leanpolish-anon/lean-proof-compression
收藏Hugging Face2026-05-01 更新2026-05-03 收录
下载链接:
https://hf-mirror.com/datasets/leanpolish-anon/lean-proof-compression
下载链接
链接失效反馈官方服务:
资源简介:
LeanPolish是一个关于Lean 4证明重写对的数据集,由LeanPolish工具生成。该数据集包含经过内核验证的证明缩短工具生成的证明重写对,适用于训练模型学习压缩、简化或选择证明策略。数据集包含多个分片,每个分片包含训练对和拒绝对的JSONL文件,具有严格的语义分离。数据集的主要目的是为对比学习或DPO设置提供数据支持。
LeanPolish is a dataset of Lean 4 proof rewrite pairs produced by the LeanPolish tool, a kernel-verified proof-shortening tool. The dataset includes proof rewrite pairs that have been kernel-checked and re-elaborated, suitable for training models to compress, simplify, or select proof tactics. It consists of multiple shards, each containing JSONL files of training pairs and rejected pairs with strict semantic separation, primarily aimed at supporting contrastive learning or DPO setups.
提供机构:
leanpolish-anon
搜集汇总
数据集介绍
构建方式
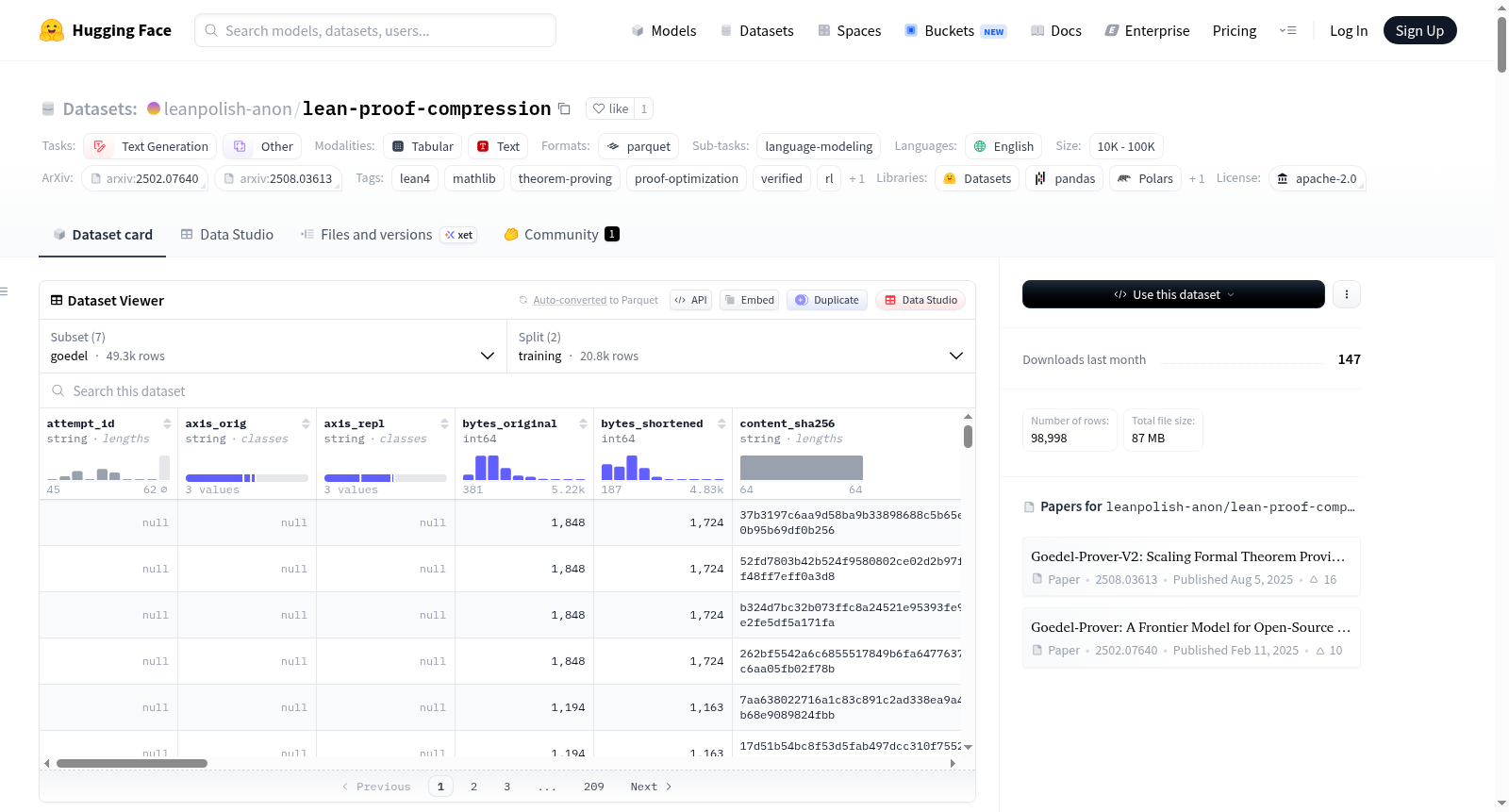
LeanPolish数据集基于Lean 4定理证明环境构建,通过一个内核验证的证明压缩框架生成。该框架从多个数学语料库(如mathlib、Goedel、minif2f及PutnamBench系列)中提取原始证明片段,运用五种优化策略(包括策略替换、死代码消除、警告清理及L2替换合并)生成候选替换,并经由Lean 4.21.0内核与独立进程的重新精化双重验证,确保每个替换对的正确性。最终筛选出33,402个经过验证的优化正例及65,596个对比负例。
特点
该数据集具有多重显著特征。首先,严格的双层验证机制确保了替换对的内核级正确性。其次,数据集包含丰富的结构化字段,如编辑前后代码、目标状态、字节节省量及质量轴标签等,便于多维度分析。此外,其对比学习友好的设计通过attempt_id将正例与失败尝试关联,为直接偏好优化(DPO)提供天然负样本。数据集覆盖数学、形式化验证与竞赛题等多个领域,大小从几十KB至数十MB不等。
使用方法
数据集可通过HuggingFace的load_dataset接口加载,支持按语料库分片访问训练和拒绝拆分。研究人员可使用training_pairs进行策略压缩或简化模型的监督学习,借助rejected_pairs构建对比学习损失,或利用编辑宽度、字节节省量等字段设计强化学习奖励信号。推荐使用len(original)-len(replacement)计算统一字节节省指标,并依据MANIFEST.json中的SHA-256哈希验证数据完整性。
背景与挑战
背景概述
LeanPolish数据集由研究团队于2024年基于Lean 4定理证明器与Mathlib数学库构建,旨在通过内核验证的证明压缩框架优化形式化证明的简洁性。该数据集包含33,402个经内核验证的证明重写对及65,596个对比性拒绝样本,覆盖mathlib、goedel、minif2f及PutnamBench等多个数学竞赛与理论证明语料库。其核心研究问题在于探索如何利用符号压缩与对比学习(DPO)方法训练模型自动简化、压缩或选择证明策略,从而降低形式化证明的复杂性与存储成本。该工作对自动定理证明、形式化验证及面向符号推理的神经网络训练具有重要推动意义,为后续在强化学习与偏好优化框架下优化证明搜索效率提供了基准资源。
当前挑战
所解决的领域问题包括形式化证明的冗余性挑战——即人类书写的Lean证明常包含可自动合并的重复策略、死代码或低效模式,而现有模型难以在保证语义等价的前提下进行压缩。构建过程中面临的主要挑战有三:其一,验证正确性,每个重写对需通过Lean 4.21.0内核检查及独立进程的完整重编以确保无引入错误;其二,多源异构数据兼容,需统一处理来自不同数学库与竞赛题目的代码风格与证明结构差异;其三,对比样本生成,需在有限计算预算下高效筛选出具有信息量的淘汰候选,避免噪声影响模型训练效果。
常用场景
经典使用场景
在人工智能辅助定理证明的蓬勃发展中,LeanPolish数据集为模型优化提供了精密的训练素材。其经典使用场景在于训练语言模型学习压缩、简化或筛选证明策略,特别是通过对比学习与直接偏好优化(DPO)框架,利用每对原证明与经内核验证的优化后证明,以及配套的弃用兄弟样本,教导模型生成更简洁高效的形式化证明。数据集涵盖来自mathlib、Goedel、miniF2F等多个基准的超过3万条成功优化对,为定理证明领域的序列压缩任务树立了标杆。
衍生相关工作
LeanPolish数据集的诞生催生了多个方向的前沿探索,尤其体现在证明搜索与强化学习策略的改进中。基于其提供的经验证的优化对,研究者开发了多种对比学习与直接偏好优化(DPO)的适应方案,例如将弃用样本作为梯度正则项以提升策略网络的泛化能力。同时,该数据集推动了符号压缩技术与序列模型的融合创新,催生了诸如融合内核验证反馈的神经符号搜索算法,以及针对不同证明层级(如单步策略替换与整段冗余消除)的专用优化架构。
数据集最近研究
最新研究方向
该数据集聚焦于符号定理证明领域的前沿探索,特别是利用Lean 4形式化系统实现数学证明的自动化压缩与优化。当前研究热点围绕如何通过「内核验证」的证明缩短框架,将冗长的证明片段替换为更简洁的等价形式,同时保证逻辑正确性。该数据集包含从Mathlib、Goedel、Putnam数学竞赛等多个权威语料库中提取的超过3.3万条已验证的优化证明对,以及6.5万余条用于对比学习的负例样本,为训练能够学习证明压缩、策略选择及简化操作的神经网络模型提供了高质量训练资源。这一工作与近期形式化验证、神经符号推理以及基于DPO的强化学习优化方向紧密关联,尤其在大语言模型辅助自动定理证明的浪潮中,为提升证明效率、降低验证成本开辟了新路径。其意义不仅在于提供数据基础,更在于建立了可复现的证明优化评估基准,有望推动数学证明自动生成与验证领域的范式革新。
以上内容由遇见数据集搜集并总结生成


