南语的AI和机器学习研究提供了重要的基准。其核心研究问题在于如何有效结合光学字符识别(OCR)与视觉问答技术,以提升模型对图像中文字信息的理解能力。该数据集的发布不仅为越南语的AI研究提供了新的资源,也为全球范围内相关领域的研究者提供了宝贵的参考。
当前挑战
ViOCRVQA数据集在构建过程中面临多项挑战。首先,越南语作为一种非拉丁字母语言,其文字识别与处理相较于英语等语言更为复杂,尤其是在处理多样化的字体和书写风格时。其次,数据集的问答对设计需要确保问题的多样性和挑战性,以有效评估模型的理解能力。此外,现有的VQA模型在处理越南语时表现不佳,表明需要针对越南语特性进行专门的模型优化。最后,数据集的构建还需克服语言资源匮乏的问题,确保数据的质量和多样性,以支持广泛的研究应用。
常用场景
经典使用场景
ViOCRVQA数据集的经典使用场景主要集中在视觉问答(VQA)模型的训练与评估上。该数据集通过提供包含越南语文本的图像以及与之相关的问答对,帮助研究者开发和优化能够理解图像中文字信息的VQA模型。这种场景特别适用于需要结合光学字符识别(OCR)和自然语言处理(NLP)的任务,如图像中的文本理解与问答。
衍生相关工作
ViOCRVQA数据集的发布催生了一系列相关研究工作,特别是在越南语OCR和VQA模型的改进方面。研究者们基于该数据集提出了VisionReader模型,该模型通过构建图像中对象与文本信息之间的关系,显著提升了VQA模型的性能。此外,该数据集还激发了对多语言VQA模型通用性的研究,推动了跨语言文本识别与理解技术的进步。
数据集最近研究
最新研究方向
在视觉问答(VQA)领域,ViOCRVQA数据集的最新研究方向主要集中在提升模型对图像中越南语文本的理解能力。由于越南语的特殊性,现有的英文VQA模型在处理越南语文本时表现不佳,因此研究者们致力于开发专门针对越南语的VQA模型,如VisionReader模型。此外,研究还关注如何通过构建图像中对象与文本信息之间的关系,来增强模型的理解能力。这些研究不仅推动了越南语在AI领域的应用,也为全球多语言VQA研究提供了宝贵的参考。
以上内容由遇见数据集搜集并总结生成


