FLEURS_INDO-ENG_Speech_Translation
收藏Hugging Face2024-12-14 更新2024-12-15 收录
下载链接:
https://huggingface.co/datasets/cobrayyxx/FLEURS_INDO-ENG_Speech_Translation
下载链接
链接失效反馈官方服务:
资源简介:
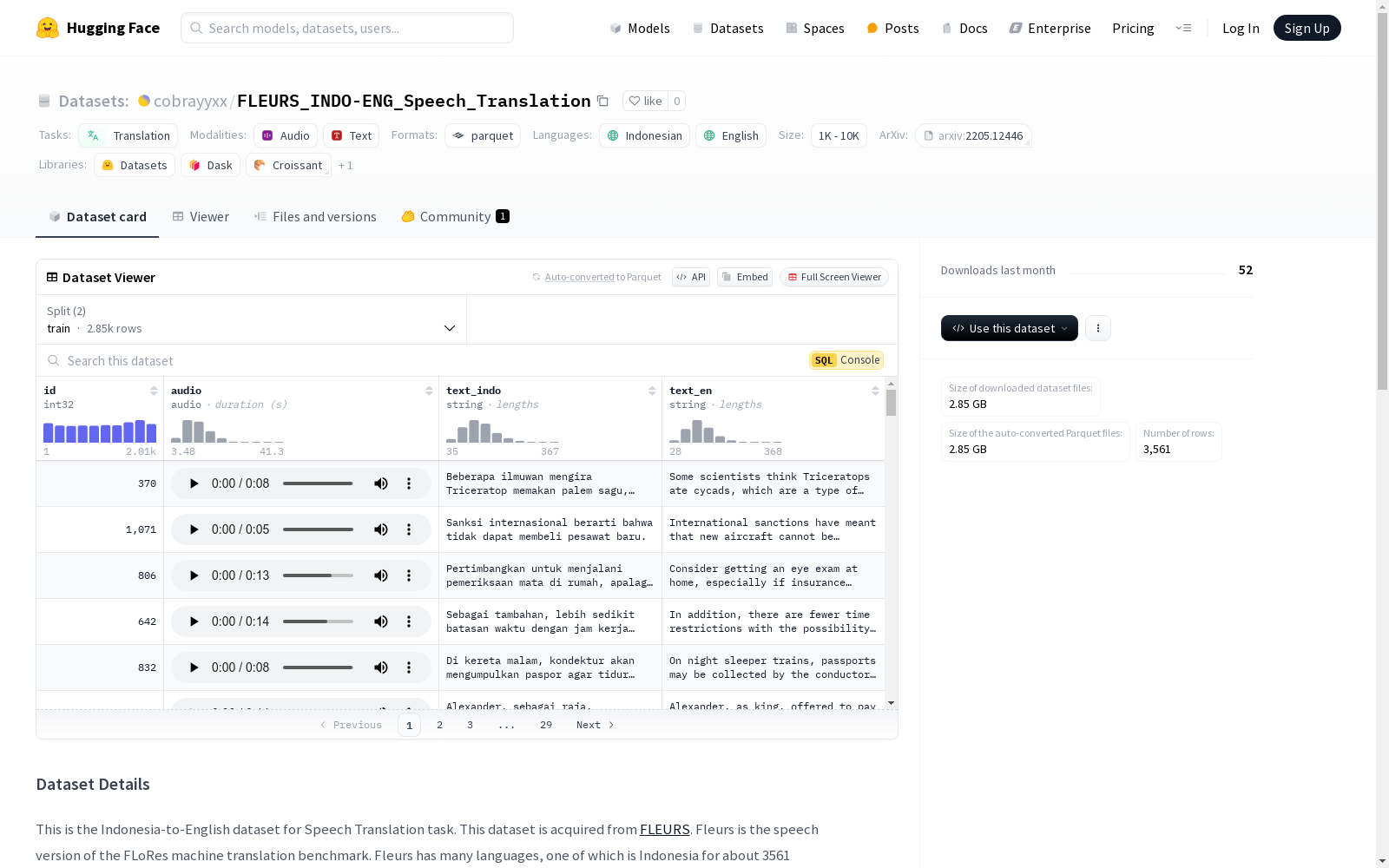
这是一个用于语音翻译任务的印度尼西亚语到英语的数据集,来源于FLEURS。FLEURS是FLoRes机器翻译基准的语音版本,包含多种语言,其中印度尼西亚语部分有大约3561个话语和约12小时24分钟的音频数据。数据集经过预处理,包括删除不需要的列、去除重复行、合并文本转录和音频数据、分割训练和验证集,并将音频列转换为音频对象。
创建时间:
2024-12-06
原始信息汇总
数据集详情
数据集信息
- 特征:
id: 数据类型为int32audio: 音频数据,采样率为 16000text_indo: 印度尼西亚语文本,数据类型为stringtext_en: 英语文本,数据类型为string
- 数据集划分:
train: 包含 2848 条样本,数据大小为 2287307892.865303 字节validation: 包含 713 条样本,数据大小为 572630131.2386969 字节
- 下载大小: 2849087675 字节
- 数据集大小: 2859938024.104 字节
配置
- 默认配置:
train: 数据文件路径为data/train-*validation: 数据文件路径为data/validation-*
任务类别
- 翻译
语言
- 印度尼西亚语 (
id) - 英语 (
en)
数据集规模
- 1K < n < 10K
数据集结构
DatasetDict({ train: Dataset({ features: [id, audio, text_indo, text_en], num_rows: 2848 }), validation: Dataset({ features: [id, audio, text_indo, text_en], num_rows: 713 }), })
数据处理步骤
- 移除不需要的列(仅保留印度尼西亚语音频、转录和英语转录)。
- 移除英语数据集中的重复行。
- 根据
id列合并英语转录与印度尼西亚语音频和转录。 - 划分为训练集和验证集。
- 将音频列转换为音频对象。
引用
@article{fleurs2022arxiv, title = {FLEURS: Few-shot Learning Evaluation of Universal Representations of Speech}, author = {Conneau, Alexis and Ma, Min and Khanuja, Simran and Zhang, Yu and Axelrod, Vera and Dalmia, Siddharth and Riesa, Jason and Rivera, Clara and Bapna, Ankur}, journal = {arXiv preprint arXiv:2205.12446}, url = {https://arxiv.org/abs/2205.12446}, year = {2022} }
搜集汇总
数据集介绍
构建方式
FLEURS_INDO-ENG_Speech_Translation数据集的构建基于FLEURS语音翻译基准,专门针对印度尼西亚语到英语的语音翻译任务。在数据预处理阶段,首先剔除了不需要的列,仅保留印度尼西亚语的音频及其转录文本以及对应的英语转录文本。随后,通过基于'id'列的合并操作,将英语转录文本与印度尼西亚语的音频和转录文本进行匹配。最后,数据集被划分为训练集和验证集,并确保音频列被正确转换为Audio对象格式。
使用方法
FLEURS_INDO-ENG_Speech_Translation数据集适用于语音翻译任务的模型训练和评估。用户可以通过加载数据集的训练集和验证集,利用'audio'列的语音数据和'text_indo'、'text_en'列的文本数据进行模型输入和输出。建议使用支持音频处理的深度学习框架,如PyTorch或TensorFlow,结合语音识别和机器翻译模型进行训练。数据集的清晰结构和高质量数据使其成为语音翻译研究的有力工具。
背景与挑战
背景概述
FLEURS_INDO-ENG_Speech_Translation数据集是针对印度尼西亚语到英语的语音翻译任务而构建的,源自FLEURS数据集,该数据集是FLoRes机器翻译基准的语音版本。FLEURS由Conneau等人于2022年提出,旨在通过少样本学习评估语音的通用表示。该数据集包含了约3561条印度尼西亚语的语音数据,总计约12小时24分钟的音频,涵盖了从印度尼西亚语到英语的语音翻译任务。这一数据集的构建对于推动语音翻译技术的发展具有重要意义,尤其是在多语言语音识别和翻译领域,为研究人员提供了一个高质量的基准数据集。
当前挑战
FLEURS_INDO-ENG_Speech_Translation数据集在构建过程中面临了多项挑战。首先,语音翻译任务本身具有较高的复杂性,涉及语音识别、语言建模和翻译等多个子任务的集成。其次,数据预处理步骤中需要去除不必要的列和重复行,并确保音频与文本的正确对齐,这增加了数据处理的复杂性。此外,语音数据的质量和多样性对模型的性能有直接影响,如何确保数据集的广泛覆盖和高质量是一个持续的挑战。最后,语音翻译模型的训练需要大量的计算资源和时间,如何在有限的资源下优化模型性能也是一个重要的研究方向。
常用场景
经典使用场景
FLEURS_INDO-ENG_Speech_Translation数据集在语音翻译领域中扮演着至关重要的角色。其经典使用场景主要集中在印度尼西亚语到英语的语音翻译任务上,通过提供高质量的语音和对应的文本数据,研究人员能够训练和评估语音翻译模型,尤其是在低资源语言翻译中的表现。该数据集的音频数据采样率为16000Hz,确保了语音信号的清晰度和准确性,为模型提供了丰富的语音特征。
解决学术问题
该数据集有效解决了语音翻译领域中低资源语言翻译的学术难题。通过提供印度尼西亚语到英语的语音和文本对,研究人员能够探索如何在资源有限的情况下提升翻译模型的性能。此外,该数据集还为跨语言语音识别和翻译模型的评估提供了标准化的基准,推动了语音翻译技术的进步,具有重要的学术价值和实际意义。
实际应用
在实际应用中,FLEURS_INDO-ENG_Speech_Translation数据集广泛应用于多语言语音翻译系统、语音助手和跨语言沟通工具的开发。例如,在跨国会议、旅游导览和国际援助等场景中,该数据集支持的语音翻译技术能够帮助用户实现实时、准确的语言转换,极大地促进了跨文化交流和合作。此外,该数据集还可用于开发针对特定语言的语音识别和翻译解决方案,满足不同用户群体的需求。
数据集最近研究
最新研究方向
在语音翻译领域,FLEURS_INDO-ENG_Speech_Translation数据集的最新研究方向主要集中在提升低资源语言的翻译性能。该数据集通过提供印尼语到英语的语音翻译数据,为研究者提供了一个宝贵的资源,以探索如何在有限的数据条件下实现高效的语音翻译模型。前沿研究不仅关注模型的准确性,还着重于模型的鲁棒性和泛化能力,尤其是在面对多样化的语音输入和复杂的语言结构时。此外,该数据集的引入也促进了跨语言语音识别与翻译技术的融合,为多语言语音处理领域的研究开辟了新的路径。
以上内容由遇见数据集搜集并总结生成


