DCASE 2025 Challenge Audio Question Answering (AQA) dataset
收藏arXiv2025-05-12 更新2025-05-14 收录
下载链接:
https://huggingface.co/datasets/PeacefulData/2025_DCASE_AudioQA_Official
下载链接
链接失效反馈官方服务:
资源简介:
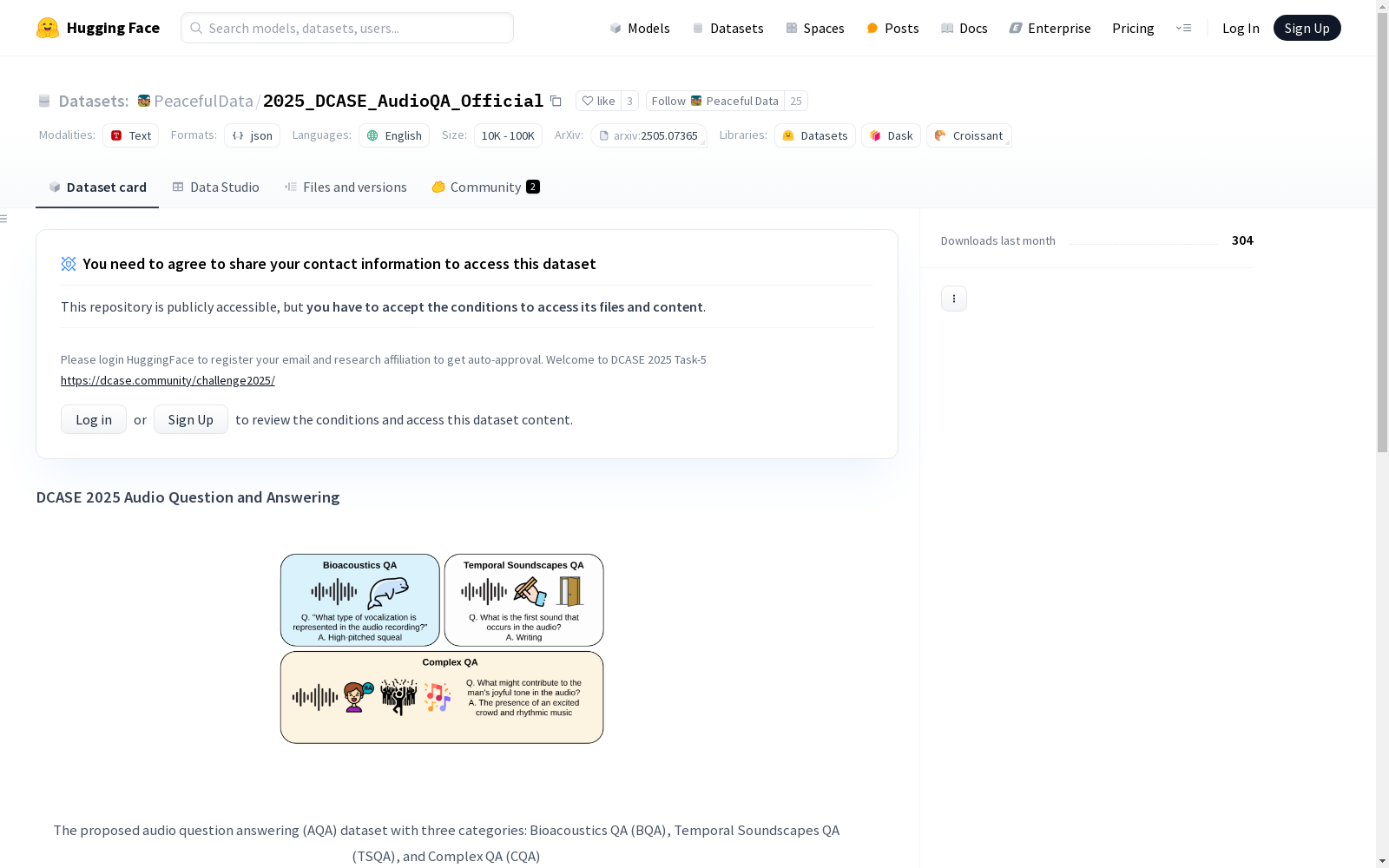
DCASE 2025挑战的音频问答(AQA)数据集是一个多领域音频理解基准,旨在推动音频语言模型在音频理解和推理能力方面的进步。数据集由三个子集组成:生物声学QA(BQA)、时间声音场景QA(TSQA)和复杂QA(CQA),每个子集都包含训练集和开发集,共计约8700个问答对。数据集涵盖了从海洋哺乳动物叫声到声音场景和复杂现实世界片段的内容,旨在评估音频语言模型在多领域音频理解和推理方面的能力。
The Audio Question Answering (AQA) dataset for the DCASE 2025 Challenge is a multi-domain audio understanding benchmark designed to advance the audio comprehension and reasoning capabilities of audio-language models. This dataset consists of three subsets: Bioacoustic QA (BQA), Temporal Sound Scene QA (TSQA), and Complex QA (CQA). Each subset includes a training set and a development set, with a total of approximately 8,700 question-answer pairs. The dataset covers content ranging from marine mammal vocalizations to sound scenes and complex real-world audio clips, and is intended to evaluate the multi-domain audio comprehension and reasoning abilities of audio-language models.
提供机构:
NVIDIA, University of Maryland, College Park, University of Science and Technology of China, Seoul National University, Adobe
创建时间:
2025-05-12
搜集汇总
数据集介绍
构建方式
DCASE 2025 Challenge Audio Question Answering (AQA) 数据集通过多领域音频理解任务构建,涵盖生物声学、时间声景和复杂问答三个子集。生物声学子集(BQA)基于Watkins海洋哺乳动物声音数据库,包含31种物种的声学特征标注;时间声景子集(TSQA)整合NIGENS、L3DAS23等公开数据集,聚焦声音事件的时序关系;复杂问答子集(CQA)融合AudioSet和MiraData的实景音频,采用多轮人工验证确保问题-答案对的逻辑严谨性。所有数据均通过HuggingFace平台以标准化JSON格式发布,配套提供音频下载脚本与基线模型。
特点
该数据集创新性地实现了跨模态认知评估,其生物声学子集以高频变调信号(10-20kHz)和物种特异性发声为特色;时间声景子集通过严格标注的起止时间戳(精度达0.1秒)构建时序推理链;复杂问答子集则包含需结合声学特征与常识推理的复合型问题。三子集共含8.9K训练样本与2.4K验证样本,音频采样率覆盖600Hz-160kHz,时长跨度从0.4秒至10分钟,有效检验模型在异构声学环境下的鲁棒性。特别设计的答案随机排序评估机制进一步增强了基准测试的严谨性。
使用方法
研究者可通过HuggingFace仓库获取标准化数据包,其中问题-答案对以JSON-LD格式存储,音频文件支持脚本批量下载或直接访问原始数据库。评估采用top-1准确率核心指标,要求模型输出与标准答案严格匹配。官方提供Qwen2-Audio-7B等基线系统(平均准确率45.0%),建议参赛者采用跨模态注意力机制处理音频-文本对齐,对于时序推理任务可引入可微分动态时间规整(DTW)算法。提交需包含CSV预测文件与系统元数据YAML,最终评分综合考量领域平均准确率与答案排列鲁棒性。
背景与挑战
背景概述
DCASE 2025 Challenge Audio Question Answering (AQA) dataset由NVIDIA、马里兰大学、中国科学技术大学等机构联合开发,于2025年推出,旨在推动音频语言模型在跨领域声学内容推理方面的研究。该数据集包含生物声学问答(BQA)、时间声景问答(TSQA)和复杂问答(CQA)三个子集,覆盖从海洋哺乳动物叫声到复杂现实场景的多样化音频内容。作为DCASE挑战赛的第五项任务,AQA突破了传统音频分类和描述的局限,要求模型结合声学感知与外部知识进行交互式推理,为构建具备人类水平听觉理解能力的AI系统设立了新基准。其创新性体现在多领域评估框架设计上,显著推动了音频-语言跨模态研究的发展。
当前挑战
该数据集面临的核心挑战主要体现在两个方面:在领域问题层面,需解决声学事件时序关系建模(如TSQA中重叠声音的起止时间判定)、跨模态知识融合(如BQA中生物声学特征与物种知识的关联)以及复杂场景推理(如CQA中多事件因果推断)等难题;在构建过程中,挑战包括高频声学信号标注的专家依赖性(如160kHz采样率的鲸类录音)、时序标注的一致性验证(需精确到毫秒级的事件边界标记),以及从AudioSet等异构数据源提取问答对时的语义对齐问题。这些挑战使得当前基线模型在开发集上的平均准确率仅为45%,凸显了音频推理任务的复杂性。
常用场景
经典使用场景
DCASE 2025 Challenge Audio Question Answering (AQA) 数据集在音频理解与推理领域具有广泛的应用价值,特别是在多领域音频问答任务中表现突出。该数据集通过三个子集(Bioacoustics QA、Temporal Soundscapes QA 和 Complex QA)分别测试模型在生物声学、时间声景和复杂问答场景中的表现。经典使用场景包括模型对海洋哺乳动物叫声的识别与分类、声景中声音事件的时序关系推理,以及基于复杂音频内容的问答任务。这些场景不仅要求模型具备高精度的音频感知能力,还需要结合外部知识进行多模态推理。
衍生相关工作
该数据集的发布推动了多项经典工作的衍生。例如,基于Qwen2-Audio-7B和AudioFlamingo 2的基线模型研究,探索了音频语言模型在多领域问答任务中的性能优化。此外,数据集还被用于评估Gemini-2-Flash等多模态模型在音频推理任务中的表现。相关研究进一步扩展至任务激活提示(task-activating prompting)和高效微调方法,为音频理解领域的模型改进提供了新的技术路径。
数据集最近研究
最新研究方向
在音频理解与推理领域,DCASE 2025 Challenge Audio Question Answering (AQA) dataset 的最新研究聚焦于多领域音频问答系统的开发与评估。该数据集通过生物声学QA、时间声景QA和复杂QA三个子集,全面测试音频语言模型在跨领域声学场景中的交互式问答能力。前沿研究主要探索模型在细粒度声学特征识别、时序关系推理以及多模态知识融合方面的表现,旨在推动音频语言模型向人类水平的听觉理解与推理能力迈进。这一方向与当前AI代理对现实世界感知与交互的需求密切相关,为音频智能的通用化发展提供了重要基准。
相关研究论文
- 1Multi-Domain Audio Question Answering Toward Acoustic Content Reasoning in The DCASE 2025 ChallengeNVIDIA, University of Maryland, College Park, University of Science and Technology of China, Seoul National University, Adobe · 2025年
以上内容由遇见数据集搜集并总结生成


