QCRI/IslamicFaithQA
收藏Hugging Face2026-04-30 更新2026-02-07 收录
下载链接:
https://hf-mirror.com/datasets/QCRI/IslamicFaithQA
下载链接
链接失效反馈官方服务:
资源简介:
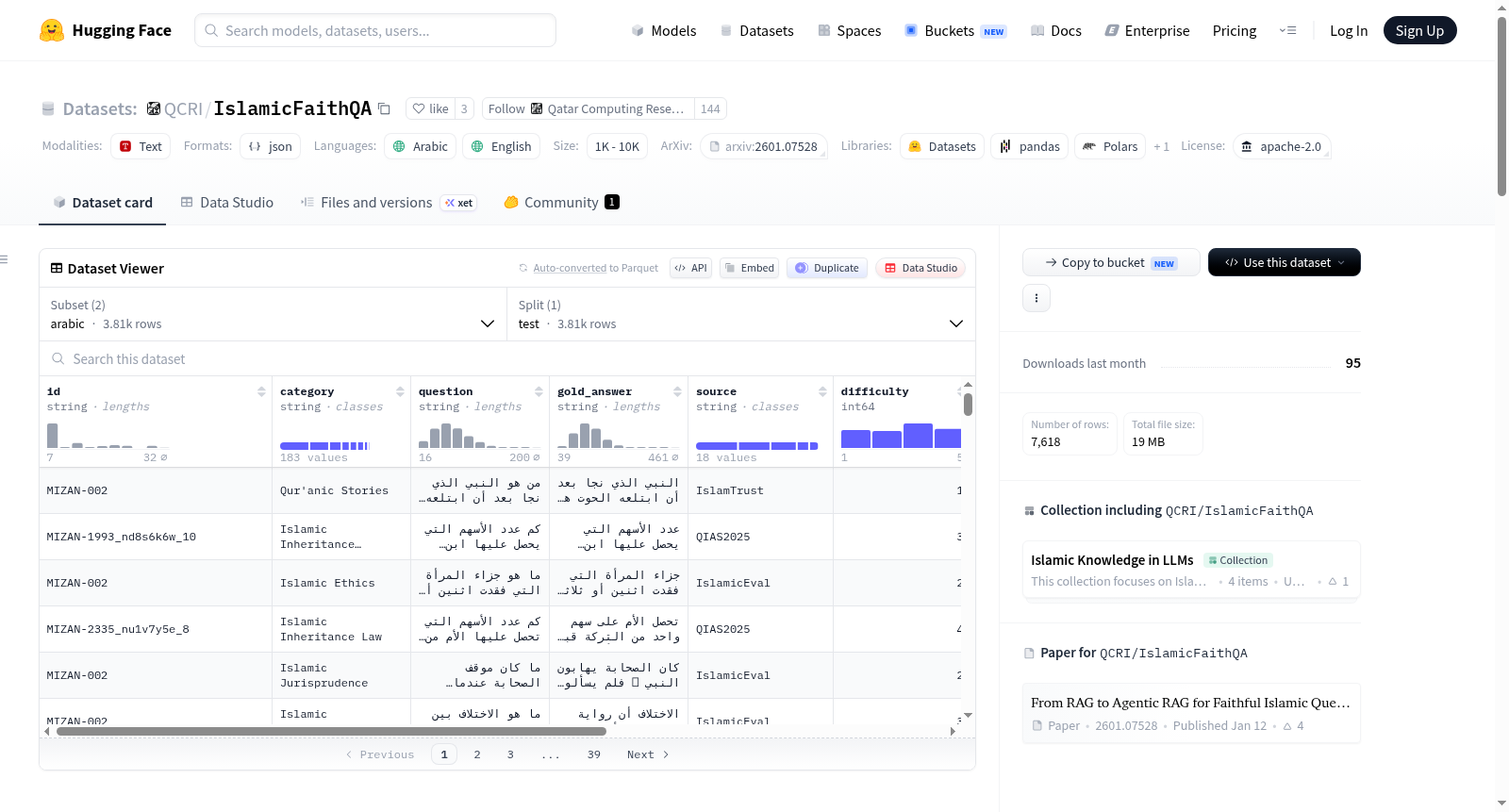
IslamicFaithQA是一个双语(阿拉伯语/英语)的生成式伊斯兰问答基准,旨在支持关于伊斯兰问答中正确性、减少幻觉和避免行为的研究。数据集包含两种配置(阿拉伯语和英语),每种配置包含一个测试分割。每个示例包含多个字段,如唯一标识符、细粒度主题标签、问题文本、黄金答案、来源标签、难度评级、是否需要推理、是否需要多步骤、高级类别分组和可选错误字段。数据集适用于评估生成式伊斯兰问答系统的忠实性和减少幻觉,但不建议将其作为宗教权威工具的替代品。
IslamicFaithQA is a bilingual (Arabic/English) generative Islamic question answering benchmark designed for faithfulness-oriented evaluation. The dataset is intended to support research on correctness, hallucination reduction, and abstention behavior in Islamic QA. It includes two configurations (Arabic and English), each containing a single test split. Each example features fields such as unique identifier, fine-grained topic label, question text, gold answer, source label, difficulty rating, whether reasoning is required, whether multiple steps are needed, higher-level category grouping, and an optional error field. The dataset is suitable for evaluating generative Islamic QA systems for faithfulness and controlled hallucination but is not recommended as a replacement for qualified scholarly guidance.
提供机构:
QCRI
搜集汇总
数据集介绍
构建方式
IslamicFaithQA数据集是基于伊斯兰教义问答领域构建的双语生成式评测基准,旨在支持忠实性导向的问答系统评估。该数据集的构建依托于多源宗教文本资源,通过专家筛选与标注形成覆盖广泛教义主题的问答对。每个样本包含唯一标识符、细粒度类别标签、问题文本、标准答案、来源标注、难度等级(1-5级)、是否需推理、是否多步骤等元信息。数据以JSONL格式存储,分为阿拉伯语和英语两个独立配置,每个配置仅包含测试集,便于直接在忠实性评估场景中使用。
特点
IslamicFaithQA数据集的核心特点在于其专为评估生成式伊斯兰问答系统的忠实性而设计,特别关注幻觉抑制与拒答行为的度量。数据集的难度分级、推理需求与多步骤标记使得研究者能够进行分层分析,深入理解模型在不同复杂度问题上的表现。此外,双语配置(阿拉伯语与英语)允许跨语言泛化能力的检验,而详细的来源与类别信息则支持对模型知识溯源能力的细粒度诊断。该数据集强调严格的忠实性评估,避免将模型输出视为宗教权威。
使用方法
使用IslamicFaithQA数据集时,研究者可通过HuggingFace Datasets库加载,指定'arabic'或'english'配置即可获取对应语言的测试集。每个样本中的'question'字段可用于输入模型生成回答,而'gold_answer'字段作为参考标准用于评估生成结果的忠实性与准确性。该数据集特别适用于结合检索增强生成或智能体方法进行幻觉分析与拒答策略研究。建议在评估时利用难度、推理与多步骤字段进行分层验证,以全面衡量模型在处理伊斯兰教义问答时的可靠性。
背景与挑战
背景概述
IslamicFaithQA是由卡塔尔计算研究所(QCRI)联合多所高校及研究机构于2026年发布的双语(阿拉伯语/英语)生成式伊斯兰问答基准数据集,相关研究成果发表于ACL 2026。该数据集旨在填补宗教领域对大语言模型忠实性评估的空白,核心研究问题聚焦于如何提升生成式问答在伊斯兰教义场景下的正确性、减少幻觉以及实现模型适时的拒答行为。其发布对计算语言学与伊斯兰研究交叉领域产生了重要影响,为检索增强生成(RAG)及智能体RAG方法在高度严谨的知识域中的应用提供了标准化评测平台,推动了更可靠的宗教问答系统发展。
当前挑战
该数据集面临的挑战主要体现在两方面。领域问题层面,伊斯兰教义问答对答案的权威性与精确性要求极高,大语言模型易产生与教义相悖的幻觉内容,且面临何时应主动拒答的棘手问题。构建过程层面,研究者需确保双语数据在翻译与标注过程中的语义保真度,针对宗教信仰相关问答构建1-5级难度评估体系及推理、多步骤等元标签,同时平衡数据的宗教敏感性与学术开放性,以避免误导性解读和不当使用。
常用场景
经典使用场景
在伊斯兰教义问答这一高知识壁垒领域,IslamicFaithQA被设计为一份双语的生成式问答评测基准,专注于忠实度导向的评估。研究者可借助其阿拉伯语与英语双配置,对模型生成的开放式答案进行严格或基于裁判的评估,从而系统性地衡量模型在回答伊斯兰教义问题时的正确性、幻觉控制能力及克制机制的表现。该数据集尤其适合用于分层分析,依据问题难度、是否需要推理及多步推理等维度,深入探究模型在不同复杂度下的行为特征。
实际应用
在实际部署中,IslamicFaithQA可作为宗教知识问答系统的质量评估工具,帮助开发者衡量智能助手在伊斯兰教义咨询、在线学习平台及多语言宗教资源整合中的表现。其双语言特性支持面向阿拉伯语母语社区与英语研究群体的跨文化应用,尤其适用于构建具备可靠来源核对与弃权机制的教义问答机器人。此外,该数据集也可融入教育科技产品,用于自动评估学生对伊斯兰知识理解的准确性,或辅助宗教研究机构开展大规模文本一致性审查。
衍生相关工作
该数据集的发布直接催生了一系列关于忠实伊斯兰问答系统的经典工作,其中最核心的是提出了从RAG到代理式RAG的方法论跃迁,通过引入多智能体协作、记忆检索与动态信息整合,显著提升了生成内容的忠实度。后续研究进一步借鉴其分层评估设计,探索了面向伊斯兰法律的推理增强模型、基于难度感知的答案校准策略,以及多步推理在宗教知识图谱上的应用。此外,该数据集还推动了针对高利害领域的弃权行为建模,衍生出关于模型不确定性量化与知识边界识别的新研究方向。
以上内容由遇见数据集搜集并总结生成


