---
language:
- en
license: cc-by-4.0
size_categories:
- 100K<n<1M
pretty_name: WebSightDescribed
dataset_info:
- config_name: v0.1
features:
- name: image
dtype: image
- name: html
dtype: string
- name: nl_description
dtype: string
- name: id
dtype: string
splits:
- name: train
num_bytes: 45056592
num_examples: 526781
- name: valid
num_bytes: 394432
num_examples: 4733
- name: test
num_bytes: 16496
num_examples: 200
download_size: 144861710051
dataset_size: 368943620718.125
configs:
- config_name: v0.1
data_files:
- split: train
path: wsd_data/train/data-*
- split: valid
path: wsd_data/valid/data-*
- split: test
path: wsd_data/test/data-*
tags:
- code
- synthetic
---
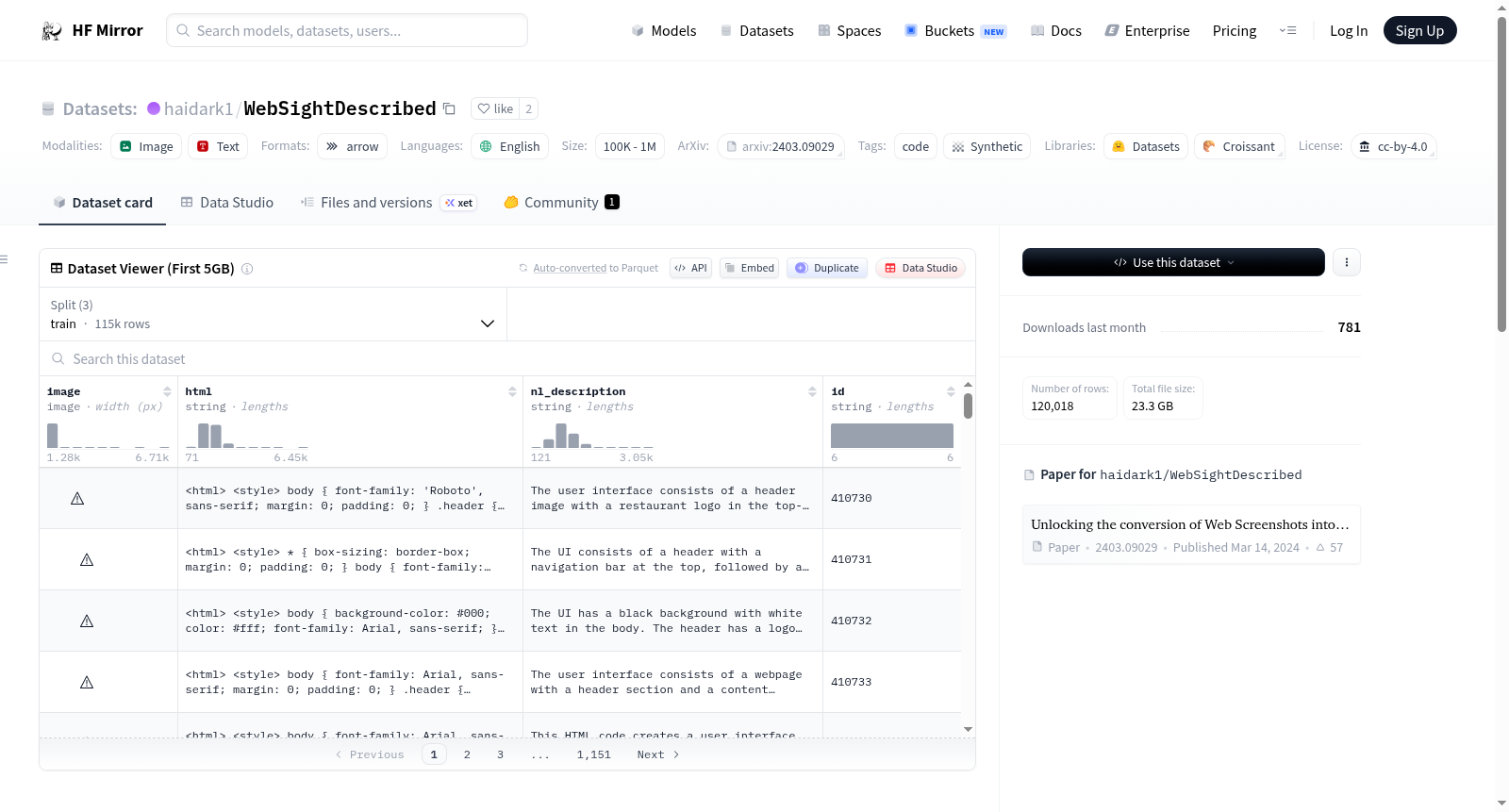
# Dataset Card for WebSightDescribed
## Dataset Description
WebSightDescribed is a subset of [WebSight v0.1](https://huggingface.co/datasets/HuggingFaceM4/WebSight), augmenting the dataset with
synthetically generated natural language descriptions of the websites.
This dataset serves as a valuable resource for the task of generating html code from a natural language description.
<details>
<summary>Details for WebSightDescribed</summary>
## Data Fields
An example of a sample appears as follows:
```
{
'image': PIL.Image,
'id': int,
'html': '<html>\n<style>\n{css}</style>\n{body}\n</html>',
'description': 'a natural language description of the UI'
}
```
where `css` is the CSS code, and `body` is the body of the HTML code.
In other words, the CSS code is embedded directly within the HTML code, facilitating the straightforward training of a model.
The `id` field corresponds to the row number from [WebSight v0.1](https://huggingface.co/datasets/HuggingFaceM4/WebSight).
## Data Splits
There are three splits, `train`, `valid`, and `test`, that contains 531,714 images, descriptions, and codes.
## Dataset Creation
In addition to the steps used to create [WebSight v0.1](https://huggingface.co/datasets/HuggingFaceM4/WebSight),
we used gpt=3.5-turbo to generate natural language descriptions of the UI represented by the html code.
The following system prompt was used:
```
You are an AI assistant that specializes in HTML code. You are able to read HTML code and visualize the rendering of the HTML on a standard browser. When asked to write descriptions of HTML code, you describe how the user interface looks rendered in a standard browser (like Google Chrome). The user will provide you with HTML code and you will respond describing exactly how the code looks if rendered in a browser. Describe the colors exactly. Repeat ALL the text in the HTML code in your description. This is important - in your description do NOT omit any text rendered by the HTML code. Finally write your description like a customer describing a UI for a developer. Avoid any and all pleasantries, write the description like a straightforward description of the UI.
```
The html code was provided as the one and only user message and the response was saved as the natural language description.
</details>
## Terms of Use
By using the dataset, you agree to comply with the original licenses of the source content as well as the dataset license (CC-BY-4.0). Additionally, if you use this dataset to train a Machine Learning model, you agree to disclose your use of the dataset when releasing the model or an ML application using the model.
### Licensing Information
License CC-BY-4.0.
### Citation Information
If you are using this dataset, please cite this dataset and the original WebSight [technical report](https://arxiv.org/abs/2403.09029)
```
@misc{khan2024described,
title={WebSightDescribed: Natural language description to UI},
author={Haidar Khan},
year={2024},
url={https://huggingface.co/datasets/haidark1/WebSightDescribed}
}
@misc{laurençon2024unlocking,
title={Unlocking the conversion of Web Screenshots into HTML Code with the WebSight Dataset},
author={Hugo Laurençon and Léo Tronchon and Victor Sanh},
year={2024},
eprint={2403.09029},
archivePrefix={arXiv},
primaryClass={cs.HC}
}
```
---
语言:
- 英语
许可证:
cc-by-4.0
规模类别:
- 100K<n<1M
展示名称:
WebSightDescribed
数据集信息:
- 配置名称: v0.1
特征:
- 字段名: 图像(image)
数据类型: 图像
- 字段名: HTML代码(html)
数据类型: 字符串
- 字段名: 自然语言描述(nl_description)
数据类型: 字符串
- 字段名: 标识符(id)
数据类型: 字符串
划分:
- 划分名称: 训练集(train)
字节数: 45056592
样本数: 526781
- 划分名称: 验证集(valid)
字节数: 394432
样本数: 4733
- 划分名称: 测试集(test)
字节数: 16496
样本数: 200
下载大小: 144861710051
数据集总大小: 368943620718.125
配置项:
- 配置名称: v0.1
数据文件:
- 划分: 训练集(train)
路径: wsd_data/train/data-*
- 划分: 验证集(valid)
路径: wsd_data/valid/data-*
- 划分: 测试集(test)
路径: wsd_data/test/data-*
标签:
- 代码(code)
- 合成数据(synthetic)
---
# WebSightDescribed 数据集卡片
## 数据集概述
WebSightDescribed 是 [WebSight v0.1](https://huggingface.co/datasets/HuggingFaceM4/WebSight) 的子集,为该数据集增补了针对各类网站的合成生成式自然语言描述。本数据集可作为「基于自然语言描述生成HTML代码」任务的优质研究资源。
<details>
<summary>WebSightDescribed 详细说明</summary>
## 数据字段
单条样本的示例格式如下:
{
'image': PIL.Image,
'id': int,
'html': '<html>
<style>
{css}</style>
{body}
</html>',
'description': 'a natural language description of the UI'
}
其中`css`为级联样式表(CSS)代码,`body`为HTML代码的主体部分。换言之,CSS代码直接内嵌于HTML代码中,可方便模型进行直接训练。`id`字段对应原 [WebSight v0.1](https://huggingface.co/datasets/HuggingFaceM4/WebSight) 数据集的行号。
## 数据划分
本数据集包含训练集、验证集与测试集三个划分,共计531,714条图像、描述与代码样本。
## 数据集构建
除构建 [WebSight v0.1](https://huggingface.co/datasets/HuggingFaceM4/WebSight) 所采用的步骤外,我们还使用GPT-3.5-turbo大语言模型(Large Language Model, LLM)生成了基于HTML代码所表征的用户界面(User Interface, UI)的自然语言描述。本次实验使用了如下系统提示词:
您是一名专精于HTML代码的AI助手,能够阅读HTML代码并可视化该代码在标准浏览器中的渲染效果。当被要求描述HTML代码时,请描述该HTML代码在标准浏览器(如谷歌浏览器(Google Chrome))中渲染后的用户界面外观,准确描述配色细节,并在描述中完整复现HTML代码中的所有文本内容——这一点至关重要,请勿遗漏任何由HTML代码渲染的文本。最后,请以客户向开发人员描述用户界面的口吻撰写描述,避免任何客套话语,以直白简洁的方式描述界面。
将HTML代码作为唯一的用户输入消息,模型的响应即被保存为自然语言描述。
</details>
## 使用条款
使用本数据集即表示您同意遵守源内容的原始许可协议以及本数据集的许可协议(CC-BY-4.0)。此外,若您使用本数据集训练机器学习(Machine Learning, ML)模型,在发布该模型或基于该模型开发的机器学习应用时,需披露本数据集的使用情况。
### 许可信息
本数据集采用CC-BY-4.0许可协议。
### 引用说明
若您使用本数据集,请引用本数据集以及原始WebSight的[技术报告](https://arxiv.org/abs/2403.09029):
@misc{khan2024described,
title={WebSightDescribed: Natural language description to UI},
author={Haidar Khan},
year={2024},
url={https://huggingface.co/datasets/haidark1/WebSightDescribed}
}
@misc{laurençon2024unlocking,
title={Unlocking the conversion of Web Screenshots into HTML Code with the WebSight Dataset},
author={Hugo Laurençon and Léo Tronchon and Victor Sanh},
year={2024},
eprint={2403.09029},
archivePrefix={arXiv},
primaryClass={cs.HC}
}