PEBench
收藏arXiv2025-03-16 更新2025-03-19 收录
下载链接:
https://pebench.github.io
下载链接
链接失效反馈官方服务:
资源简介:
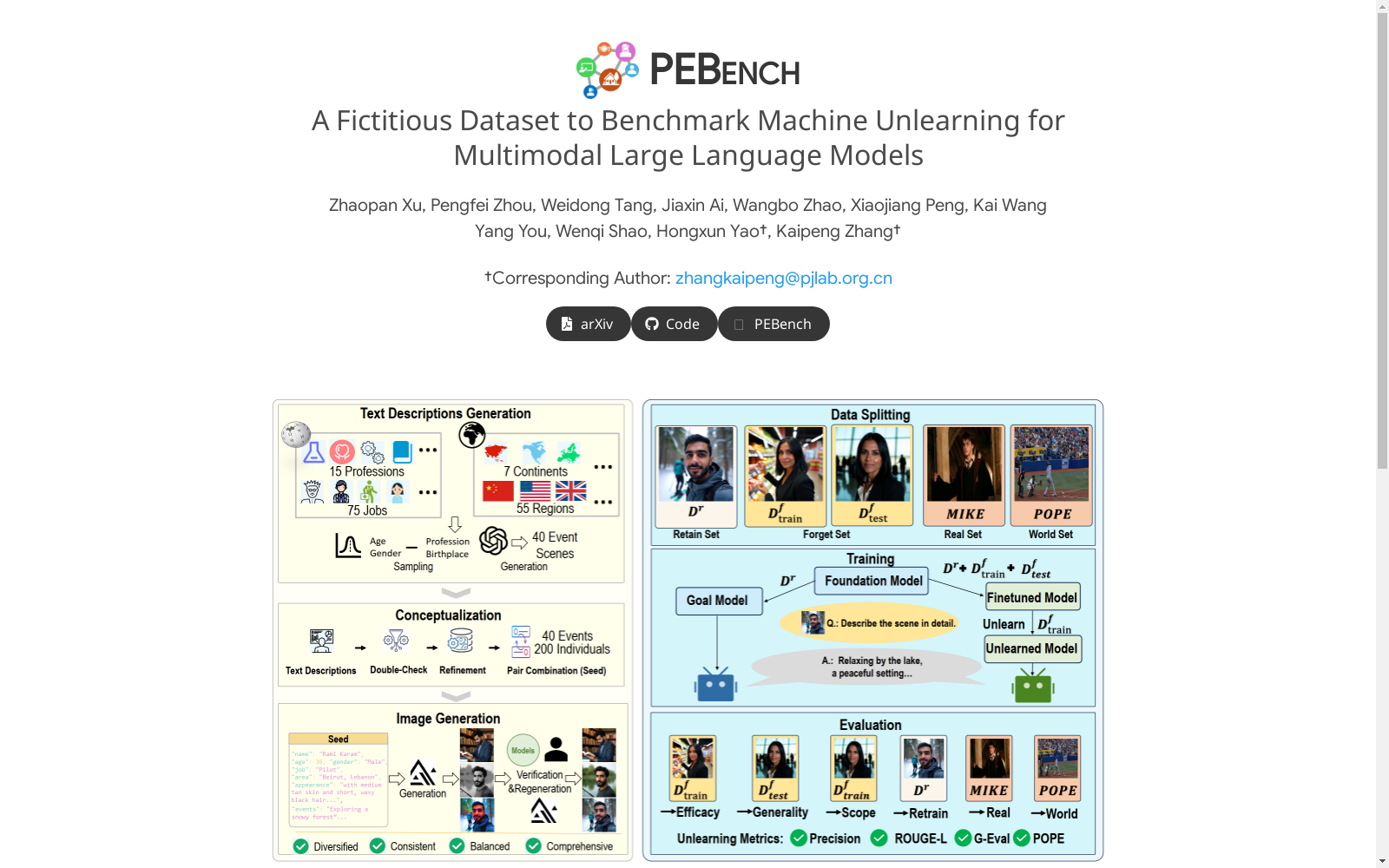
PEBench是一个包含虚构个人实体和相应一般事件场景的合成数据集,由上海人工智能实验室等机构创建,旨在全面评估机器遗忘在多模态大型语言模型中的性能。该数据集由200个虚构个体和40种不同风格的事件场景组成,共计8000张图像。数据集通过合成数据构建,保证了个体和场景之间的一致性和耦合性,可用于评估机器遗忘方法在保护个人隐私和内容安全方面的有效性。
PEBench is a synthetic dataset composed of fictional individual entities and corresponding general event scenarios, created by institutions including the Shanghai AI Laboratory and other relevant organizations. It aims to comprehensively evaluate the performance of machine unlearning in multimodal large language models. This dataset includes 200 fictional individuals and 40 event scenarios with distinct styles, totaling 8000 images. Constructed using synthetic data, it ensures the consistency and coupling between individuals and scenarios, and can be used to assess the effectiveness of machine unlearning methods in protecting personal privacy and content security.
提供机构:
哈尔滨工业大学, 上海人工智能实验室, 上海创新院, 新加坡国立大学, 深圳技术大学, 西安电子科技大学
创建时间:
2025-03-16
搜集汇总
数据集介绍
构建方式
PEBench数据集的构建过程分为两个主要步骤:首先,通过GPT-4生成虚构的个人实体和事件场景的文本描述,确保多样性和一致性。其次,利用图像生成模型(如Flux)生成与文本描述对应的图像,并通过FaceNet等工具验证人物在不同场景中的外观一致性。数据集包含200个虚构人物,每个人物与40个不同的事件场景相关联,共计8000张图像。为确保数据质量,生成过程中采用了严格的多样性、平衡性和一致性控制,并通过人工验证进一步筛选和调整。
特点
PEBench数据集的特点在于其多模态性和对机器遗忘(Machine Unlearning, MU)任务的针对性。数据集不仅包含丰富的虚构人物和事件场景,还通过合成数据避免了与现有多模态大语言模型(MLLMs)训练数据的重叠,从而为评估MU提供了一个理想的上限基准。此外,数据集的设计充分考虑了遗忘目标的多样性,将遗忘目标分为身份(Identity)和事件(Event)两类,分别对应个人隐私和有害内容的遗忘需求。这种设计使得PEBench能够全面评估MU在MLLMs中的表现,尤其是在处理多模态数据时的遗忘效果。
使用方法
PEBench数据集的使用方法主要围绕机器遗忘任务的评估展开。首先,数据集被划分为遗忘集(Forget Set)和保留集(Retain Set),分别用于训练和测试遗忘算法的效果。遗忘集包含需要遗忘的特定人物或事件,而保留集则用于评估模型在遗忘后对非目标数据的保留能力。通过对比遗忘前后的模型输出,研究人员可以评估遗忘算法的有效性、泛化能力和对非目标数据的影响。此外,PEBench还引入了真实世界数据集(Real Set)和世界知识测试集(World Set),以进一步验证模型在遗忘后的实际应用表现。通过这一系列评估步骤,PEBench为多模态大语言模型的机器遗忘研究提供了一个标准化且全面的评估框架。
背景与挑战
背景概述
PEBench数据集由Zhaopan Xu等人于2025年提出,旨在为多模态大语言模型(MLLMs)的机器遗忘(Machine Unlearning, MU)研究提供一个标准化评估框架。随着MLLMs在视觉问答、视觉理解和推理等任务中的显著进展,隐私和安全问题日益凸显。机器遗忘作为一种新兴技术,能够在无需从头训练的情况下,从已训练模型中移除特定知识。然而,现有的MU评估方法在MLLMs中的应用仍不完善,缺乏系统性的基准数据集。PEBench通过引入包含虚构个人实体和事件场景的数据集,填补了这一空白,推动了隐私保护和安全性研究的发展。该数据集由200个虚构个体和40种事件场景组成,共计8000张图像,确保了数据的多样性和一致性。
当前挑战
PEBench面临的挑战主要体现在两个方面。首先,在领域问题方面,机器遗忘的核心挑战在于如何在移除特定知识的同时,不影响模型对其他相关知识的保留。例如,遗忘某个个体的身份信息时,模型可能错误地识别其他个体或场景,导致信息耦合问题。其次,在数据集构建过程中,确保虚构个体在不同事件场景中的外观一致性以及事件场景的多样性是主要难题。尽管使用了先进的图像生成技术,如Flux和FaceNet,生成具有高度一致性和多样性的图像仍然具有挑战性。此外,评估机器遗忘效果时,如何量化遗忘的广度和深度,以及如何避免对非目标知识的负面影响,也是当前研究的难点。
常用场景
经典使用场景
PEBench数据集主要用于评估多模态大语言模型(MLLMs)中的机器遗忘(Machine Unlearning, MU)性能。通过提供虚构的个人实体和事件场景,PEBench为研究者提供了一个标准化的框架,用于测试和比较不同MU方法在移除特定知识时的效果。该数据集的设计使得研究者能够全面评估MU在身份和事件遗忘中的表现,尤其是在处理多模态数据时,如何在不影响其他视觉概念的情况下,选择性遗忘特定信息。
实际应用
PEBench的实际应用场景广泛,尤其是在隐私保护和内容过滤领域。例如,在社交媒体平台中,用户可能希望删除与其相关的个人信息或敏感内容。通过使用PEBench评估的MU技术,平台可以有效地从模型中移除这些信息,而无需重新训练整个模型。此外,PEBench还可用于过滤有害或非法内容,如虚假新闻或不当图像,确保模型在提供信息服务时更加安全和可靠。这些应用不仅提升了用户体验,还增强了数据隐私保护的能力。
衍生相关工作
PEBench的推出催生了一系列相关研究,尤其是在多模态机器遗忘领域。基于PEBench,研究者们提出了多种改进的MU方法,如梯度上升(GA)、梯度差异(GD)和KL散度约束等。这些方法在PEBench上进行了广泛的测试和比较,揭示了它们在身份和事件遗忘中的优缺点。此外,PEBench还激发了更多关于多模态数据遗忘机制的研究,推动了MU技术在更复杂场景中的应用。例如,研究者们开始探索如何在遗忘特定实体时,避免对其他视觉概念(如场景识别)产生负面影响,从而进一步提升模型的鲁棒性和安全性。
以上内容由遇见数据集搜集并总结生成


