prm-scienceworld-state-gemini_3_flash_minimal
收藏Hugging Face2026-05-10 更新2026-05-11 收录
下载链接:
https://huggingface.co/datasets/wls04/prm-scienceworld-state-gemini_3_flash_minimal
下载链接
链接失效反馈官方服务:
资源简介:
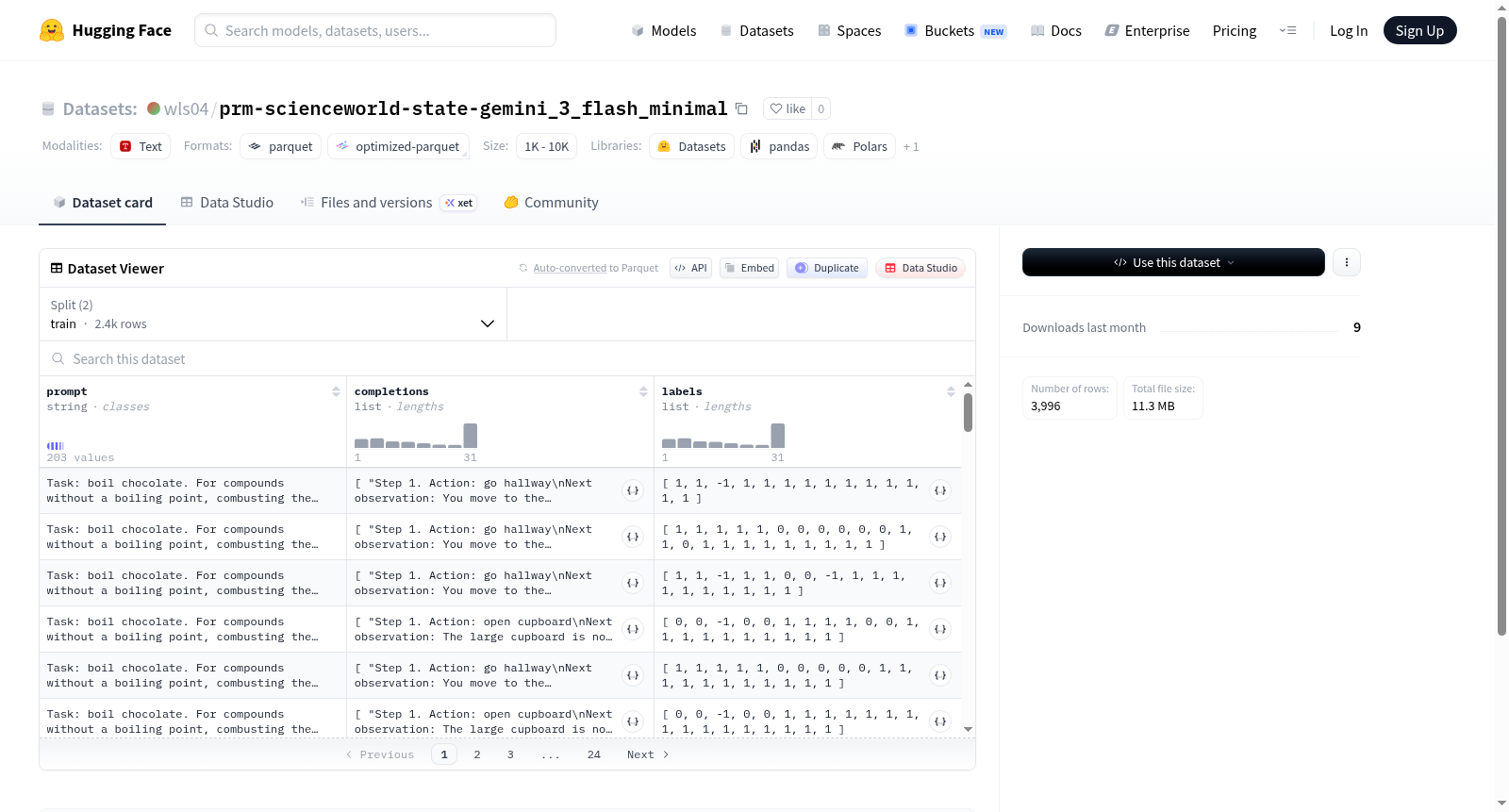
该数据集包含结构化对话或任务完成数据,由提示文本(prompt)、完成选项列表(completions)及对应标签(labels)组成。数据集分为训练集(2,396个样本)和测试集(1,600个样本)两个部分,其中每个样本包含:1) 字符串类型的输入提示;2) 多个字符串形式的完成选项;3) 对应的浮点数值标签列表。数据以分片文件形式存储,训练集路径为data/train-*,测试集路径为data/test-*。
This dataset contains structured dialogue or task completion data, consisting of prompt text, a list of completion options (completions), and corresponding labels (labels). The dataset is divided into two parts: a training set (2,396 samples) and a test set (1,600 samples). Each sample includes: 1) an input prompt of string type; 2) multiple completion options in string form; 3) a corresponding list of floating-point value labels. The data is stored in sharded files, with the training set path as data/train-* and the test set path as data/test-*.
创建时间:
2026-05-10
原始信息汇总
根据您提供的数据集详情页面信息,以下是对该数据集的总结:
数据集概述
- 数据集名称:prm-scienceworld-state-gemini_3_flash_minimal
- 托管平台:Hugging Face
- 数据集地址:https://huggingface.co/datasets/wls04/prm-scienceworld-state-gemini_3_flash_minimal
数据集特征
该数据集包含以下三个字段:
| 字段名 | 数据类型 | 说明 |
|---|---|---|
| prompt | 字符串 | 输入提示 |
| completions | 字符串列表 | 模型生成的完成结果 |
| labels | 浮点数列表 | 对应的标签值 |
数据集划分与规模
数据集分为训练集和测试集两个部分:
- 训练集:2396 个样本,占用约 6.96 MB
- 测试集:1600 个样本,占用约 5.16 MB
- 总大小:约 12.12 MB
- 下载大小:约 11.34 MB
数据集配置
- 默认配置名称:default
- 数据文件路径:
- 训练集:
data/train-* - 测试集:
data/test-*
- 训练集:
搜集汇总
数据集介绍
构建方式
该数据集旨在为科学世界状态下的推理过程提供过程奖励信号。构建过程基于Gemini 3 Flash模型,通过最小监督(minimal supervision)方式生成。具体而言,对于每个科学世界状态下的提示(prompt),模型生成若干候选完成序列(completions),随后由标注机制或自动化方法赋予每个完成序列一个反映其正确性或质量的过程奖励分数(labels)。最终,数据以结构化形式存储,包含prompt、completions及labels三个核心字段,并划分为训练集(2396条)与测试集(1600条),共计3996个样本。
使用方法
使用本数据集时,研究者可将其加载为标准的HuggingFace数据集格式。训练阶段,利用prompt字段作为输入,completions字段作为候选回复,labels字段作为监督目标,训练一个能够预测过程奖励的评分模型。在推断时,模型可对新的科学世界状态下的候选动作或思考链条进行实时打分。此外,数据集可直接用于强化学习中的奖励建模,或作为监督信号提升大型语言模型在科学推理任务中的表现。建议用户根据自身需求,在训练集上微调基线模型,并在测试集上评估泛化能力。
背景与挑战
背景概述
该数据集名为prm-scienceworld-state-gemini_3_flash_minimal,由Gemini团队在2024年前后创建,核心研究聚焦于利用过程奖励模型(Process Reward Model, PRM)来评估科学世界(ScienceWorld)环境中语言模型的中间推理状态。ScienceWorld是一个模拟科学实验的交互式环境,用于测试智能体在复杂科学任务中的推理与规划能力。该数据集通过收集Gemini 3 Flash模型在ScienceWorld状态下的提示与完成序列,并标注对应的奖励分数,旨在推动过程监督学习在科学推理领域的发展。其影响力体现在为强化学习中的奖励建模提供了细粒度、可解释的中间反馈信号,有望提升模型在科学实验规划与执行等长链推理任务上的表现。
当前挑战
该数据集所应对的核心领域挑战是科学推理任务中稀疏奖励信号问题。在交互式科学环境中,最终结果(如实验成功与否)往往无法为中间步骤提供有效指导,导致模型难以学习正确的探索策略。构建过程中的挑战包括:首先,需要从模拟环境中准确提取状态表示并生成多样化的中间完成序列,这要求对ScienceWorld的百余种交互状态进行全覆盖;其次,人工或自动标注这些中间状态的奖励分数极为繁琐,需平衡标注一致性与标注成本,例如确保不同状态转换路径得到合理的中间奖励分配;最后,数据规模有限(训练集仅2396条),可能不足以训练出高度鲁棒的过程奖励模型,易引入过拟合或泛化不足的风险。
常用场景
经典使用场景
在科学世界(ScienceWorld)这一基于文本的交互式模拟环境中,该数据集被设计用于训练和评估过程奖励模型(Process Reward Model, PRM)。其典型使用场景是基于状态轨迹的逐步推理评估,即模型需要根据当前环境状态(prompt)和若干候选行动序列(completions),为每个序列输出一个反映其科学推理正确性的奖励分数(labels)。这为强化学习中的信用分配问题提供了精细化的监督信号,尤其适合需要多步逻辑推演的复杂科学实验任务。
解决学术问题
该数据集旨在解决传统结果奖励模型(Outcome Reward Model)无法有效评估中间步骤合理性的学术困境。在科学推理任务中,一个正确的最终答案可能源自错误的推理链条,而一个错误的答案也可能在前期步骤中展现了良好的逻辑。该数据集通过提供细粒度的过程监督信号,使研究者能够训练模型在每一步都做出符合科学原则的决策,从而显著提升模型在复杂多步任务中的鲁棒性和可解释性。其意义在于推动了从“结果导向”到“过程导向”的强化学习范式转变。
实际应用
在实际应用中,该数据集可直接用于构建智能教育辅导系统中的过程性评价引擎。例如,在虚拟科学实验室中,系统可以根据学生每一步的操作(如添加试剂、调节温度)提供即时、分步骤的反馈,而非仅对最终实验报告打分。此外,该数据集还可赋能自动科学发现系统,使其在进行虚拟实验时能够自主识别和纠正中间步骤的错误,提升自动化科学模拟的准确率和效率,从而加速新型材料或药物分子的虚拟筛选流程。
数据集最近研究
最新研究方向
该数据集聚焦于科学世界状态下的过程奖励模型(Process Reward Model, PRM)研究,利用Gemini 3 Flash Minimal模型生成细粒度的状态级反馈,为复杂科学推理任务中的中间步骤提供监督信号。前沿方向包括将PRM与强化学习结合,优化大语言模型在科学问题解决中的逐步推理能力,以及探索其在教育智能体、自动实验设计等热点领域的应用。数据集的推出填补了科学领域过程级监督数据的空白,推动了可解释、可验证的AI科学推理系统的发展,对于提升模型在科学探究中的可靠性与透明度具有深远意义。
以上内容由遇见数据集搜集并总结生成


