jupyter-agent-dataset
收藏Hugging Face2025-09-04 更新2025-09-05 收录
下载链接:
https://huggingface.co/datasets/data-agents/jupyter-agent-dataset
下载链接
链接失效反馈官方服务:
资源简介:
Jupyter Agent Dataset是一个基于Kaggle笔记本的合成数据集,包含去重、引用数据集、教育质量评分、数据分析相关内容过滤、问题回答对和可执行推理轨迹。数据集分为两个子集:'thinking'和'non-thinking',适合不同类型的模型训练。每个例子包含一个合成笔记本和相应的自然语言问题和验证过的答案。
Jupyter Agent Dataset is a synthetic dataset based on Kaggle notebooks. It includes deduplication, referenced datasets, educational quality scoring, data analysis-related content filtering, question-answer pairs, and executable reasoning traces. The dataset is split into two subsets: 'thinking' and 'non-thinking', which are suitable for training different types of models. Each example contains a synthetic notebook, along with corresponding natural language questions and verified answers.
创建时间:
2025-09-02
原始信息汇总
Jupyter Agent Dataset 概述
数据集基本信息
- 名称:Jupyter Agent Dataset
- 创建者:Hugging Face Data-Agents Team
- 语言:代码
- 许可证:Apache-2.0
- 多语言性:单语言
- 标注创建方式:机器生成
- 标签:jupyter, kaggle, agents, code, synthetic
- 任务类别:问答、文本生成
- 规模类别:10K<n<100K
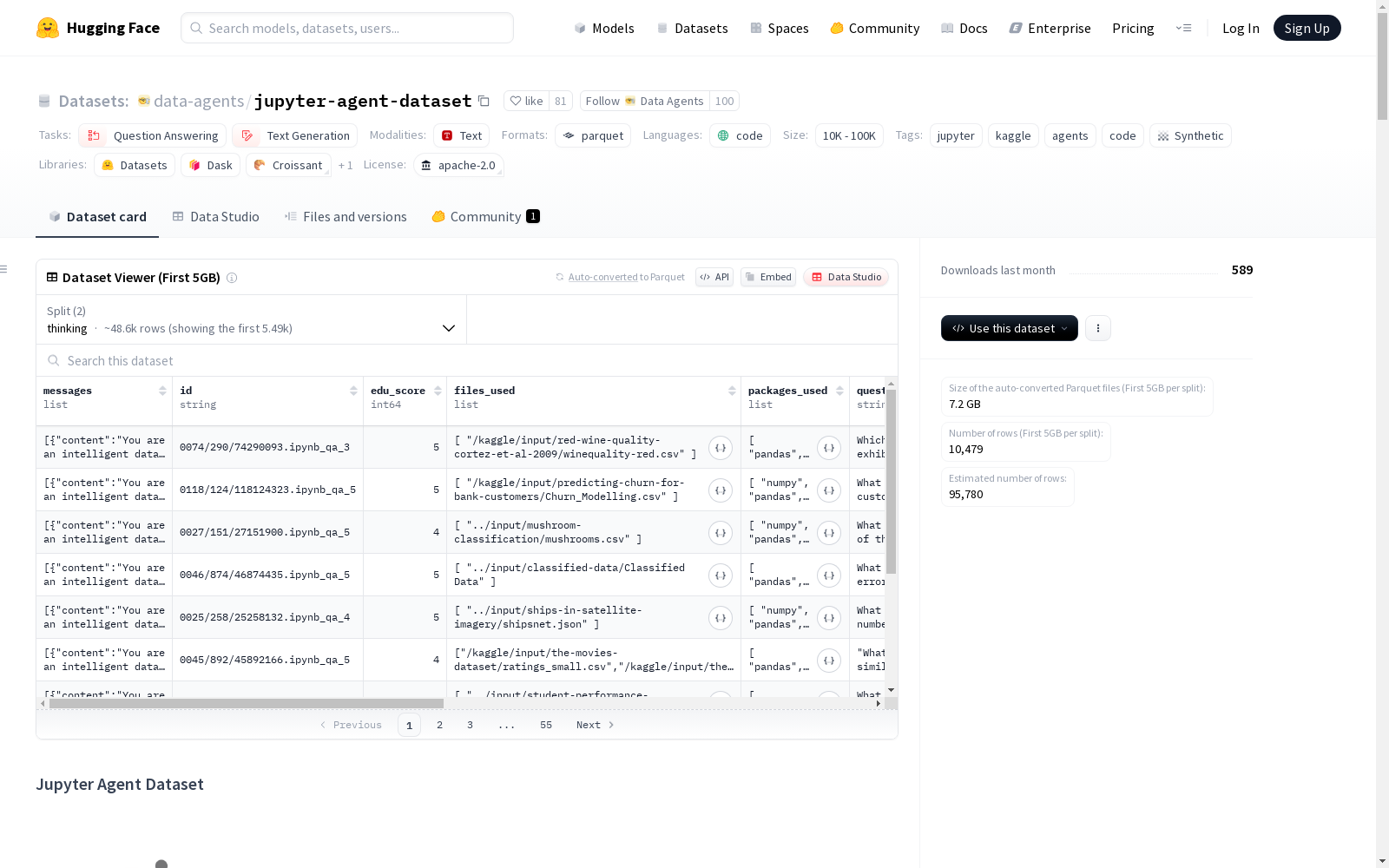
数据集规模与结构
- 总样本数:51,389个合成笔记本
- 训练标记数:约20亿
- 下载大小:71,781,735,066字节
- 数据集大小:102,156,900,168字节
- 特征:
id:笔记本和问题对的唯一标识符messages:ChatML格式的合成笔记本question:基于笔记本/数据集的自然语言问题answer:经过验证的简短最终答案edu_score:教育质量评分files_used:原始Kaggle笔记本中使用的文件packages_used:原始Kaggle笔记本中使用的包kaggle_dataset_name:Kaggle源数据集名称executor_type:代码执行器类型original_notebook:原始Kaggle源笔记本tools:用于笔记本生成的工具调用
数据子集
- thinking子集:
- 字节数:51,081,197,281
- 样本数:51,389
- non_thinking子集:
- 字节数:51,075,702,887
- 样本数:51,389
用途
- 训练能够阅读笔记本和数据集上下文的代码代理
- 执行Python代码回答基于数据集的问题
- 生成带有中间计算的逐步解决方案
数据集创建过程
-
数据来源与准备:
- 大规模去重Kaggle笔记本
- 通过Kaggle元数据自动获取链接数据集
- 使用Qwen-32B进行教育质量评分
- 过滤不相关的笔记本
-
合成笔记本生成:
- 使用Qwen-32B生成基于数据集的问答对
- 使用Qwen-Coder-480B生成代码/思考执行轨迹
- 使用E2B进行安全沙箱执行
技术工具
- Datatrove:大规模处理Kaggle笔记本和数据集
- Qwen-32B:评分和问答生成
- Qwen-Coder-480B:笔记本和代码执行轨迹生成
- E2B:安全沙箱执行
许可信息
- 数据集使用Apache-2.0许可证
- 使用引用的Kaggle笔记本或数据集必须遵守Kaggle服务条款和原始作者许可
引用信息
@misc{jupyteragentdataset, title={Jupyter Agent Dataset}, author={Baptiste Colle and Hanna Yukhymenko and Leandro von Werra}, year={2025} }
搜集汇总
数据集介绍
构建方式
在数据科学教育领域,Jupyter Agent Dataset的构建采用多阶段流水线处理真实Kaggle笔记本数据。通过大规模去重技术筛选公开Kaggle笔记本,自动获取关联数据集确保可执行性,并运用Qwen-32B模型对笔记本教育质量进行智能评分。采用两阶段生成流程:先由大语言模型生成数据集相关的问答对,再通过上下文验证减少幻觉;最后通过Qwen-Coder-480B模型结合E2B沙箱执行环境生成代码执行轨迹,形成包含5万余个合成笔记本的高质量训练资源。
特点
该数据集的核心特征体现在其双重子集架构与结构化数据设计。thinking与non_thinking两个子集分别提供带思考标签和无标签的代码生成注释,适配不同基础模型需求。数据集采用ChatML格式封装合成笔记本,包含经过验证的问答对、教育质量评分及工具调用信息。每个样本均标注使用的Kaggle数据集名称、依赖包和执行器类型,并保留原始笔记本引用,为智能代理训练提供约20亿训练令牌的丰富语义上下文和可执行代码轨迹。
使用方法
研究人员可通过Hugging Face数据集库直接加载该资源,使用标准代码接口获取thinking或non_thinking子集。训练时只需提取messages和tools列数据即可与TRL训练框架无缝对接。实际应用中,可结合Kaggle Hub下载原始数据集,通过E2B代码解释器在安全沙箱环境中执行生成代码,验证代理模型的数据分析能力。该数据集专为训练具备笔记本上下文理解、Python代码执行及分步推理能力的智能代理而优化,显著提升模型在DABstep基准测试中的表现。
背景与挑战
背景概述
Jupyter Agent Dataset由Hugging Face数据智能团队于2025年发布,核心成员包括Baptiste Colle、Hanna Yukhymenko和Leandro von Werra。该数据集聚焦于代码智能代理领域,通过系统化处理真实Kaggle笔记本数据,构建包含自然语言问题、可执行代码轨迹及验证答案的高质量语料。其创新在于采用多阶段合成管道,融合去重处理、教育质量评分及沙箱执行验证,显著提升了代码生成模型在数据分析和探索性任务中的表现,为自动化编程助手研究提供了重要基础设施。
当前挑战
该数据集致力于解决代码生成与执行场景中模型对真实数据分析任务的适应性挑战,包括复杂上下文理解、多步代码推理及动态环境交互等核心难题。构建过程中面临多重技术挑战:需确保Kaggle笔记本与关联数据集的合法合规使用,实现大规模去重与质量过滤;通过合成管道生成高质量问答对时需克服幻觉问题;代码执行轨迹的采集需协调沙箱安全性与环境一致性,同时保持生成内容的可复现性与教育价值。
常用场景
经典使用场景
在代码智能体研究领域,Jupyter Agent Dataset通过整合真实Kaggle笔记本与数据集上下文,为训练具备代码执行能力的智能体提供了标准范式。该数据集典型应用于教导模型理解自然语言问题、生成可执行的Python代码(如pandas数据操作、matplotlib可视化),并逐步推导出经过验证的答案。其多轮对话结构与工具调用机制完美适配了现代大语言模型的指令微调框架,成为代码生成与推理任务的核心训练资源。
实际应用
在实际应用层面,该数据集支撑的智能体可广泛应用于数据科学教育、自动化报告生成和商业智能分析场景。教育机构可利用其构建交互式编程助手,实时指导学习者进行数据探索与分析;企业则可部署基于该数据训练的智能体,自动处理内部数据查询需求,生成可视化洞察报告。其与Kaggle生态的深度整合更为跨领域数据分析任务提供了标准化解决方案。
衍生相关工作
基于该数据集衍生的经典工作包括Hugging Face团队开发的Qwen-3-4B-Instruct-2507和Qwen-3-4B-Thinking-2507模型,这些模型在代码推理能力上实现了显著突破。后续研究进一步扩展了其在多模态代码生成、自适应工具调用等方向的应用,催生了如TRL训练框架的优化迭代和E2B沙箱执行环境的标准化集成,推动了整个代码智能体领域的协同发展。
以上内容由遇见数据集搜集并总结生成


