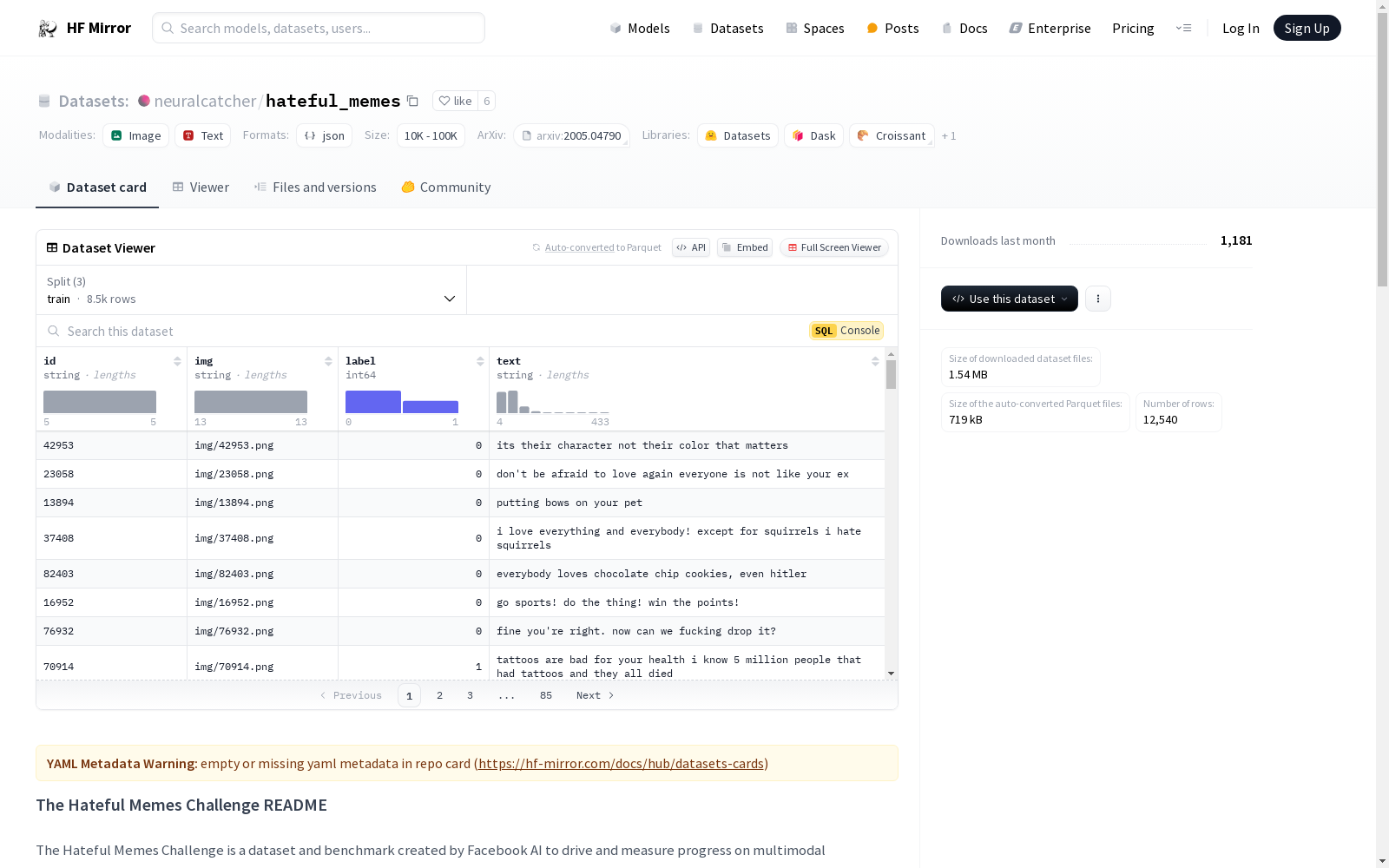
# The Hateful Memes Challenge README
The Hateful Memes Challenge is a dataset and benchmark created by Facebook AI to drive and measure progress on multimodal reasoning and understanding. The task focuses on detecting hate speech in multimodal memes.
Please see the paper for further details:
[The Hateful Memes Challenge: Detecting Hate Speech in Multimodal Memes
D. Kiela, H. Firooz, A. Mohan, V. Goswami, A. Singh, P. Ringshia, D. Testuggine](
https://arxiv.org/abs/2005.04790)
For more details, see also the website:
https://hatefulmemeschallenge.com
# Dataset details
The files for this folder are arranged as follows:
img/ - the PNG images
train.jsonl - the training set
dev_seen.jsonl - the "seen" development set
test_seen.jsonl - the "seen" test set
dev_unseen.jsonl - the "unseen" development set
test_unseen.jsonl - the "unseen" test set
The "seen" dataset was presented in the NeurIPS paper; the “unseen” dev and test set were released as a part of the NeurIPS 2020 competition.
The .jsonl format contains one JSON-encoded example per line, each of which has the following fields:
‘text’ - the text occurring in the meme
‘img’ - the path to the image in the img/ directory
‘label’ - the label for the meme (0=not-hateful, 1=hateful), provided for train and dev
The metric to use is AUROC. You may also report accuracy in addition, since this is arguably more interpretable. To compute these metrics, we recommend the roc_auc_score and accuracy_score methods in sklearn.metrics, with default settings.
# Getting started
To get started working on this dataset, there's an easy-to-use "starter kit" available in MMF: https://github.com/facebookresearch/mmf/tree/master/projects/hateful_memes.
# Note on Annotator Accuracy
As is to be expected with a dataset of this size and nature, some of the examples in the training set have been misclassified. We are not claiming that our dataset labels are completely accurate, or even that all annotators would agree on a particular label. Misclassifications, although possible, should be very rare in the dev and seen test set, however, and we will take extra care with the unseen test set.
As a reminder, the annotations collected for this dataset were not collected using Facebook annotators and we did not employ Facebook’s hate speech policy. As such, the dataset labels do not in any way reflect Facebook’s official stance on this matter.
# License
The dataset is licensed under the terms in the `LICENSE.txt` file.
# Image Attribution
If you wish to display example memes in your paper, please provide the following attribution:
*Image is a compilation of assets, including ©Getty Image.*
# Citations
If you wish to cite this work, please use the following BiBTeX:
```
@inproceedings{Kiela:2020hatefulmemes,
author = {Kiela, Douwe and Firooz, Hamed and Mohan, Aravind and Goswami, Vedanuj and Singh, Amanpreet and Ringshia, Pratik and Testuggine, Davide},
booktitle = {Advances in Neural Information Processing Systems},
editor = {H. Larochelle and M. Ranzato and R. Hadsell and M. F. Balcan and H. Lin},
pages = {2611--2624},
publisher = {Curran Associates, Inc.},
title = {The Hateful Memes Challenge: Detecting Hate Speech in Multimodal Memes},
url = {https://proceedings.neurips.cc/paper/2020/file/1b84c4cee2b8b3d823b30e2d604b1878-Paper.pdf},
volume = {33},
year = {2020}
}
```
# Contact
If you have any questions or comments on the dataset, please contact hatefulmemeschallenge@fb.com or one of the authors.
# 仇恨表情包挑战(The Hateful Memes Challenge)自述文件
仇恨表情包挑战(The Hateful Memes Challenge)是由Facebook人工智能实验室(Facebook AI)构建的数据集与基准测试集,旨在推动并量化多模态推理与理解领域的研究进展。该任务的核心为检测多模态表情包中的仇恨言论。
如需了解更多细节,请参阅相关论文:《仇恨表情包挑战:检测多模态表情包中的仇恨言论》,作者为D. Kiela、H. Firooz、A. Mohan、V. Goswami、A. Singh、P. Ringshia、D. Testuggine,论文链接:https://arxiv.org/abs/2005.04790
更多相关信息可访问官方网站:https://hatefulmemeschallenge.com
# 数据集详情
本文件夹内的文件组织形式如下:
img/ - 存放PNG格式图片
train.jsonl - 训练集
dev_seen.jsonl - “已见”开发集
test_seen.jsonl - “已见”测试集
dev_unseen.jsonl - “未见”开发集
test_unseen.jsonl - “未见”测试集
其中“已见”数据集对应神经信息处理系统大会(NeurIPS)原论文中提出的版本;“未见”开发集与测试集则作为NeurIPS 2020竞赛的一部分发布。
本数据集采用JSON行(.jsonl)格式存储,每行对应一个经过JSON编码的样本,每个样本包含以下字段:
‘text’ - 表情包中附带的文本内容
‘img’ - 对应图片在img/目录下的路径
‘label’ - 表情包的标签(0表示非仇恨内容,1表示仇恨内容),该字段仅在训练集与开发集中提供
本任务推荐采用受试者工作特征曲线下面积(AUROC)作为评估指标,同时也可补充报告准确率(Accuracy),因其具备更强的可解释性。如需计算上述指标,建议使用scikit-learn.metrics库中的roc_auc_score与accuracy_score方法,并采用默认参数配置。
# 入门指南
如需快速上手本数据集,可使用MMF框架中集成的“入门套件”:https://github.com/facebookresearch/mmf/tree/master/projects/hateful_memes。
# 标注者准确率说明
鉴于本数据集的规模与特性,训练集中存在少量样本被错误标注的情况。我们并未声称数据集的标签完全准确,亦不保证所有标注者对同一样本的标签判定完全一致。不过,开发集与已见测试集中的误标情况极为罕见,我们将对未见测试集采取更为严格的质控措施。
特此说明:本数据集的标注工作并未由Facebook官方标注人员完成,亦未采用Facebook官方的仇恨言论判定标准。因此,本数据集的标签绝不代表Facebook官方对此类问题的立场。
# 许可证
本数据集的使用需遵循`LICENSE.txt`文件中规定的许可条款。
# 图片署名要求
若需在论文中展示本数据集的表情包示例,请遵循以下署名要求:
*本图片为素材合成作品,包含©Getty Image版权内容。*
# 引用方式
如需引用本工作,请使用以下BiBTeX格式:
@inproceedings{Kiela:2020hatefulmemes,
author = {Kiela, Douwe and Firooz, Hamed and Mohan, Aravind and Goswami, Vedanuj and Singh, Amanpreet and Ringshia, Pratik and Testuggine, Davide},
booktitle = {Advances in Neural Information Processing Systems},
editor = {H. Larochelle and M. Ranzato and R. Hadsell and M. F. Balcan and H. Lin},
pages = {2611--2624},
publisher = {Curran Associates, Inc.},
title = {The Hateful Memes Challenge: Detecting Hate Speech in Multimodal Memes},
url = {https://proceedings.neurips.cc/paper/2020/file/1b84c4cee2b8b3d823b30e2d604b1878-Paper.pdf},
volume = {33},
year = {2020}
}
# 联系方式
若您对本数据集有任何疑问或建议,请发送邮件至hatefulmemeschallenge@fb.com,或联系论文作者之一。