embodiedSSM/UrbanVideo-Bench
收藏Hugging Face2026-05-02 更新2026-05-03 收录
下载链接:
https://hf-mirror.com/datasets/embodiedSSM/UrbanVideo-Bench
下载链接
链接失效反馈官方服务:
资源简介:
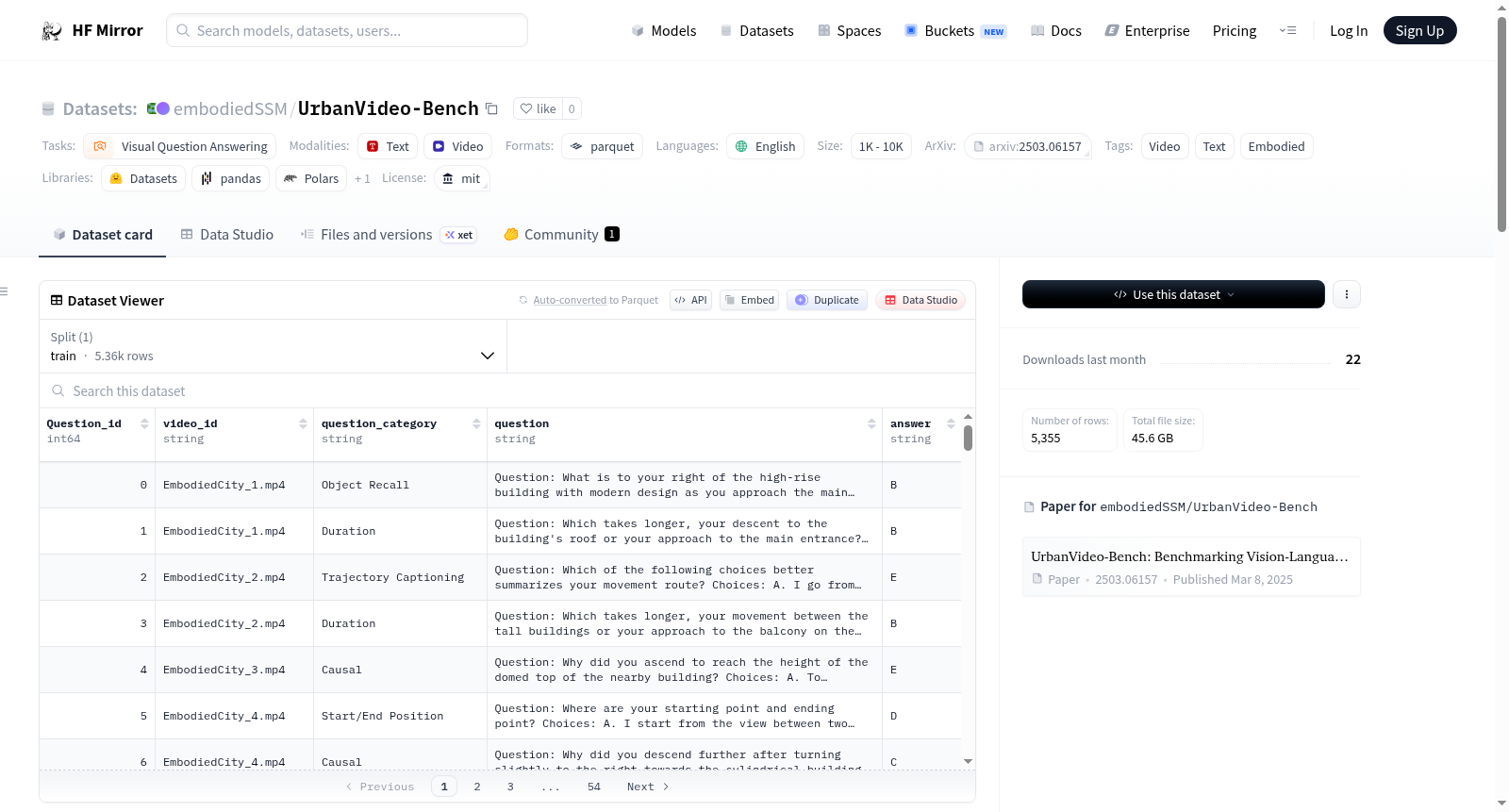
该基准测试旨在评估视频-大语言模型(Video-LLMs)是否能像人类一样自然地处理连续的第一人称视觉观察,包括回忆、感知、推理和导航等能力。数据集包含两部分:5k+的多选题问答(MCQ)数据和1k+的视频片段。文本数据存储在MCQ.parquet文件中,视频数据存储在videos文件夹中。MCQ.parquet文件包含多个字段,如Question_id(每个多选题的全局索引)、video_id(每个多选题对应的视频名称)、question_category(每个多选题对应的任务类别)、question(问题和选项的文本)和answer(多选题的正确答案)。
The benchmark is designed to evaluate whether video-large language models (Video-LLMs) can naturally process continuous first-person visual observations like humans, enabling recall, perception, reasoning, and navigation. The dataset consists of two parts: 5k+ multiple-choice question-answering (MCQ) data and 1k+ video clips. The text data is available in the file `MCQ.parquet`, and the video data is stored in the `videos` folder. The `MCQ.parquet` contains the following fields: `Question_id` (Global index of each MCQ), `video_id` (Video name for each MCQ), `question_category` (Task category corresponding to each MCQ), `question` (Text of question and options), and `answer` (Ground truth answer for the MCQ).
提供机构:
embodiedSSM
搜集汇总
数据集介绍
构建方式
UrbanVideo-Bench是面向城市空间具身智能评估的大规模视频问答基准数据集。其构建过程始于从真实城市环境中采集的第一人称视角视频数据,涵盖复杂动态场景,如行人交互、交通流和导航路径。研究团队精心剪辑并筛选了超过1000个高质量视频片段,确保每个片段包含丰富的视觉线索和情境信息。基于这些视频,他们设计了5000余道多项选择题(MCQ),每道题目均包含四个候选选项和一个标准答案。数据集的文本部分存储于MCQ.parquet文件中,视频内容则存放于videos文件夹内,共同构成了一个结构严谨的评估体系。
特点
该数据集的核心特点在于聚焦于视频大语言模型(Video-LLMs)在具身智能任务中的表现,特别是模拟人类连续第一人称视觉观察的能力。它涵盖了记忆、感知、推理与导航四大任务类别,通过视频-文本对齐的多项选择题形式,系统评测模型对动态城市环境的理解深度。此外,数据集提供了统一的接口与标准化评估流程,支持重复实验与纵向对比。研究团队已基于该基准对17个主流Video-LLM进行了初步评估,验证了其在揭示模型能力边界方面的有效性。
使用方法
使用UrbanVideo-Bench时,用户需首先下载MCQ.parquet文件与videos文件夹。通过解析parquet文件中的字段,包括question_id、video_id、question_category、question与answer,可完整获取每个问答对的上下文。评估流程通常涉及将视频与问题文本输入至目标Video-LLM,收集模型输出的答案并与ground truth进行比对。用户可直接依据数据集提供的标准化协议计算准确率,或根据自身需求调整评估维度。详细的基线结果与使用案例已在原论文中公开,便于复现与扩展研究。
背景与挑战
背景概述
UrbanVideo-Bench是由北京理工大学、清华大学等机构的研究团队于2025年提出的一项基准数据集,相关研究成果已被ACL 2025接收为Oral论文。该基准旨在评估视频大语言模型(Video-LLMs)在城市空间中对第一人称连续视觉观察的理解能力,核心研究问题涉及模型是否能够像人类一样自然处理视频数据,进而实现记忆、感知、推理与导航等功能。通过构建超过5000道多项选择题和1000余段视频片段,该数据集为具身智能体在城市环境中的视觉-语言协同理解提供了标准化的评测平台,对推动视频语言模型在真实场景中的应用具有重要意义。
当前挑战
该数据集所解决的领域问题聚焦于当前视频大语言模型在城市具身智能任务中的表现不足,具体挑战包括:模型需要从第一人称视频流中同时抽取时间序列信息与空间布局知识,以完成诸如路径回忆、动态场景感知、空间推理及自主导航等复合型任务,这远超传统图像问答的难度。在构建过程中,研究团队面临的主要挑战在于:如何设计高质量的多项选择题以覆盖多样化的城市环境情境,以及如何确保视频片段与问题之间的语义对齐,避免因视角变化或光照差异导致的歧义,从而保证评估结果的可靠性与泛化能力。
常用场景
经典使用场景
UrbanVideo-Bench数据集专为评估视频大语言模型(Video-LLMs)在具身智能场景中的表现而设计,其核心使用场景聚焦于城市空间中的第一人称视觉感知与理解。该数据集包含超过5000道多项选择题和1000余段视频片段,模拟人类在复杂城市环境中的连续视觉观察过程。经典用法是驱动Video-LLMs完成记忆召回、场景感知、逻辑推理与空间导航四大类任务,从而检验模型是否具备如同人类般自然处理视觉信息的能力。研究者可通过该基准测试不同模型在真实城市街景、交通动态、人机交互等多元情境下的认知水平,为具身智能体的视频理解能力提供标准化评估框架。
实际应用
在城市智能化进程加速的背景下,UrbanVideo-Bench的应用场景涵盖自动驾驶辅助系统、智能机器人导航、城市安全监控及增强现实交互等领域。例如,自动驾驶汽车需借助路侧或车载视频理解行人意图与交通信号;服务机器人需在复杂街区中精准定位并规划路径;城市管理者可利用视频分析人流异常与事件演化。该数据集为这些实际系统提供了评估模型可靠性与鲁棒性的参考标准,帮助开发者筛选出最能适应城市动态环境的视觉语言模型,从而提升智能体在真实世界中的决策安全性与任务完成效率。
衍生相关工作
UrbanVideo-Bench的发布催生了一系列衍生研究工作,主要集中在多模态模型的城市适应性与具身推理增强方向。相关工作包括:基于该基准改进视频特征对齐策略以提升空间理解精度的研究;融合时序记忆模块以增强模型长期依赖建模能力的模型设计;以及利用该数据集提炼城市场景先验知识、指导模型低样本迁移学习的元学习范式。此外,部分研究者将其与SimAgent、Habitat等具身模拟平台结合,构建从视频理解到动作执行的端到端评估链条,进一步拓展了城市场景下具身智能的研究边界。
以上内容由遇见数据集搜集并总结生成


