open-wikipedia-text
收藏Hugging Face2026-04-05 更新2026-04-06 收录
下载链接:
https://huggingface.co/datasets/open-index/open-wikipedia-text
下载链接
链接失效反馈官方服务:
资源简介:
Open Wikipedia (Text) 数据集包含来自多种语言维基百科的所有文章,这些文章已从原始的 MediaWiki 标记转换为干净的纯文本。所有格式、模板、引用、表格、HTML 标签和维基语法都被移除,只保留每篇文章的可读内容。数据集来源于官方的 Wikimedia 数据库转储,经过流式处理、解析和转换后,存储为按语言组织的 Apache Parquet 文件。数据集适用于文本生成、特征提取、文本分类、问答、摘要和翻译等多种任务。数据集包含 139.4K 篇文章,涵盖 1 种语言(拉丁语),采用 CC BY-SA 4.0 许可。
创建时间:
2026-04-03
原始信息汇总
Open Wikipedia (Text) 数据集概述
数据集基本信息
- 数据集名称: Open Wikipedia (Text)
- 发布者: Open Index
- 发布日期: 2026-04-03
- 许可证: Creative Commons Attribution-ShareAlike 4.0 International License (CC BY-SA 4.0)
- 数据来源: 官方 Wikimedia 数据库转储 (https://dumps.wikimedia.org/)
- 数据集地址: https://huggingface.co/datasets/open-index/open-wikipedia-text
数据集内容与规模
- 内容描述: 该数据集包含所有语言版本的维基百科文章,已从原始的 MediaWiki 标记语言转换为干净的纯文本。所有格式、模板、参考文献、表格、HTML 标签和维基语法均被剥离,仅保留每篇文章的可读内容。
- 数据规模: 包含 139.4K 篇文章,涵盖 1 种语言。
- 语言: 拉丁语 (语言代码:
la) - 数据格式: Apache Parquet 文件,采用 Zstandard 压缩。
- 数据组织: 按语言组织目录,每个目录内包含分片的 Parquet 文件。每个 Parquet 文件最多包含 500,000 行。文章数量较少的语言可容纳在单个分片中。
数据模式 (Schema)
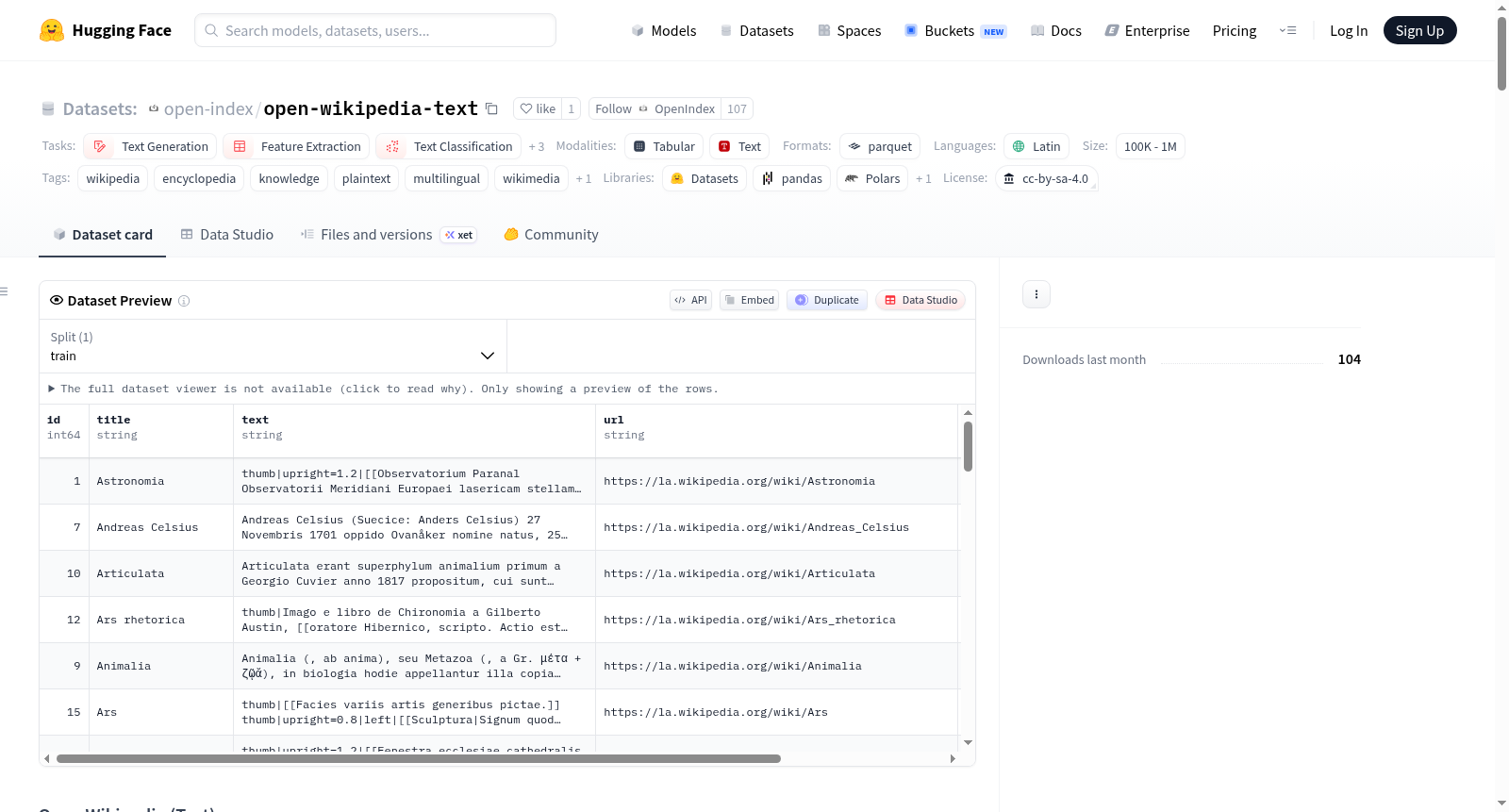
每个 Parquet 文件共享相同的模式,包含以下字段:
| 字段名 | 数据类型 | 描述 |
|---|---|---|
id |
int64 |
维基百科页面 ID,在每个语言版本中唯一。 |
title |
string |
文章标题,与维基百科上显示的一致。 |
text |
string |
文章正文的完整纯文本,所有标记已移除。 |
url |
string |
维基百科文章的直接 URL。 |
lang |
string |
ISO 639 语言代码 (例如 en, de, fr, ja)。 |
length |
int32 |
纯文本正文的长度(字节数)。 |
timestamp |
string |
最后修订时间戳 (ISO 8601 格式)。 |
数据处理流程
- 下载: 从 dumps.wikimedia.org 流式下载最新的
{lang}wiki-latest-pages-articles.xml.bz2转储文件。 - 解析: 使用流式 XML 解析器处理 bzip2 压缩的转储文件,仅保留命名空间-0 的页面(文章)。
- 剥离: 处理每篇文章的维基文本,移除所有标记、模板、表格、参考文献、HTML 和格式。维基链接被替换为其显示文本。
- 过滤: 排除转换后长度小于 100 字节的文章。
- 分片: 文章被写入 Zstandard 压缩的 Parquet 文件,每个分片约 50 万行。
- 发布: 每个语言的分片在处理完成后提交至 Hugging Face 仓库。
被移除的标记元素
所有 MediaWiki 标记元素均被移除以生成干净的纯文本,具体包括:
{{templates}}(模板):完全移除,包括信息框、导航框、分类框等。{| tables |}(表格):移除。<ref>引用:移除,包括命名引用。[[wiki links]](维基链接):仅替换为显示文本。bold/italic(粗体/斜体):替换为纯文本内容。== Headings ==(标题):仅替换为标题文本。<!-- comments -->(注释):移除。[[File:]]/[[Image:]](文件/图像):移除。[[Category:]](分类):移除。<code>,<pre>,<syntaxhighlight>(代码标签):标签标记被移除,内容作为纯文本保留。- 所有其他 HTML 标签:移除。
- 魔术字:
__NOTOC__,__FORCETOC__等指令被移除。
适用任务
该数据集适用于以下机器学习任务类别:
- 文本生成
- 特征提取
- 文本分类
- 问答
- 摘要
- 翻译
使用场景
纯文本适用于需要干净输入而无格式噪音的场景,例如:
- 文本嵌入
- 文本分类
- BM25 和关键词搜索
- 分词和词汇分析
相关数据集
- open-index/open-wikipedia-markdown: 保留 Markdown 格式的相同文章(标题、粗体、斜体、代码块和链接)。
- open-index/open-wikipedia: 原始 MediaWiki 维基文本标记格式的相同文章(包含模板、表格、参考文献等所有源元素)。
已知限制
- 转换基于正则表达式,并非完整解析器,某些复杂的维基文本结构可能留下少量痕迹。
- 模板被剥离而非展开,信息框和导航模板被完全移除。
- 代表每个语言转储的单一快照,不跟踪编辑历史。
- 并非所有语言版本的转储都始终可用。
引用方式
bibtex @dataset{open_wikipedia_text, title = {Open Wikipedia (Text)}, author = {Open Index}, year = {2026}, url = {https://huggingface.co/datasets/open-index/open-wikipedia-text}, license = {CC BY-SA 4.0}, publisher = {Hugging Face} }
搜集汇总
数据集介绍
构建方式
在知识图谱与大规模文本语料库构建领域,Open Wikipedia (Text)数据集通过系统化流程从维基百科官方数据源提炼而成。其构建始于从Wikimedia数据库转储中流式下载各语言版本的最新XML文章转储文件,随后采用流式XML解析器精准提取命名空间为0的条目文章,过滤重定向页、讨论页等非内容页面。核心转换环节利用正则表达式方法彻底剥离原始MediaWiki标记,移除所有模板、表格、参考文献、HTML标签及格式语法,仅保留可读的纯文本内容。最终,经过长度过滤的条目被分片写入经过Zstandard压缩的Parquet文件,按语言目录组织,形成结构清晰、便于高效存取的大规模多语言知识文本集合。
特点
该数据集最显著的特征在于其纯净的文本形态与严谨的多语言架构。所有文章均被转换为无任何标记干扰的纯文本,为嵌入模型训练、文本分类及信息检索等任务提供了理想的输入源。数据集涵盖多种语言版本,并以标准化Parquet格式存储,不仅支持高效压缩与快速读取,还通过包含文章ID、标题、文本、URL、语言代码、长度及时间戳的完整元数据字段,确保了数据的可追溯性与丰富维度。这种设计既保留了维基百科作为百科全书的知识广度与深度,又通过技术处理消除了结构化噪声,使其成为大规模语言模型预训练与知识密集型应用的基础语料。
使用方法
用户可通过多种灵活方式接入与利用该数据集。借助Hugging Face的`datasets`库,可直接加载特定语言分片或流式读取以节省本地存储,便于快速迭代与实验。对于需要跨语言查询或聚合分析的任务,利用DuckDB能够直接远程读取Parquet文件,执行如全文搜索、文章长度统计及语言分布分析等复杂SQL操作,无需预先下载全部数据。此外,通过`huggingface_hub`工具或CLI命令,可选择性下载指定语言的子集,适配不同存储与计算环境。数据集纯净的文本特性使其尤为适合作为句子嵌入模型的输入,用户可便捷地提取文本片段并生成语义向量,支撑检索增强生成、知识图谱构建等高级应用场景。
背景与挑战
背景概述
Open Wikipedia (Text)数据集由Open Index团队于2026年发布,旨在为自然语言处理领域提供经过清洗的纯文本维基百科语料。该数据集源自维基媒体基金会官方数据库转储,通过自动化流程剥离原始MediaWiki标记中的模板、表格、引用及格式元素,仅保留可读内容。其核心研究问题聚焦于为文本生成、特征提取、分类、问答及摘要等任务提供高质量、多语言的基准数据,从而推动大规模语言模型与知识密集型应用的发展。作为开放知识的重要载体,该数据集在促进跨语言信息检索与语义理解方面展现出显著影响力。
当前挑战
该数据集致力于解决多语言文本处理中格式噪声干扰语义表达的挑战,例如原始维基百科标记中的复杂模板与链接结构会降低嵌入模型与分类器的性能。在构建过程中,面临的主要挑战包括:基于正则表达式的转换方法难以完全解析某些复杂维基文本结构,可能导致残留标记;模板被直接移除而非展开,损失了部分结构化信息;且数据仅代表特定时间点的快照,无法捕捉版本演变历史。此外,不同语言版本的数据可用性差异也为全面覆盖带来限制。
常用场景
经典使用场景
在自然语言处理领域,大规模文本语料库是模型训练与评估的基石。Open Wikipedia (Text)数据集以其纯净的文本形式,为语言模型的预训练提供了理想素材。研究者常利用其海量、多语言的百科条目,对模型进行自监督学习,如掩码语言建模或下一句预测,以构建深层的语言理解能力。该数据集经过精心处理,移除了所有维基标记和格式噪音,确保了输入文本的整洁性,从而提升了模型学习语义表示的效率与质量。
衍生相关工作
基于此类高质量维基百科文本数据,学术界已催生了一系列经典工作。例如,BERT、RoBERTa等里程碑式的预训练语言模型均在其训练流程中大量使用了维基百科文本。后续的T5、BART等生成式模型,以及像DPR这样的稠密段落检索模型,也将其作为关键训练数据。这些工作共同推动了自然语言处理从特定任务模型向通用大语言模型的范式转变,奠定了当前人工智能对话与理解系统的技术基础。
数据集最近研究
最新研究方向
在自然语言处理领域,大规模多语言文本数据集正成为推动前沿模型发展的关键资源。Open Wikipedia (Text)数据集以其纯净的文本格式,为多语言大语言模型的预训练与微调提供了高质量语料。当前研究热点聚焦于利用此类数据增强模型的跨语言知识迁移能力,特别是在低资源语言如拉丁语的表示学习方面。该数据集通过去除维基百科原始标记噪声,优化了文本嵌入的语义一致性,为知识密集型任务如开放域问答与事实核查提供了可靠基础。其结构化存储与高效访问设计,也促进了分布式计算环境下的大规模语料分析,对构建更透明、可解释的人工智能系统具有深远意义。
以上内容由遇见数据集搜集并总结生成


