SignAvatars
收藏arXiv2024-04-03 更新2024-06-21 收录
下载链接:
https://signavatars.github.io/
下载链接
链接失效反馈官方服务:
资源简介:
SignAvatars数据集由帝国理工学院和腾讯AI实验室合作创建,是首个大规模的3D手语运动数据集。该数据集包含70,000个视频,总计8.34百万帧,覆盖了孤立和连续的手语动作,并提供了多种提示类型,如HamNoSys、口语和词汇。数据集通过创新的自动标注流程实现了3D整体标注,包括身体、手和面部的网格和生物力学有效的姿势,以及2D和3D关键点。SignAvatars数据集旨在弥合听障人士的沟通差距,支持多种任务,如3D手语识别和从文本脚本、单个词汇和HamNoSys符号生成3D手语。
The SignAvatars dataset, co-created by Imperial College London and Tencent AI Lab, is the first large-scale 3D sign language motion dataset. It contains 70,000 videos totaling 8.34 million frames, covering both isolated and continuous sign language gestures, and provides multiple annotation types such as HamNoSys, spoken language, and vocabulary. The dataset realizes holistic 3D annotations via an innovative automatic annotation pipeline, including mesh models and biomechanically valid poses for the body, hands, and face, as well as 2D and 3D keypoints. The SignAvatars dataset aims to bridge the communication gap for deaf and hard-of-hearing individuals, supporting a range of tasks including 3D sign language recognition and 3D sign language generation from text scripts, single vocabulary items, and HamNoSys symbols.
提供机构:
帝国理工学院
创建时间:
2023-10-31
搜集汇总
数据集介绍
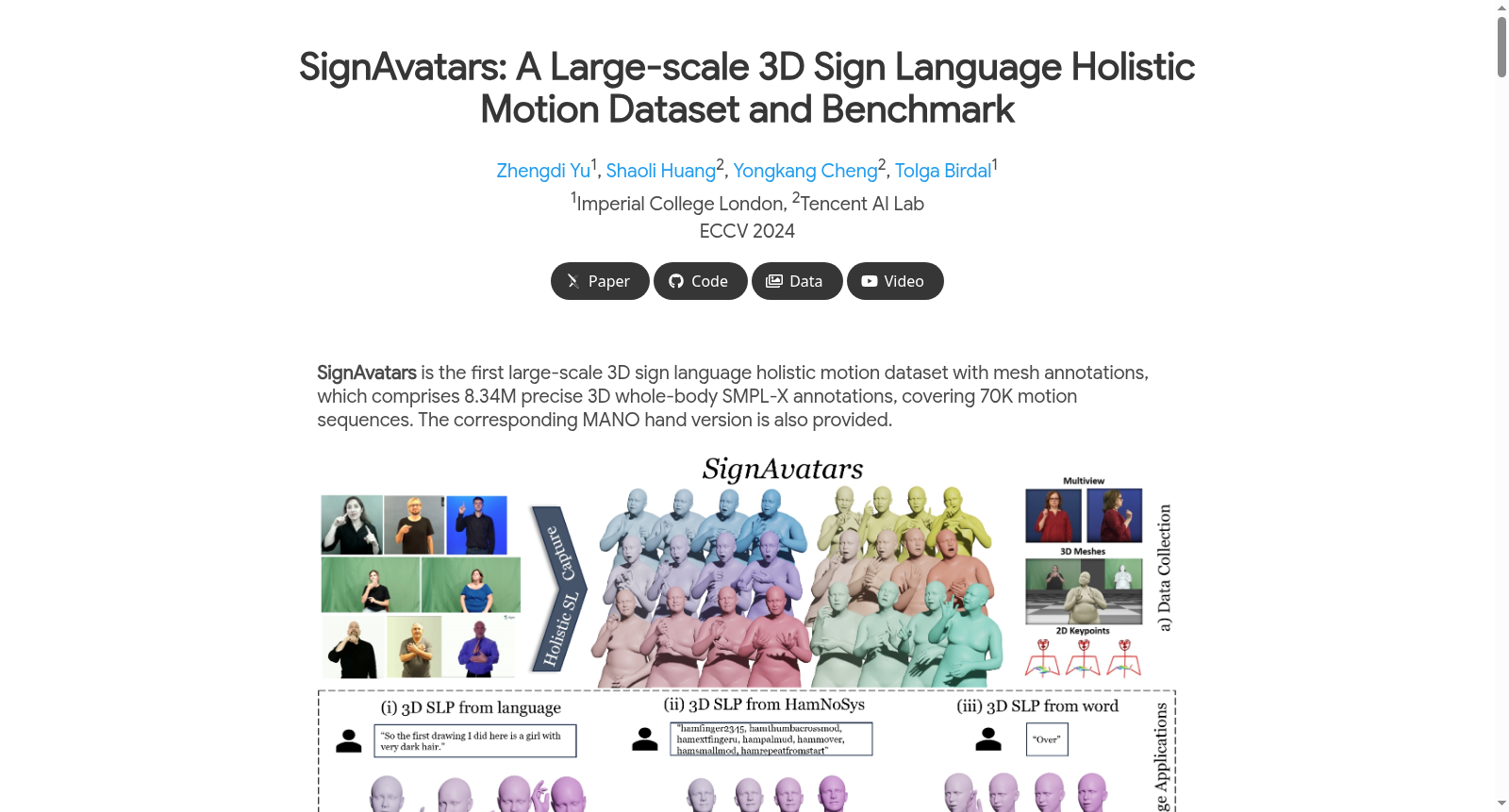
构建方式
在三维手语运动数据集的构建领域,传统方法依赖专家手动标注,过程繁琐且难以规模化。SignAvatars数据集通过创新的自动化标注流程,有效解决了这一瓶颈。该流程整合了来自多个公开数据源的七万段视频,涵盖一百五十三位手语者,总计八百三十四万帧。核心方法采用多目标优化算法,在三维姿态与形状参数上施加整体平滑约束与生物力学手部约束,确保在复杂手势交互场景下仍能生成准确且符合人体工学的网格标注。这一自动化流水线不仅显著提升了标注效率,更保证了三维全身网格(包括身体、手部和面部)以及二维与三维关键点注释的一致性与高质量。
特点
SignAvatars数据集作为首个大规模、多提示的三维手语整体运动数据集,其突出特点在于数据的丰富性与标注的精确性。数据集内容兼具孤立手势与连续、协同发音的手势,并提供了包括HamNoSys符号系统、口语文本及单词在内的多种语义提示,极大拓展了其应用场景。在数据表征上,它提供了基于SMPL-X模型的精确三维全身网格注释,以及专门针对手部的MANO模型子集,实现了对表情、身体姿态及精细手部动作的全面捕捉。这种多模态、高精度的三维注释,有效克服了二维数据存在的深度模糊性问题,为手语理解与生成任务提供了前所未有的高质量资源。
使用方法
SignAvatars数据集为三维手语研究开辟了新的基准测试与应用方向。其主要支持三维手语识别与三维手语生成两大核心任务。用户可基于数据集提供的多种语义提示(如文本、单词、HamNoSys),训练模型以生成自然连贯的三维全身网格运动序列。为便于评估,数据集配套提出了一个统一的三维手语整体运动生产基准,并提供了基于VQVAE的强基线模型Sign-VQVAE。该模型通过构建共享语义码书与运动码书,并利用自回归变换器建立语义到运动的映射,展示了从多样输入生成高质量三维手语动作的潜力。研究人员可利用该基准比较不同模型的性能,推动三维手语数字化身技术的进步。
背景与挑战
背景概述
在数字通信技术蓬勃发展的背景下,手语作为聋哑及听力障碍群体的核心沟通方式,其三维数字化研究长期面临数据匮乏的困境。SignAvatars数据集由帝国理工学院与腾讯AI实验室于2024年联合创建,旨在构建首个大规模、多提示的三维手语整体运动数据集。该数据集汇集了153位手语者的7万段视频,涵盖孤立手势与连续协同发音手势,并创新性地通过自动化标注流程生成包含身体、手部及面部的三维网格与生物力学有效姿态。SignAvatars的诞生突破了传统二维手语数据的深度模糊性限制,为三维手语识别与生成等任务提供了关键基础设施,显著推动了无障碍数字通信领域的发展。
当前挑战
SignAvatars数据集致力于解决三维手语整体运动生成与理解这一核心领域问题,其挑战在于如何从多模态输入(如文本、HamNoSys符号)中生成自然且准确的三维全身运动序列。构建过程中的主要挑战包括:在缺乏三维真值标注的情况下,设计能够处理手部复杂交互与遮挡的自动化标注流程;确保生成的姿态符合生物力学约束,避免不自然的关节运动;以及整合来自不同数据源的异构标注(如句子级手语、孤立词等),保持数据的一致性与可用性。这些挑战共同指向了三维手语计算建模中精度与泛化能力的平衡难题。
常用场景
经典使用场景
在三维手语生成与理解领域,SignAvatars数据集为研究者提供了首个大规模、多提示的三维手语整体运动数据集。该数据集通过自动标注流程,生成了包含身体、手部和面部网格的精确三维注释,覆盖了孤立手势和连续协同发音手势。其经典使用场景包括三维手语识别(SLR)和三维手语生成(SLP),支持从文本脚本、单个词汇及HamNoSys符号等多种输入形式生成自然的三维手语动作序列,为手语数字翻译和虚拟化身应用奠定了数据基础。
解决学术问题
SignAvatars数据集解决了手语研究中的关键学术问题,特别是二维手语数据因深度模糊导致的表达局限性问题。通过提供精确的三维整体运动注释,该数据集消除了二维表示中的歧义,使得手语动作的时空特征得以准确捕捉。此外,数据集的多提示标注(如HamNoSys、口语和词汇)支持跨模态学习,促进了手语生成与理解模型的语义对齐能力,为手语的自然语言处理研究提供了重要支撑。
衍生相关工作
SignAvatars数据集衍生了一系列经典研究工作,特别是在三维手语生成领域。基于该数据集,研究者提出了SignVAE模型,利用VQVAE架构实现从多提示输入到三维整体运动序列的生成。此外,数据集促进了三维手语识别基准的建立,如Ham2Pose-3D和SignDiffuse等方法的扩展,推动了手语动作合成与理解技术的进步,为后续手语翻译和虚拟化身系统的优化提供了重要参考。
以上内容由遇见数据集搜集并总结生成


