McAuley-Lab/Amazon-C4
收藏Hugging Face2024-04-09 更新2024-06-11 收录
下载链接:
https://hf-mirror.com/datasets/McAuley-Lab/Amazon-C4
下载链接
链接失效反馈官方服务:
资源简介:
---
language:
- en
tags:
- instruction-following
- recommendation
- product search
size_categories:
- 10K<n<100K
---
# Amazon-C4
A **complex product search** dataset built based on [Amazon Reviews 2023 dataset](https://huggingface.co/datasets/McAuley-Lab/Amazon-Reviews-2023).
C4 is short for **C**omplex **C**ontexts **C**reated by **C**hatGPT.
## Quick Start
### Loading Queries
```python
from datasets import load_dataset
dataset = load_dataset('McAuley-Lab/Amazon-C4')['test']
```
```python
>>> dataset
Dataset({
features: ['qid', 'query', 'item_id', 'user_id', 'ori_rating', 'ori_review'],
num_rows: 21223
})
```
```python
>>> dataset[288]
{'qid': 288, 'query': 'I need something that can entertain my kids during bath time. It should be able to get messy, like smearing peanut butter on it.', 'item_id': 'B07DKNN87F', 'user_id': 'AEIDF5SU5ZJIQYDAYKYKNJBBOOFQ', 'ori_rating': 5, 'ori_review': 'Really helps in the bathtub. Smear some pb on there and let them go to town. A great distraction during bath time.'}
```
### Loading Item Pool
If you would like to use the same item pool used for our [BLaIR](https://arxiv.org/abs/2403.03952) paper, you can follow these steps:
```python
import json
from huggingface_hub import hf_hub_download
filepath = hf_hub_download(
repo_id='McAuley-Lab/Amazon-C4',
filename='sampled_item_metadata_1M.jsonl',
repo_type='dataset'
)
item_pool = []
with open(filepath, 'r') as file:
for line in file:
item_pool.append(json.loads(line.strip()))
```
```python
>>> len(item_pool)
1058417
```
```python
>>> item_pool[0]
{'item_id': 'B0778XR2QM', 'category': 'Care', 'metadata': 'Supergoop! Super Power Sunscreen Mousse SPF 50, 7.1 Fl Oz. Product Description Kids, moms, and savvy sun-seekers will flip for this whip! Formulated with nourishing Shea butter and antioxidant packed Blue Sea Kale, this one-of-a kind mousse formula is making sunscreen super FUN! The refreshing light essence of cucumber and citrus has become an instant hit at Super goop! HQ where we’ve been known to apply gobs of it just for the uplifting scent. Water resistant for up to 80 minutes too! Brand Story Supergoop! is the first and only prestige skincare brand completely dedicated to sun protection. Supergoop! has Super Broad Spectrum protection, which means it protects skin from UVA rays, UVB rays and IRA rays.'}
```
## Dataset Description
- **Repository:** https://github.com/hyp1231/AmazonReviews2023
- **Paper:** https://arxiv.org/abs/2403.03952
- **Point of Contact:** Yupeng Hou @ [yphou@ucsd.edu](mailto:yphou@ucsd.edu)
### Dataset Summary
Amazon-C4 is designed to assess a model's ability to comprehend complex language contexts and retrieve relevant items.
In conventional product search, users may input short, straightforward keywords to retrieve desired items. In the new product search task with complex contexts, the input is longer and more detailed, but not always directly relevant to the item metadata. Examples of such input include multiround dialogues and complex user instructions.
### Dataset Processing
Amazon-C4 is created by prompting ChatGPT to generate complex contexts as queries.
During data construction:
* 5-star-rated user reviews on items are treated as satisfactory interactions.
* reviews with at least 100 characters are considered valid for conveying sufficient information to be rewritten as complex contextual queries.
We uniformly sample around
22,000 of user reviews from the test set of [Amazon Reviews 2023 dataset](https://huggingface.co/datasets/McAuley-Lab/Amazon-Reviews-2023) that meet the rating and review length requirements. ChatGPT rephrases user reviews as complex contexts with a first-person tone, serving as queries in the constructed Amazon-C4 dataset.
## Dataset Structure
### Data Fields
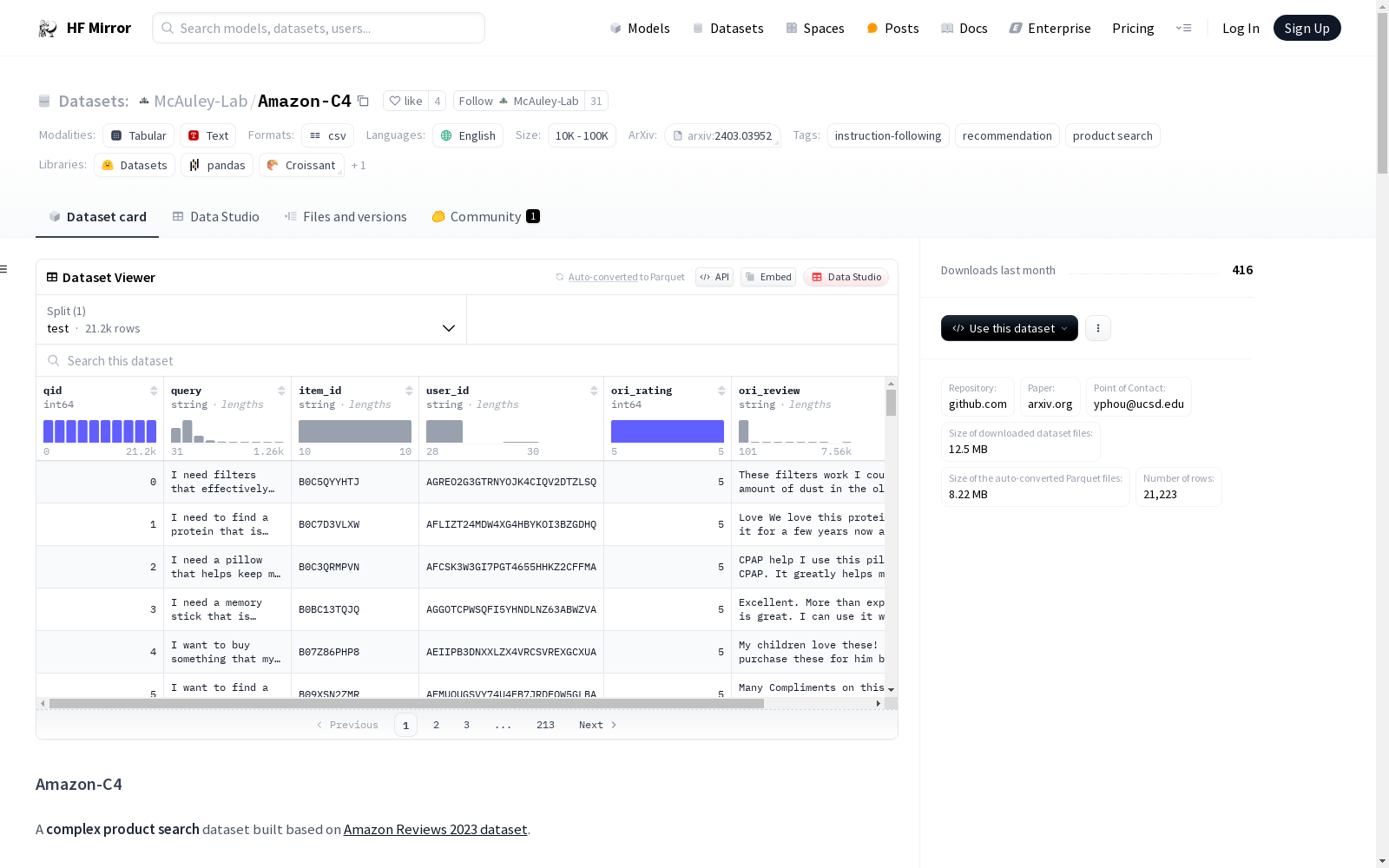
- `test.csv` are query-item pairs that can be used for evaluating the complex product search task. There are 6 columns in this file:
- `qid (int64)`: Query ID. Unique ID for each query, ranging from 0 to 21222. An example of `conv_id` is:
```
288
```
- `query (string)`: Complex query. For example:
```
I need something that can entertain my kids during bath time. It should be able to get messy, like smearing peanut butter on it.
```
- `item_id (string)`: Unique ID for the ground truth item. This ID corresponds to `parent_asin` in the original Amazon Reviews 2023 dataset. For example:
```
B07DKNN87F
```
- `user_id (string)`: The unique user ID. For example:
```
AEIDF5SU5ZJIQYDAYKYKNJBBOOFQ
```
- `ori_rating (float)`: Rating score of the original user review before rewritten by ChatGPT. Note that this field should not be used for solving this task, but just remained for reference. For example:
```
5
```
- `ori_review (string)`: Original review text before rewritten by ChatGPT. Note that this field should not be used for solving this task, but just remained for reference. For example:
```
Really helps in the bathtub. Smear some pb on there and let them go to town. A great distraction during bath time.
```
- `sampled_item_metadata_1M.jsonl` contains ~1M items sampled from the Amazon Reviews 2023 dataset. For each <query, item> pairs, we randomly sample 50 items from the domain of the ground-truth item. This sampled item pool is used for evaluation of the [BLaIR paper](https://arxiv.org/abs/2403.03952). Each line is a json:
- `item_id (string)`: Unique ID for the ground truth item. This ID corresponds to `parent_asin` in the original Amazon Reviews 2023 dataset. For example:
```
B07DKNN87F
```
- `category (string)`: Category of this item. This attribute can be used to evaluate the model performance under certain category. For example:
```
Pet
```
- `metadata (string)`: We concatenate `title` and `description` from the original item metadata of the Amazon Reviews 2023 dataset together into this attribute.
### Data Statistic
|#Queries|#Items|Avg.Len.q|Avg.Len.t|
|-|-|-|-|
|21,223|1,058,417|229.89|538.97|
Where `Avg.Len.q` denotes the average
number of characters in the queries, `Avg.Len.t` denotes the average number of characters in the item metadata.
### Citation
Please cite the following paper if you use this dataset, thanks!
```bibtex
@article{hou2024bridging,
title={Bridging Language and Items for Retrieval and Recommendation},
author={Hou, Yupeng and Li, Jiacheng and He, Zhankui and Yan, An and Chen, Xiusi and McAuley, Julian},
journal={arXiv preprint arXiv:2403.03952},
year={2024}
}
```
Please [raise a issue](https://github.com/hyp1231/AmazonReviews2023/issues/new) at our GitHub repo, or [start a discussion here](https://huggingface.co/datasets/McAuley-Lab/Amazon-C4/discussions/new), or directly contact Yupeng Hou @ [yphou@ucsd.edu](mailto:yphou@ucsd.edu) if you have any questions or suggestions.
language:
- en
tags:
- instruction-following
- recommendation
- product search
size_categories:
- 10K<n<100K
---
# Amazon-C4
本**复杂商品搜索(complex product search)**数据集基于[Amazon Reviews 2023数据集](https://huggingface.co/datasets/McAuley-Lab/Amazon-Reviews-2023)构建。
C4为**由ChatGPT生成的复杂上下文(Complex Contexts Created by ChatGPT)**的缩写。
## 快速开始
### 加载查询
python
from datasets import load_dataset
dataset = load_dataset('McAuley-Lab/Amazon-C4')['test']
python
>>> dataset
Dataset({
features: ['qid', 'query', 'item_id', 'user_id', 'ori_rating', 'ori_review'],
num_rows: 21223
})
python
>>> dataset[288]
{'qid': 288, 'query': '我需要一款能在孩子洗澡时帮他们打发时间的物品,且可以承受弄脏,比如能在上面涂抹花生酱。', 'item_id': 'B07DKNN87F', 'user_id': 'AEIDF5SU5ZJIQYDAYKYKNJBBOOFQ', 'ori_rating': 5, 'ori_review': '这款产品在浴室里真的很实用,抹点花生酱在上面,让孩子们尽情玩耍,是洗澡时绝佳的分心神器。'}
### 加载商品池
如果您希望使用与我们的[BLaIR](https://arxiv.org/abs/2403.03952)论文中相同的商品池,请按照以下步骤操作:
python
import json
from huggingface_hub import hf_hub_download
filepath = hf_hub_download(
repo_id='McAuley-Lab/Amazon-C4',
filename='sampled_item_metadata_1M.jsonl',
repo_type='dataset'
)
item_pool = []
with open(filepath, 'r') as file:
for line in file:
item_pool.append(json.loads(line.strip()))
python
>>> len(item_pool)
1058417
python
>>> item_pool[0]
{'item_id': 'B0778XR2QM', 'category': 'Care', 'metadata': 'Supergoop! Super Power Sunscreen Mousse SPF 50, 7.1 Fl Oz. Product Description Kids, moms, and savvy sun-seekers will flip for this whip! Formulated with nourishing Shea butter and antioxidant packed Blue Sea Kale, this one-of-a kind mousse formula is making sunscreen super FUN! The refreshing light essence of cucumber and citrus has become an instant hit at Super goop! HQ where we’ve been known to apply gobs of it just for the uplifting scent. Water resistant for up to 80 minutes too! Brand Story Supergoop! is the first and only prestige skincare brand completely dedicated to sun protection. Supergoop! has Super Broad Spectrum protection, which means it protects skin from UVA rays, UVB rays and IRA rays.'}
## 数据集说明
- **仓库地址**:https://github.com/hyp1231/AmazonReviews2023
- **论文地址**:https://arxiv.org/abs/2403.03952
- **联系方式**:Hou Yupeng @ [yphou@ucsd.edu](mailto:yphou@ucsd.edu)
### 数据集概述
Amazon-C4旨在评估模型理解复杂语言上下文并检索相关商品的能力。
在传统的商品搜索场景中,用户通常输入简短直白的关键词以获取所需商品。而在这项基于复杂上下文的新型商品搜索任务中,输入内容更长、更详细,但未必与商品元数据直接相关。此类输入的示例包括多轮对话与复杂用户指令。
### 数据集构建流程
Amazon-C4通过提示ChatGPT生成复杂上下文作为查询来构建。
在数据构建阶段:
* 将商品的5星用户评论视为满意的交互记录。
* 长度不低于100个字符的评论被视为具备足够信息,可被重写为复杂上下文查询。
我们从[Amazon Reviews 2023数据集](https://huggingface.co/datasets/McAuley-Lab/Amazon-Reviews-2023)的测试集中,均匀采样了约22000条满足评分与评论长度要求的用户评论。ChatGPT将这些用户评论以第一人称视角重写为复杂上下文,作为Amazon-C4数据集中的查询。
## 数据集结构
### 数据字段
- `test.csv` 包含可用于评估复杂商品搜索任务的查询-商品对,该文件共包含6列:
- `qid (int64)`:查询ID,每个查询的唯一标识符,取值范围为0至21222。示例如下:
288
- `query (string)`:复杂查询,示例如下:
我需要一款能在孩子洗澡时帮他们打发时间的物品,且可以承受弄脏,比如能在上面涂抹花生酱。
- `item_id (string)`:目标商品的唯一标识符,该ID与原始Amazon Reviews 2023数据集中的`parent_asin`相对应,示例如下:
B07DKNN87F
- `user_id (string)`:用户的唯一标识符,示例如下:
AEIDF5SU5ZJIQYDAYKYKNJBBOOFQ
- `ori_rating (float)`:经ChatGPT重写前的原始用户评论评分。请注意,该字段仅作为参考保留,不应被用于解决本任务。示例如下:
5
- `ori_review (string)`:经ChatGPT重写前的原始评论文本。请注意,该字段仅作为参考保留,不应被用于解决本任务。示例如下:
这款产品在浴室里真的很实用,抹点花生酱在上面,让孩子们尽情玩耍,是洗澡时绝佳的分心神器。
- `sampled_item_metadata_1M.jsonl` 包含从Amazon Reviews 2023数据集中采样的约100万条商品数据。对于每个<查询,商品>对,我们从目标商品所属领域中随机采样50个商品,该采样商品池用于[BLaIR论文](https://arxiv.org/abs/2403.03952)的评估。每一行均为一条JSON对象:
- `item_id (string)`:目标商品的唯一标识符,该ID与原始Amazon Reviews 2023数据集中的`parent_asin`相对应,示例如下:
B07DKNN87F
- `category (string)`:商品所属类别,该属性可用于评估模型在特定类别下的性能,示例如下:
Pet
- `metadata (string)`:我们将原始Amazon Reviews 2023数据集中的商品标题与商品描述拼接后,作为该属性的值。
### 数据统计
|#查询数|#商品数|查询平均字符数|元数据平均字符数|
|-|-|-|-|
|21,223|1,058,417|229.89|538.97|
其中`Avg.Len.q`表示查询的平均字符数,`Avg.Len.t`表示商品元数据的平均字符数。
### 引用
如果您使用了本数据集,请引用以下论文,感谢您的支持!
bibtex
@article{hou2024bridging,
title={Bridging Language and Items for Retrieval and Recommendation},
author={Hou, Yupeng and Li, Jiacheng and He, Zhankui and Yan, An and Chen, Xiusi and McAuley, Julian},
journal={arXiv preprint arXiv:2403.03952},
year={2024}
}
如有任何问题或建议,请在我们的GitHub仓库[提交Issue](https://github.com/hyp1231/AmazonReviews2023/issues/new),或在[Hugging Face数据集页面发起讨论](https://huggingface.co/datasets/McAuley-Lab/Amazon-C4/discussions/new),或直接联系Hou Yupeng @ [yphou@ucsd.edu](mailto:yphou@ucsd.edu).
提供机构:
McAuley-Lab
原始信息汇总
Amazon-C4 数据集概述
数据集简介
Amazon-C4 是一个基于 Amazon Reviews 2023 数据集构建的复杂产品搜索数据集。该数据集旨在评估模型理解复杂语言上下文并检索相关项目的能力。
数据集构建
Amazon-C4 通过提示 ChatGPT 生成复杂上下文作为查询来创建。数据构建过程中:
- 5 星评级的用户评论被视为满意交互。
- 至少 100 个字符的评论被认为是有效的,以传达足够的信息被重写为复杂上下文查询。
从 Amazon Reviews 2023 数据集的测试集中均匀采样约 22,000 条符合评级和评论长度要求的评论。ChatGPT 将用户评论重写为第一人称语调的复杂上下文,作为 Amazon-C4 数据集中的查询。
数据集结构
数据字段
-
test.csv包含用于评估复杂产品搜索任务的查询-项目对,共有 6 列:qid (int64): 查询 ID,唯一标识每个查询,范围从 0 到 21222。query (string): 复杂查询。item_id (string): 真实项目的唯一 ID。user_id (string): 用户的唯一 ID。ori_rating (float): 原始用户评论的评分。ori_review (string): 原始评论文本。
-
sampled_item_metadata_1M.jsonl包含从 Amazon Reviews 2023 数据集中采样的约 100 万个项目。每行是一个 JSON 对象,包含以下字段:item_id (string): 真实项目的唯一 ID。category (string): 项目的类别。metadata (string): 从原始项目元数据中连接的title和description。
数据统计
| #Queries | #Items | Avg.Len.q | Avg.Len.t |
|---|---|---|---|
| 21,223 | 1,058,417 | 229.89 | 538.97 |
其中 Avg.Len.q 表示查询的平均字符数,Avg.Len.t 表示项目元数据的平均字符数。
引用
如果您使用此数据集,请引用以下论文:
bibtex @article{hou2024bridging, title={Bridging Language and Items for Retrieval and Recommendation}, author={Hou, Yupeng and Li, Jiacheng and He, Zhankui and Yan, An and Chen, Xiusi and McAuley, Julian}, journal={arXiv preprint arXiv:2403.03952}, year={2024} }
搜集汇总
数据集介绍
构建方式
Amazon-C4数据集是基于Amazon Reviews 2023数据集构建的,旨在评估模型理解复杂语言上下文并检索相关项目的能力。该数据集的构建过程中,选取了约22,000条满足特定评分和评论长度要求的用户评论,通过ChatGPT将这些评论重写为具有第一人称语气的复杂上下文查询,形成数据集的核心部分。
特点
Amazon-C4数据集的特点在于其查询的复杂性和上下文的相关性。每个查询都是基于用户对商品的真实评论生成的,这些评论经过重写后,不仅包含了对商品的具体描述,还融入了用户的个性化需求和使用场景,为模型评估提供了丰富的语义信息。此外,数据集还提供了一个包含约105万条商品元数据的样本集,用于评估模型在不同类别下的表现。
使用方法
使用Amazon-C4数据集时,首先需要加载查询和商品元数据。查询部分包含了查询ID、复杂查询、商品ID、用户ID、原始评分和原始评论等字段。商品元数据部分则包含了商品ID、类别和元数据等字段。用户可以通过HuggingFace的datasets库加载数据集,并根据需要使用相应的商品元数据来评估模型在复杂商品搜索任务中的表现。
背景与挑战
背景概述
Amazon-C4数据集是在2023年构建的,由McAuley实验室的研究人员Yupeng Hou等共同开发。该数据集旨在评估模型理解复杂语言上下文并检索相关项目的能力,对推荐系统和产品搜索领域产生了显著影响。Amazon-C4基于Amazon Reviews 2023数据集,通过ChatGPT生成复杂语境作为查询,以模拟真实场景中用户输入的详细且多样化的查询指令。数据集包含了21,223个查询和1,058,417个条目,每个查询都对应一个独特的用户ID和产品ID,以及原始的用户评分和评论。
当前挑战
Amazon-C4数据集面临的挑战主要在于处理复杂的查询指令,这些指令往往包含多轮对话或复杂的用户指令,而非直接相关的产品信息。此外,构建过程中如何确保通过ChatGPT生成的复杂语境查询能够准确反映用户意图,同时保持与原始产品信息的关联性,也是一项重要挑战。数据集的构建还涉及到如何从大量数据中筛选出符合条件的用户评论,以及如何有效地将评论转化为复杂查询,这些都是在构建过程中需要克服的技术难题。
常用场景
经典使用场景
在复杂的商品搜索场景中,Amazon-C4数据集提供了一种评估模型理解复杂语境和检索相关项目的能力的方式。该数据集的典型使用场景是模拟用户在搜索商品时提供的详细而复杂的查询,如多轮对话或包含复杂指令的查询,以评估模型在处理实际用户场景中的表现。
衍生相关工作
基于Amazon-C4数据集,研究者们已经衍生出多项相关工作,包括但不限于改进对话系统、开发新的推荐算法以及探索复杂语境下的信息检索技术。这些研究进一步拓展了数据集的应用范围,并在提升模型性能方面取得了显著进展。
数据集最近研究
最新研究方向
Amazon-C4数据集近期研究主要围绕复杂语境下的产品搜索任务,旨在评估模型理解复杂语言环境和检索相关项目的能力。该数据集结合了对话和复杂用户指令,为模型训练和评估提供了新的视角。通过Amazon-C4,研究者能够探索如何提升推荐系统在处理长段详细描述和对话时的性能,这对于改进用户交互体验和推荐系统的精确度具有重要意义。同时,该数据集的构建和应用,也进一步推动了语言模型与推荐系统结合的研究前沿。
以上内容由遇见数据集搜集并总结生成


