tsunghanwu/berkeley-grafiq-dataset
收藏Hugging Face2026-05-01 更新2026-05-03 收录
下载链接:
https://hf-mirror.com/datasets/tsunghanwu/berkeley-grafiq-dataset
下载链接
链接失效反馈官方服务:
资源简介:
Berkeley GRAFIQ是一个合成的视觉问答基准数据集,用于评估视觉语言模型在3D渲染属性(深度、表面粗糙度、法线方向、光照方向)上的表现。数据集包含多个文件,包括渲染文件夹和基准测试文件,支持四种二选一的强制选择任务类型。
Berkeley GRAFIQ is a synthetic VQA benchmark for evaluating vision-language models on 3D rendering properties (depth, surface roughness, normal orientation, light direction). The dataset includes multiple files such as render directories and benchmark files, supporting four binary Left vs Right forced choice tasks.
提供机构:
tsunghanwu
搜集汇总
数据集介绍
构建方式
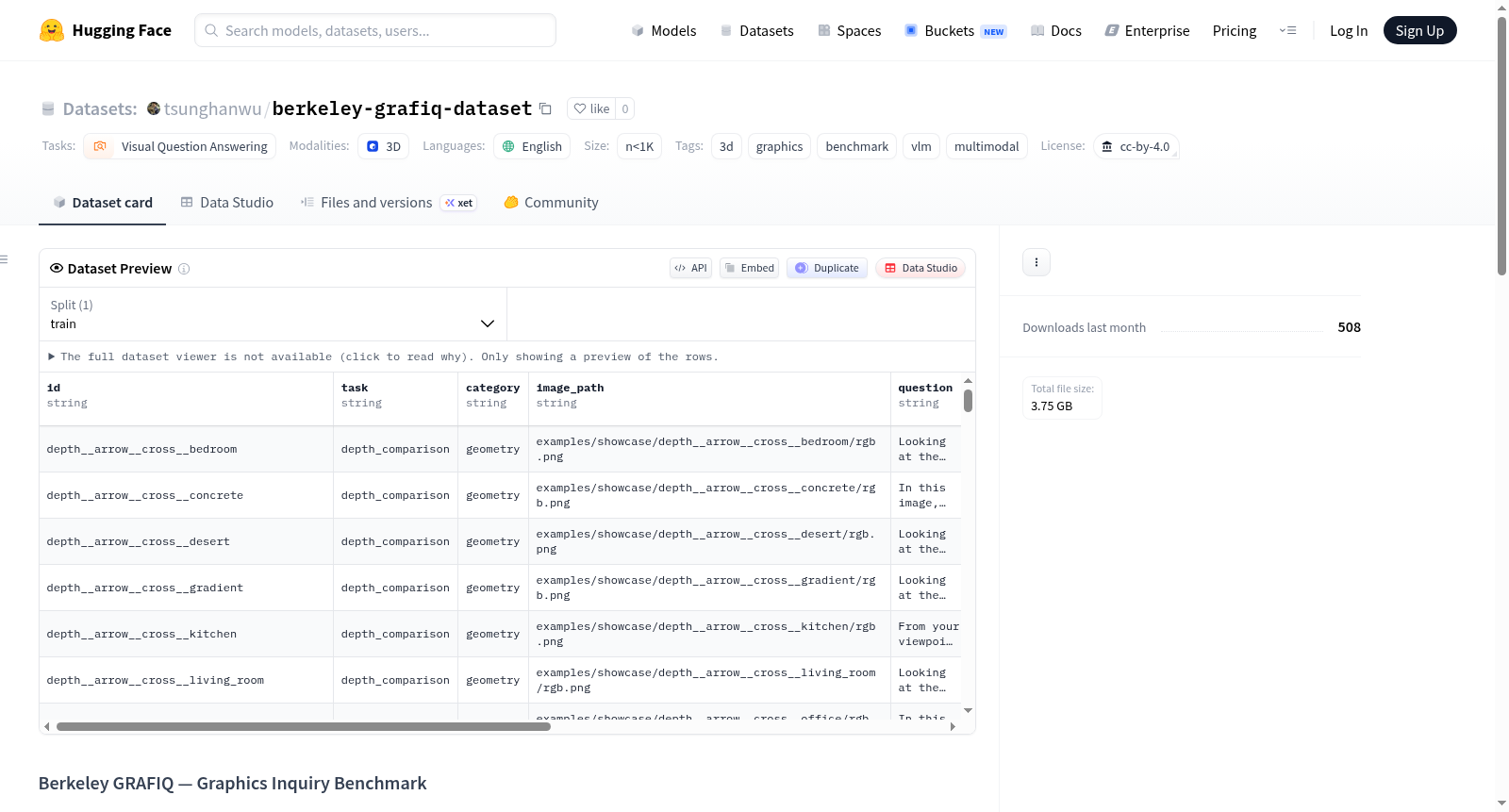
Berkeley GRAFIQ数据集是由加州大学伯克利分校团队精心构建的合成视觉问答基准,专为评估视觉语言模型在三维渲染属性理解上的能力而设计。该数据集基于grafiq_datagen开源仓库中的showcase文件夹内容,通过打包为单个tar文件以适配免费版HuggingFace上传限制。包含原始的276项基准版本、经筛选后的227项版本,以及平衡后的480项基准版本(每项任务120项),每个渲染目录内含RGB图像、任务元数据与经像素验证器确认的问答记录。
特点
该数据集聚焦于四大核心三维渲染属性:深度比较、表面粗糙度对比、法线方向判断以及光源方向识别,以二元左-右强制选择形式呈现。其独特之处在于结合了合成渲染控制与严格的质量验证机制,每个问答项均经过像素级验证器确认,并附带原始验证指标的详细证据。数据集规模虽小(不足千项),但针对视觉语言模型在三维空间理解这一前沿挑战提供了高精度的专业评估手段。
使用方法
使用者可通过HuggingFace Hub便捷获取数据集资源。首先利用huggingface_hub库中的hf_hub_download函数下载轻量级基准文件benchmark_v2.jsonl,并解析为JSON对象列表以供模型评估。若需实际图像数据,可下载showcase.tar文件并解压至指定目录,每个渲染文件夹中的rgb.png即为待评估图像,qa_item.json则提供经过验证的标准答案及详细指标用于性能计算。
背景与挑战
背景概述
Berkeley GRAFIQ数据集(Graphics Inquiry Benchmark)由加州大学伯克利分校的研究团队于近年创建,旨在评估视觉语言模型(VLM)对三维渲染属性的理解能力。该数据集聚焦于深度比较、表面粗糙度、法线方向及光照方向四项核心任务,通过合成图像与二元强制选择问答形式,填补了视觉问答领域在三维图形学推理方面的空白。作为首个系统性地检验多模态模型底层三维感知能力的基准,Berkeley GRAFIQ为分析模型在几何与材质属性上的推理局限性提供了关键工具,推动了视觉语言模型从粗粒度图像识别向精细空间与物理属性理解的演进。
当前挑战
该数据集面临的核心挑战在于所解决的领域问题:视觉语言模型普遍缺乏对三维场景中几何与材质属性的显式推理能力,现有基准多集中于二维语义或常识问答,难以检测模型在深度、粗糙度等连续物理参数上的判断精度。构建过程中的挑战则包括:合成渲染需要高保真物理模拟以确保视觉真实性,但数据生成流程复杂且计算成本高昂;精心设计的二元选择题需通过像素验证器严格筛选以避免语义歧义,导致原始276项基准中约18%的条目被过滤;后续发布的平衡版本v2虽提升了任务间公平性,但480项的小规模仍在泛化性评估上存在局限。
常用场景
经典使用场景
在三计算机视觉与图形学交叉领域中,Berkeley GRAFIQ数据集被广泛用作评估多模态大模型对三维渲染属性理解能力的基准。该数据集通过精心设计的视觉问答任务,迫使模型对深度、表面粗糙度、法线方向以及主光源方向等底层几何与光照特征做出二元判断,从而检验其是否真正捕捉到了三维场景的内在物理属性,而非仅依赖于纹理或颜色等表面线索。
衍生相关工作
该数据集的发布催生了一系列关于三维感知能力诊断与增强的后续研究。其设计理念被扩展至更复杂的场景,例如后续工作引入了动态光照变化、透明材质以及全局光照效果,构建了更具挑战性的三维推理评估体系。同时,该数据集也激发了若干针对性训练策略的提出,如通过监督式几何先验嵌入或多任务联合学习,旨在填补基准测试所暴露出的模型在法线与粗糙度感知上的关键短板,推动了三维感知模块与语言模型的深度耦合。
数据集最近研究
最新研究方向
Berkeley GRAFIQ数据集聚焦于多模态视觉语言模型在三维渲染属性理解上的评估,涵盖深度比较、表面粗糙度、法线方向与光照方向等视觉推理任务。当前前沿研究借助此类合成VQA基准,系统性地探测视觉语言模型在基础3D几何与材质感知方面的能力边界,揭示大模型在物理世界属性推理上的瓶颈。该数据集的构建契合了具身智能与数字孪生领域对感知模型可解释性与鲁棒性的迫切需求,为推动多模态模型从二维视觉模式向三维空间理解的跃迁提供了标准化的评测工具。
以上内容由遇见数据集搜集并总结生成


