Sarathi-AgriData
收藏Hugging Face2026-01-16 更新2026-01-17 收录
下载链接:
https://huggingface.co/datasets/soketlabs/Sarathi-AgriData
下载链接
链接失效反馈官方服务:
资源简介:
该数据集是一个高质量的农业咨询合成数据集,专为训练适用于印度农业背景的大型语言模型(LLMs)而设计。与标准合成数据集不同,该数据通过多阶段管道生成,严格分离科学验证和内容生成,确保模型仅针对已证明科学可行的场景生成建议。数据集特点包括预验证场景、思维链(CoT)、严格的安全防护措施和多样化的角色(如“村庄长者”、“地区官员”、“广播播报”)。数据生成过程包括五个阶段:合成束构建、生物可行性分析、系统指令合成、批量推理与防护措施、解析与结构化。数据集结构包括唯一的记录ID、输入提示(作物、地区、土壤、压力因素、耕作方式、生长阶段)、系统指令、模型思考过程和最终建议(印地语)。
创建时间:
2026-01-12
原始信息汇总
Agri-Advisory Synthetic Dataset (Hindi) 数据集概述
1. 数据集元数据
| 指标 | 值 |
|---|---|
| 总数据点 | 220,222 |
| 数据集大小 (JSONL) | 2.61GB |
| 数据集大小 (Parquet) | 945MB |
| 语言 | 印地语 (目标输出),英语 (内部推理/元数据) |
| 任务类别 | Instruction Tuning, Chain-of-Thought, Agricultural Advisory |
| 源模型 | Google Gemini 2.5 Flash |
2. 数据集简介
该数据集包含高质量的、经过生物学验证的农业咨询数据,旨在为印度农业背景训练大语言模型。
与标准合成数据集不同,此数据采用多阶段流水线生成,该流程将科学验证与内容生成严格分离。这确保了模型仅尝试为已被科学证明可行的场景撰写咨询。
关键特性:
- 预先验证的场景: 每个输入场景在生成开始前都经过了生物学可行性评分。
- 思维链: 包含模型的内部推理步骤以及最终咨询。
- 严格的安全护栏: 强制执行有机农业与化学农业实践的具体协议。
- 多样化角色: 咨询的语气多样(例如,“乡村长老”、“地区官员”、“广播播报”)。
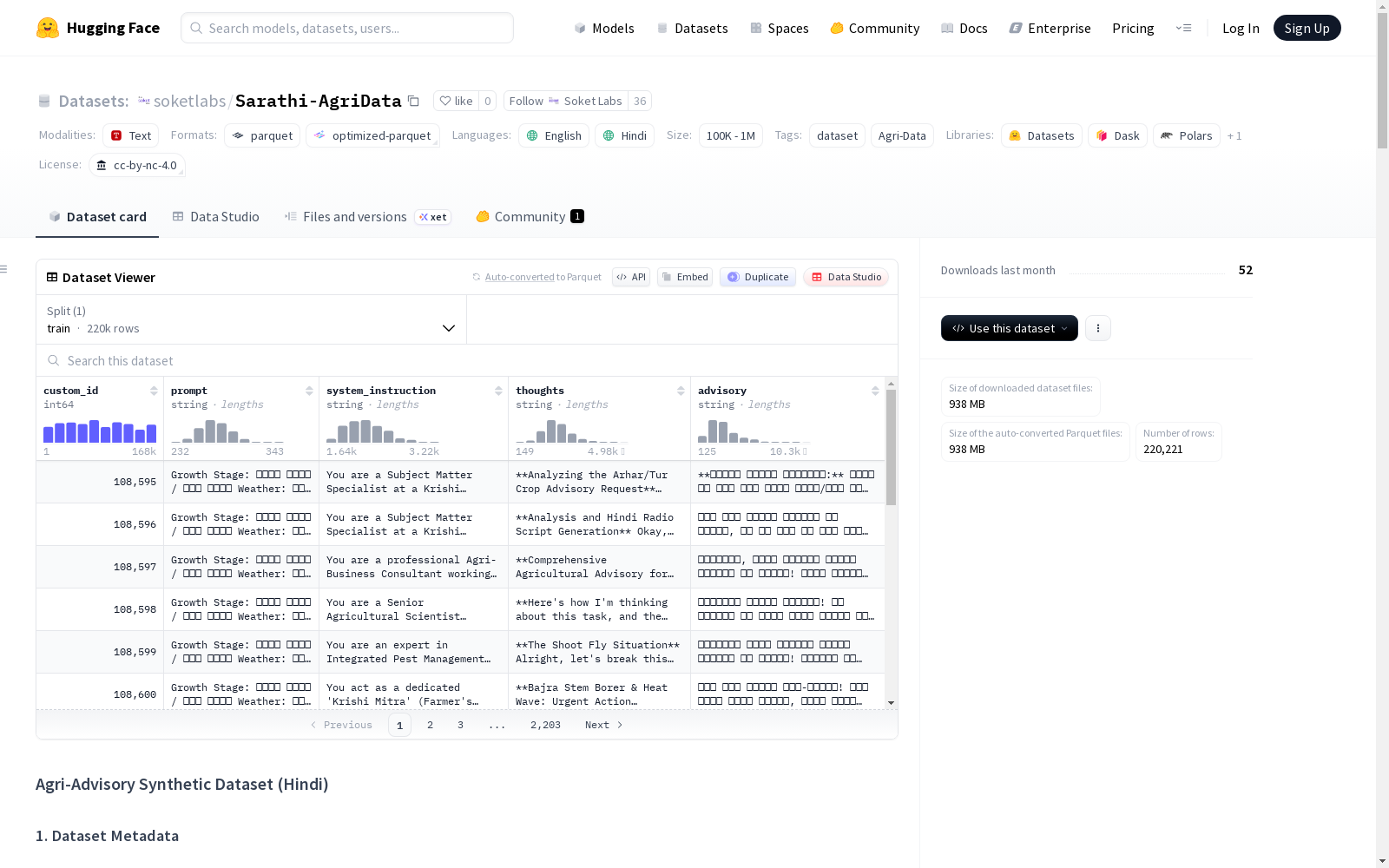
3. 数据结构(模式)
数据集中的每条记录包含以下字段: json { "custom_id": "唯一记录标识符", "prompt": { "crop": "作物名称", "region": "地区", "soil": "土壤类型", "stress": "胁迫因素", "farming_practice": "耕作方式", "growth_stage": "生长阶段" }, "system_instruction": "系统指令,定义角色和风格", "thoughts": "模型内部推理步骤(英语)", "advisory": "最终咨询(印地语)" }
4. 许可证
- 许可证类型: CC-BY-NC-4.0
搜集汇总
数据集介绍
构建方式
在农业智能化领域,高质量数据集的构建是推动大语言模型精准服务的关键。Sarathi-AgriData数据集通过一个精心设计的五阶段流水线生成,确保了数据的科学性与实用性。首先,基于作物、区域、土壤类型等结构化分类体系,采用组合逻辑生成多样化的初始场景束。随后,引入专门的验证代理,利用轻量级大语言模型对每个场景进行生物学可行性评估,仅保留置信度高于阈值的合理组合。在此基础上,通过模块化指令合成系统,为不同应用场景生成具有特定语调和格式的系统提示。最后,利用已验证的场景束和个性化指令,通过批量推理生成包含内部推理链和最终农业建议的完整数据,并经过解析与结构化处理,形成标准化的训练样本。
特点
该数据集在农业咨询领域展现出多方面的显著特点。其核心在于采用了预验证机制,所有输入场景在生成建议前均经过严格的生物学可行性评分,有效过滤了不科学或矛盾的组合,从而保障了数据的内在质量。数据集不仅提供了最终的农业建议输出,还完整保留了模型生成建议时的内部推理步骤,即思维链,这为模型的可解释性研究和指令微调提供了宝贵资源。此外,数据生成过程嵌入了明确的安全护栏,严格区分有机与常规农业实践,并在涉及化学品时强制包含安全警告。输出风格也极具多样性,通过模拟不同身份角色和媒介,生成了适用于文本对话或语音广播等多种应用场景的咨询内容。
使用方法
对于研究人员和开发者而言,该数据集为训练面向印度农业背景的专家型语言模型提供了直接支持。数据集以JSONL和Parquet两种格式提供,每条记录均包含唯一的自定义ID、结构化的输入提示、系统指令、模型思维链以及最终以印地语呈现的农业建议。使用者可直接将其用于大语言模型的指令微调任务,特别是专注于链式思维推理和农业领域专业内容生成的模型训练。在应用时,可根据‘prompt’字段中的作物、压力因素等关键信息构建训练样本,利用‘thoughts’字段监督模型的推理过程,并以‘advisory’字段作为训练目标。数据集内嵌的多样化系统指令也为研究模型在不同人设和输出格式下的表现提供了便利。
背景与挑战
背景概述
在人工智能与农业科学交叉融合的背景下,农业咨询数据集的构建成为推动智慧农业发展的关键。Sarathi-AgriData数据集由Soket AI与印度理工学院甘地讷格尔分校合作,于近期作为Project EKΛ倡议的一部分发布,旨在为印度农业场景训练大型语言模型提供高质量、经过生物学验证的合成数据。该数据集聚焦于农业咨询任务,通过指令微调与思维链技术,生成涵盖作物、区域、土壤类型及生长阶段等多维度的个性化农事建议,其核心研究问题在于如何确保人工智能模型在复杂农业环境中输出科学准确、文化适配且安全可靠的咨询内容,对提升多语言农业AI系统的实用性与包容性具有显著影响力。
当前挑战
该数据集致力于解决农业咨询领域智能化所面临的挑战,主要包括:确保生成建议的农业科学准确性,避免因模型幻觉导致有害或无效的推荐;处理印度农业场景的高度复杂性,如作物-病虫害-环境的精准映射与地域性知识的整合;以及满足多模态输出需求,平衡文本聊天与语音广播等不同交付形式的内容生成。在构建过程中,挑战体现在设计并执行严格的多阶段生成流水线,以分离科学验证与内容生成,从而过滤生物学上不可行的场景;同时,维护数据的安全护栏,强制区分有机与常规耕作实践的建议,并确保所有化学推荐附带安全警告,以符合伦理与实用标准。
常用场景
经典使用场景
在农业人工智能领域,Sarathi-AgriData数据集为大型语言模型的指令微调提供了典范。该数据集通过多阶段生成流程,构建了涵盖作物、区域、土壤类型、天气事件及生长阶段等维度的多样化农业咨询场景。其核心应用在于训练模型生成符合印度农业背景的高质量、生物学验证的农事建议,特别强调链式思维推理与安全护栏机制,确保输出既科学准确又贴合实际农作需求。
衍生相关工作
该数据集为Project EKΛ等主权AI计划提供了关键训练资源,催生了面向印度多语言环境的农业大模型研发。其多阶段验证流程启发了后续工作对合成数据质量控制方法的改进,而模块化人物设定机制则促进了领域自适应提示工程的研究。相关成果已延伸至病虫害诊断、气候韧性农艺推荐等垂直场景,形成了以可信AI为核心的农业决策支持技术生态。
数据集最近研究
最新研究方向
在农业人工智能领域,Sarathi-AgriData数据集以其独特的生物学验证合成方法,正推动多语言农业咨询模型的精细化发展。该数据集通过分离科学验证与内容生成的多阶段流程,确保了大语言模型在印度农业情境下输出建议的科学严谨性。前沿研究聚焦于结合链式思维推理与多样化人物角色,以优化文本转语音和聊天机器人等不同模态的应用性能。这一工作与Project EKΛ等本土化AI倡议紧密相连,旨在构建支持印地语等本地语言的、安全可靠的农业智能体,为资源受限地区的农民提供个性化、可操作的农艺指导,体现了AI技术向包容性、领域专业化发展的趋势。
以上内容由遇见数据集搜集并总结生成


