David-Egea/phishing-texts
收藏Hugging Face2024-03-28 更新2024-06-11 收录
下载链接:
https://hf-mirror.com/datasets/David-Egea/phishing-texts
下载链接
链接失效反馈官方服务:
资源简介:
---
license: mit
task_categories:
- text-classification
language:
- en
size_categories:
- 10K<n<100K
tags:
- phishing
- text
pretty_name: Phishing Texts Dataset
---
## Phishing Texts Dataset 🎣
### Description:
This dataset is a collection of data designed for training text classifiers capable of determining whether a message or email is a phishing attempt or not.
### Dataset Information 📨:
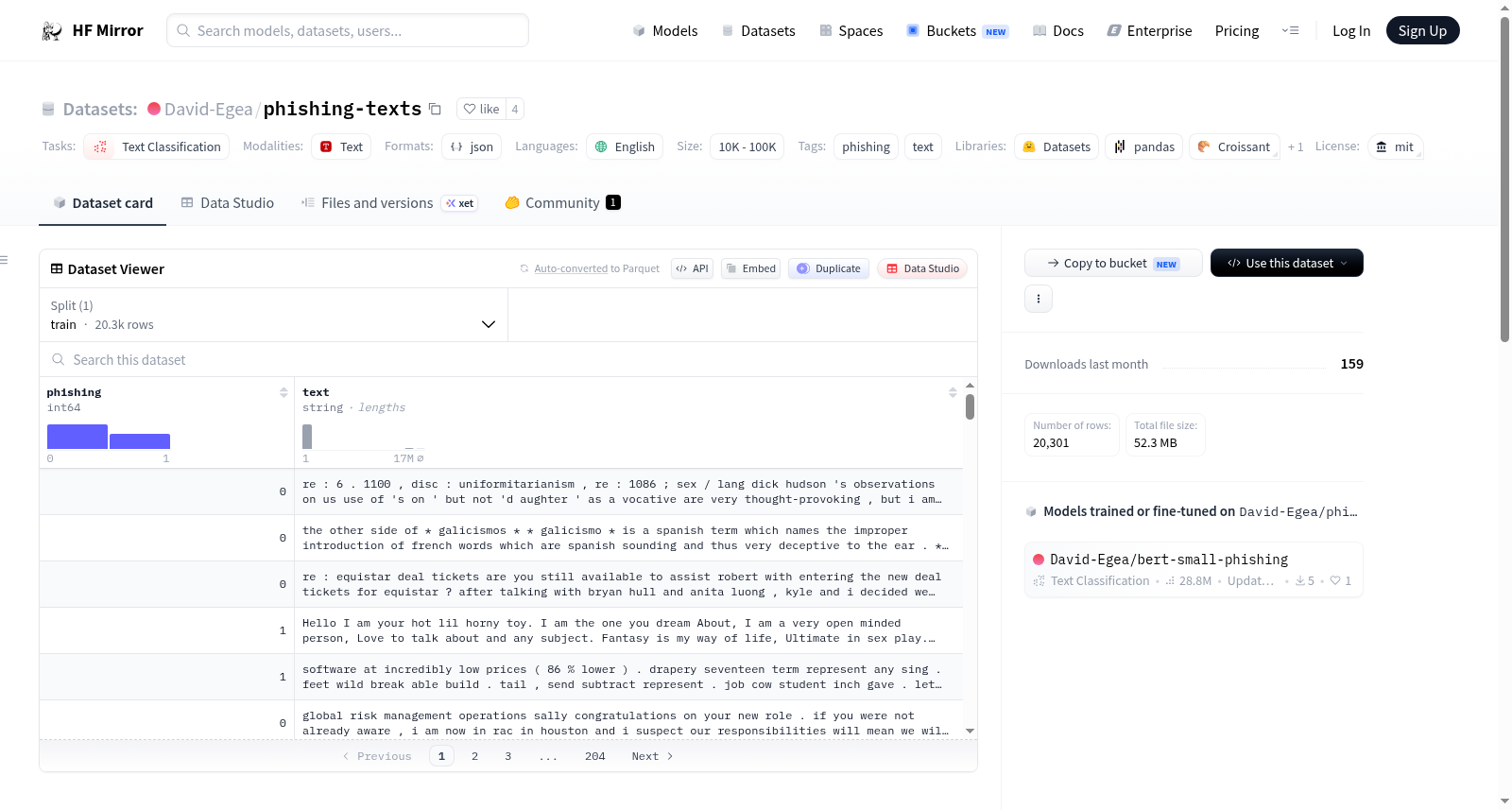
The dataset consists of more than 20,000 entries of text messages, which are potential phishing attempts.
Data is structured in two columns:
- `text`: The text of the message or email.
- `phising`: An indicator of whether the message in the `text` column is a phishing attempt (1) or not (0).
The dataset has undergone a data cleaning process and preprocessing to remove possible duplicate entries.
It is worth mentioning that the dataset is **balanced**, with 62% non-phishing and 38% phishing instances.
In some of the aforementioned datasets, it was identified that the data overlapped.
To avoid redundant values, duplicate entries have been removed from this dataset during the last data cleaning phase.
### Data Sources 📖:
This dataset has been constructed from the following sources:
- [Hugging Face - Phishing Email Dataset](https://huggingface.co/datasets/zefang-liu/phishing-email-dataset)
- [Hugging Face - Phishing Dataset](https://huggingface.co/datasets/ealvaradob/phishing-dataset)
- [Kaggle - Phishing Emails](https://www.kaggle.com/datasets/subhajournal/phishingemails)
- [Kaggle - Phishing Email Data by Type](https://www.kaggle.com/datasets/charlottehall/phishing-email-data-by-type)
> Big thanks to all the creators of these datasets for their awesome work! 🙌
*In some of the aforementioned datasets, it was identified that the data overlapped.
To avoid redundant values, duplicate entries have been removed from this dataset during the last data cleaning phase.*
提供机构:
David-Egea
原始信息汇总
Phishing Texts Dataset 🎣
描述:
该数据集是一个用于训练文本分类器的数据集合,这些分类器能够判断一条消息或电子邮件是否为钓鱼尝试。
数据集信息 📨:
数据集包含超过20,000条文本消息,这些消息可能是钓鱼尝试。
数据结构分为两列:
text:消息或电子邮件的文本。phising:指示text列中的消息是否为钓鱼尝试(1)或不是(0)。
数据集经过数据清洗和预处理,以去除可能的重复条目。值得一提的是,该数据集是平衡的,其中62%为非钓鱼实例,38%为钓鱼实例。
在某些上述数据集中,发现数据存在重叠。为了避免冗余值,在最后一次数据清洗阶段已从该数据集中移除重复条目。
数据来源 📖:
该数据集由以下来源构建:
搜集汇总
数据集介绍
背景与挑战
背景概述
该数据集是一个用于训练网络钓鱼文本分类器的集合,包含超过20,000条文本消息,每条消息标注了是否为网络钓鱼(1表示是,0表示否)。数据集经过清洗和去重处理,且类别分布平衡(62%非网络钓鱼,38%网络钓鱼),适用于机器学习模型训练。
以上内容由遇见数据集搜集并总结生成


