NL2SQL-BUGs
收藏github2025-03-19 更新2025-03-20 收录
下载链接:
https://github.com/HKUSTDial/NL2SQL-Bugs-Benchmark
下载链接
链接失效反馈官方服务:
资源简介:
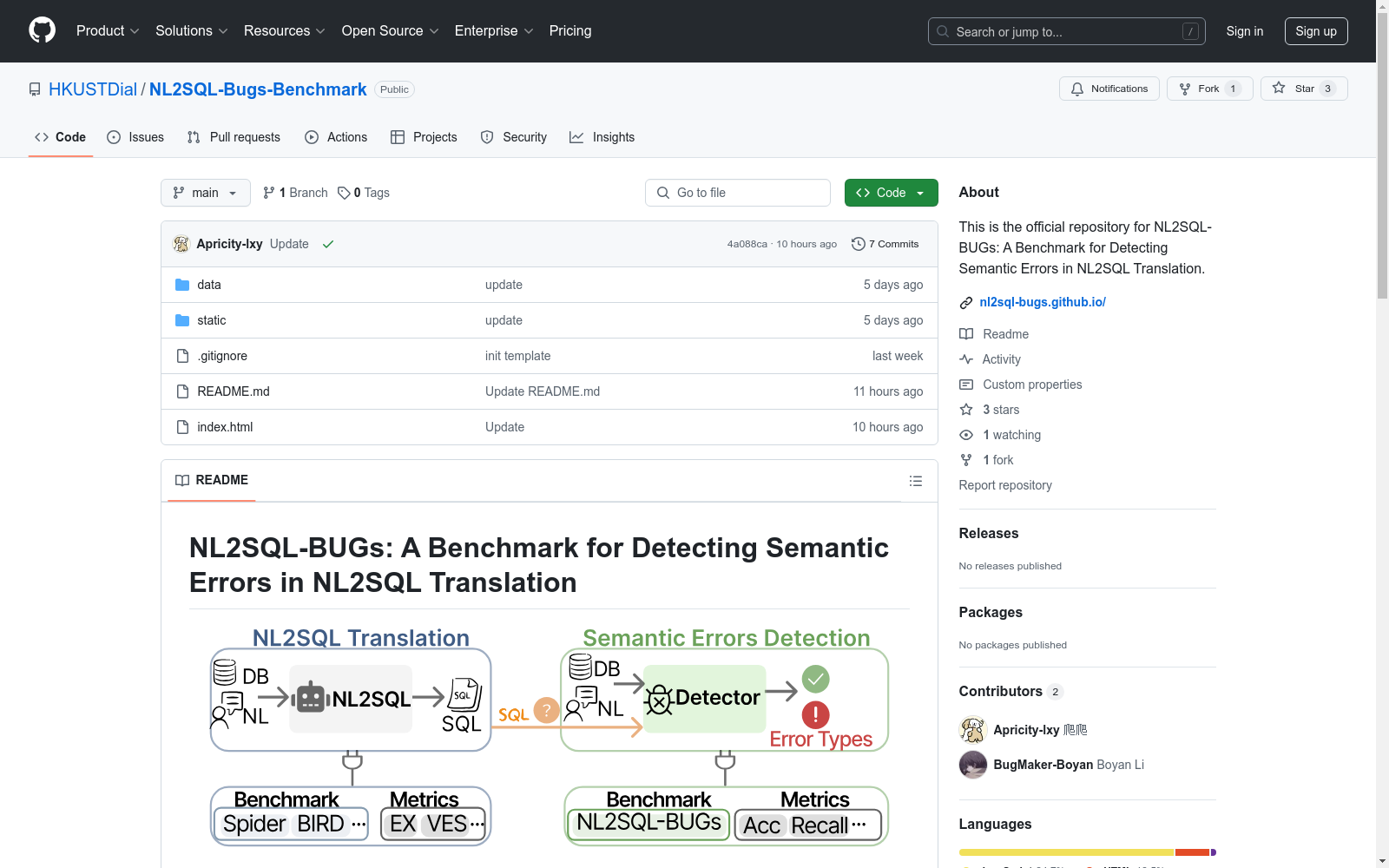
NL2SQL-BUGs是一个专门用于检测和分类自然语言到SQL(NL2SQL)翻译中语义错误的基准。该基准旨在支持语义错误检测的研究,这是任何后续错误纠正的前提。数据集包含2,018个实例,其中1,019个是正确的示例,999个是语义错误的示例。每个错误示例都详细注释了特定的错误类型。
NL2SQL-BUGs is a benchmark specifically designed for detecting and classifying semantic errors in natural language to SQL (NL2SQL) translation. This benchmark aims to support research on semantic error detection, which is a prerequisite for any subsequent error correction. The dataset contains 2,018 instances, among which 1,019 are correct examples and 999 are examples with semantic errors. Each erroneous example is comprehensively annotated with a specific error type.
创建时间:
2025-03-14
原始信息汇总
NL2SQL-BUGs 数据集概述
数据集简介
NL2SQL-BUGs 是一个专门用于检测和分类自然语言到SQL(NL2SQL)翻译中语义错误的基准数据集。该数据集旨在支持语义错误检测的研究,这是任何后续错误纠正的前提。
数据集特点
- 两级分类系统:包含9个主要类别和31个子类别的语义错误分类系统。
- 专家标注数据集:包含2,018个实例,其中1,019个为正确示例,999个为语义错误的示例。
- 详细的错误标注:每个错误示例都详细标注了具体的错误类型。
数据统计
- 总实例数:2,018
- 正确示例数:1,019
- 错误示例数:999
- 主要错误类别数:9
- 错误子类别数:31
数据集下载
数据集与BIRD基准一致,可通过以下方式下载:
NL2SQL-BUGs 的标签和错误类型可在 ./data/ 目录下找到。
评估指标
语义错误检测性能的评估指标包括:
- 总体准确率:正确识别的实例(正确或错误)的百分比。
- 负例精确率(NP):预测为错误的实例中实际为错误的比例。
- 负例召回率(NR):实际为错误的实例中被正确预测为错误的比例。
- 正例精确率(PP):预测为正确的实例中实际为正确的比例。
- 正例召回率(PR):实际为正确的实例中被正确预测为正确的比例。
- 类型特定准确率(TSA):每种特定错误类型的准确率。
引用
如果您在研究中使用了NL2SQL-BUGs,请引用以下论文: bibtex @misc{liu2025nl2sqlbugsbenchmarkdetectingsemantic, title={NL2SQL-BUGs: A Benchmark for Detecting Semantic Errors in NL2SQL Translation}, author={Xinyu Liu and Shuyu Shen and Boyan Li and Nan Tang and Yuyu Luo}, year={2025}, eprint={2503.11984}, archivePrefix={arXiv}, primaryClass={cs.DB}, url={https://arxiv.org/abs/2503.11984}, }
搜集汇总
数据集介绍
构建方式
NL2SQL-BUGs数据集的构建基于对自然语言到SQL(NL2SQL)翻译过程中语义错误的系统检测与分类。该数据集包含了2,018个实例,其中1,019个为正确示例,999个为带有语义错误的示例。每个错误示例均经过专家详细标注,涵盖了9个主要类别和31个子类别的语义错误。数据集的构建过程严格遵循BIRD基准,确保了数据的可靠性与一致性。
特点
NL2SQL-BUGs数据集的特点在于其全面的语义错误分类体系,涵盖了9个主要类别和31个子类别的错误类型。数据集中的每个错误示例均经过专家精心标注,提供了详细的错误类型信息。此外,数据集还包含了大量正确示例,为研究语义错误检测提供了丰富的对比数据。这种结构化的分类与标注方式,使得该数据集在语义错误检测领域具有重要的研究价值。
使用方法
NL2SQL-BUGs数据集的使用方法包括下载与BIRD基准一致的数据库,并通过`./data/`目录获取NL2SQL-BUGs的标签和错误类型信息。研究者可以利用该数据集进行语义错误检测模型的训练与评估,使用整体准确率、负例精度、负例召回率、正例精度、正例召回率以及类型特定准确率等指标进行性能评估。通过引用相关论文,研究者可以在学术研究中合法使用该数据集。
背景与挑战
背景概述
NL2SQL-BUGs数据集由Xinyu Liu等研究人员于2025年创建,旨在为自然语言到SQL(NL2SQL)翻译中的语义错误检测提供基准。尽管现有的NL2SQL模型在将自然语言查询转换为SQL语句方面取得了显著进展,但这些模型仍频繁生成语义错误的查询,这些查询可能执行成功但产生错误结果。NL2SQL-BUGs通过提供一个包含2018个实例的专家注释数据集,支持语义错误检测的研究,其中包含1019个正确示例和999个语义错误示例。该数据集不仅为研究者提供了一个全面的分类系统,涵盖9个主要类别和31个子类别的语义错误,还为后续的错误纠正研究奠定了基础。
当前挑战
NL2SQL-BUGs数据集面临的挑战主要体现在两个方面。首先,语义错误的检测本身具有高度复杂性,尤其是在NL2SQL翻译中,语义错误可能涉及多种复杂的语言结构和数据库操作,导致错误类型多样且难以准确分类。其次,数据集的构建过程中,专家需要对大量实例进行细致的语义错误标注,这不仅需要深厚的领域知识,还需确保标注的一致性和准确性。此外,如何有效评估语义错误检测模型的性能也是一个挑战,数据集提供了多种评估指标,如总体准确率、负例精度和召回率等,但这些指标的设计和解释仍需进一步优化以适应不同研究需求。
常用场景
经典使用场景
NL2SQL-BUGs数据集在自然语言到SQL翻译领域中被广泛用于检测和分类语义错误。该数据集通过提供2018个实例,包括1019个正确示例和999个带有语义错误的示例,为研究人员提供了一个全面的基准,用于评估和改进NL2SQL模型的语义错误检测能力。其两级分类系统涵盖了9个主要类别和31个子类别,使得研究者能够深入分析不同类型的语义错误。
实际应用
在实际应用中,NL2SQL-BUGs数据集被用于开发和优化NL2SQL系统,特别是在需要高精度SQL查询的领域,如金融、医疗和电子商务。通过使用该数据集,开发者能够训练模型以识别和避免常见的语义错误,从而提高系统的实用性和用户满意度。此外,该数据集还可用于教育领域,帮助学生和研究人员理解NL2SQL翻译中的常见错误及其解决方案。
衍生相关工作
NL2SQL-BUGs数据集催生了一系列相关研究工作,特别是在语义错误检测和纠正领域。许多研究基于该数据集开发了新的算法和模型,以提高NL2SQL系统的性能。例如,一些研究专注于改进错误分类的准确性,而另一些则致力于开发自动纠错机制。这些工作不仅推动了NL2SQL技术的发展,还为其他自然语言处理任务提供了有价值的参考。
以上内容由遇见数据集搜集并总结生成


