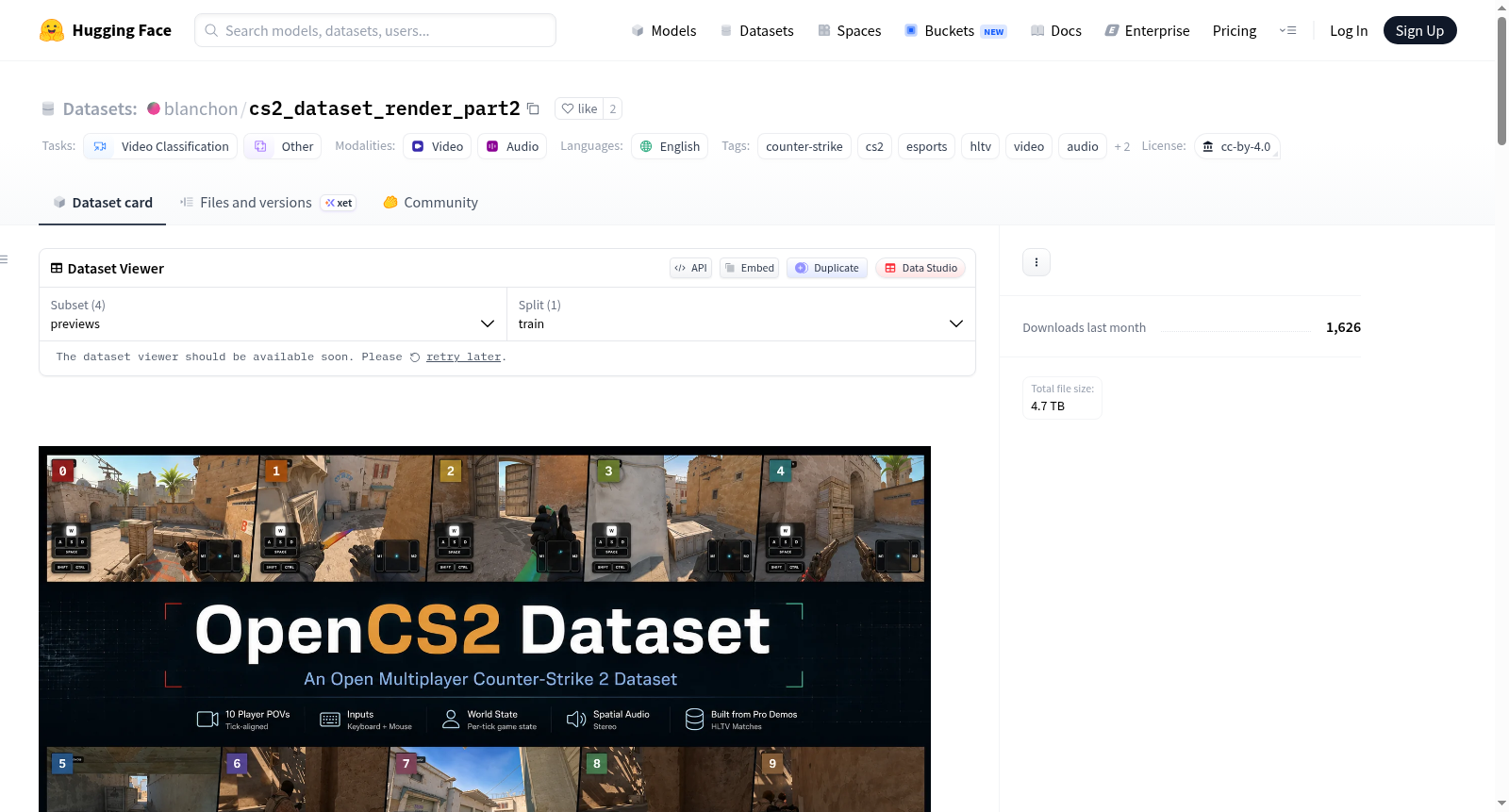
cs2_dataset_render_part2
收藏OpenCS2 — POV Renders 数据集概述
基本信息
- 数据集名称: OpenCS2 — POV Renders
- 许可证: CC-BY-4.0
- 任务类别: 视频分类 (video-classification), 其他 (other)
- 语言: 英语 (en)
- 标签: counter-strike, cs2, esports, hltv, video, audio, parquet, reinforcement-learning
- 数据集主页: OpenCS2 Viewer
数据集描述
该数据集包含从 blanchon/cs2_dataset_demo 渲染的、基于时间戳对齐的《反恐精英2》(CS2)第一人称视角训练片段。每行数据代表一位玩家最多1分钟的视角;同一回合中的10个玩家视角共享相同的时钟刻度。
每个数据块包含
- 视频 — 1280×720 @ 32 fps,近无损 H.264 编码
- 音频 — 每位玩家的立体声,根据该玩家的位置和方向混合
- 输入 — 每帧记录:按键、鼠标增量、视角角度、开火/跳跃/使用、武器切换
- 世界状态 — 每帧记录全部10名玩家:位置、速度、视角、血量、护甲、武器、存活标志
数据集配置
数据集提供4个配置,previews 为默认配置,chunks 为训练用完整数据:
| 配置 | 内容 | 用途 |
|---|---|---|
previews(默认) |
低分辨率 preview.mp4 + 1Hz 输入/世界侧车文件 |
浏览、快速检查 |
chunks |
仅路径的 video.mp4 + audio.wav,内嵌输入和世界数据 |
训练 |
matches |
每行一个 (match_id, map_name),附带队伍/赛事元数据 |
筛选 / 索引 |
rounds |
每行一个 (match_id, map_name, round),附带时间戳边界 |
筛选 / 索引 |
数据结构
仓库布局
data/ match_id=<id>/map_name=<map>/player=<0-9>/ chunks-preview-<machine>-<uuid>.parquet chunks-full-<machine>-<uuid>.parquet chunks/chunk_<n>/{video.mp4, audio.wav} previews/chunk_<n>/{preview.mp4, inputs.preview.json, world.preview.jsonl} index/ manifest-<machine>-<uuid>.parquet # 每行对应一个 (match, map) rounds-<machine>-<uuid>.parquet # 每行对应一个 (match, map, round)
行语义
player— 规范化的0-9玩家索引,在同一比赛中保持稳定spec_slot— 临时的CS2观战插槽编号,仅用于调试- 录制从可玩的回合开始(
freeze_end_tick)开始;死亡视角保留到回合结束的短尾;幸存者视角保留一段短后回合尾段 inputs和worlds在 chunks parquet 中以结构体数组形式存储- 可用于
chunks的筛选列:match_id,map_name,player,round,chunk_index,primary_weapon,player_side,survived_chunk,damage_taken,shots_fired,distance_traveled,weapons_used
数据集创建流程
- Demo 源 — 从
blanchon/cs2_dataset_demo获取 - 渲染 — 使用无头 CS2 + 自定义插件回放每个 demo,逐帧捕获每位玩家的第一人称视角,并将原始帧流式传输至 NVENC 编码器
- Parquet 生成 — 将片段(≤1分钟)按
(round, chunk_index)排序写入,配置row_group_size=1,write_page_index=True和use_content_defined_chunking=True以优化后续上传 - 上传 — 每个渲染工作线程写入自己的
<machine>-<uuid>分片
引用信息
bibtex @misc{blanchon2026opencs2, author = {Julien Blanchon}, title = {OpenCS2 Dataset}, year = {2026}, publisher = {Hugging Face}, howpublished = {url{https://github.com/julien-blanchon/opencs2-dataset}} }