nutribench-subset-cs-ja-yue
收藏Hugging Face2026-04-01 更新2026-04-02 收录
下载链接:
https://huggingface.co/datasets/chubao/nutribench-subset-cs-ja-yue
下载链接
链接失效反馈官方服务:
资源简介:
NutriBench子集——日语/粤语代码切换扩展是一个包含1,000个样本的数据集,源自NutriBench v2,并扩展了四个额外的餐食描述列,涵盖日语和粤语的单语及代码切换变体。该数据集旨在研究代码切换(将传统语言文本与英语食品术语混合)对大型语言模型在碳水化合物估计性能上的影响。数据集通过分层随机抽样从NutriBench v2的训练集中选取,保留了原始的行索引以便追溯。新增的列包括日语和粤语的完整翻译及代码切换版本,所有翻译均使用GPT-5.4生成,并经过严格的质量控制。数据集适用于文本分类任务,特别是与营养、食品和代码切换相关的研究。数据集遵循CC-BY-NC-SA-4.0许可。
创建时间:
2026-03-31
原始信息汇总
NutriBench Subset — Code-Switching JA/YUE Extension 数据集概述
数据集基本信息
- 数据集名称:NutriBench Subset — Code-Switching JA/YUE Extension
- 许可证:CC-BY-NC-SA-4.0
- 任务类别:文本分类
- 支持语言:英语、日语、粤语
- 标签:营养、语码转换、NutriBench、食品
- 数据规模:1K<n<10K
- 数据集简介:该数据集是NutriBench v2的一个1,000样本子集,扩展了四个涵盖日语和粤语单语及语码转换变体的餐食描述列。
研究背景与目的
- 研究问题:语码转换(将传统语言文本与英语食品术语混合)是否会影响大语言模型从餐食描述中进行碳水化合物估算的性能?
- 研究背景:该数据集为伦敦大学学院COMP0087课程项目的研究问题2(RQ2)而构建。一个涵盖RQ1(六语言单语评估)的姊妹数据集可在MikeQian/Nutribench_subset_with_six_languages获取。
数据来源与采样
- 源数据集:NutriBench v2 (dongx1997/NutriBench),相关论文为《NutriBench: A Dataset for Evaluating Large Language Models in Calorie Estimation from Meal Descriptions》。
- 采样策略:从NutriBench v2训练集(15,617行)中通过分层随机抽样(种子=42)抽取1,000行。分层依据为
country×serving_type("metric" / "natural")的交叉。共25个非空层,每层贡献40个样本。原始行索引保留在sample_id列中以便追溯。
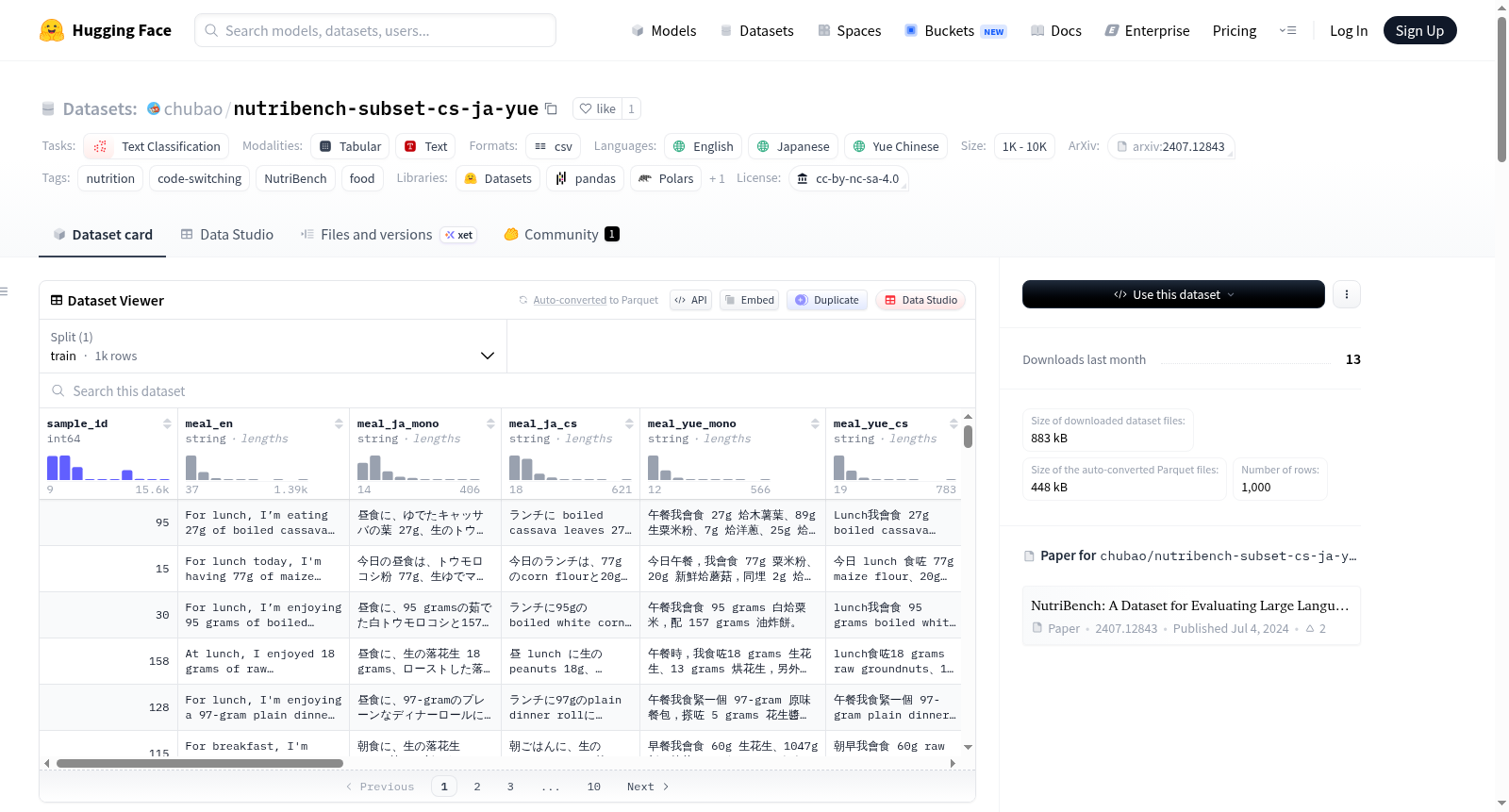
数据结构与列描述
新增列
| 列名 | 描述 |
|---|---|
meal_ja_mono |
英语餐食描述的完整日语翻译 |
meal_ja_cs |
以日语为基础,并混入英语食品术语的语码转换文本 |
meal_yue_mono |
英语餐食描述的完整粤语(繁体中文)翻译 |
meal_yue_cs |
以粤语为基础,并混入英语食品术语的语码转换文本 |
原始列(来自NutriBench v2)
sample_id, meal_en, carb, fat, protein, energy, serving_type, country,以及字符长度列和质量控制标志列。
数据生成方法
- 翻译模型:使用GPT-5.4生成所有四个新增列。
- 单语列生成:
meal_ja_mono:通过qc_japanese.py脚本,使用专业日语食品营养日志翻译提示进行翻译,并进行数字和脚本验证的质量控制,最多5次自我修复尝试。meal_yue_mono:通过add_cantonese.py脚本,使用专业香港粤语翻译提示进行翻译,并进行数字保留和字符验证的质量控制,最多5次自我修复尝试。
- 语码转换列生成:
- 使用
src/rq2_codeswitch/codeswitch_llm.py脚本,采用GPT-5.4的Style C提示风格生成。 meal_yue_cs:采用模拟香港人在WhatsApp或Instagram上使用粤语夹杂英语描述餐食的提示规则。meal_ja_cs:采用模拟日本人在Instagram或Twitter上使用日语夹杂英语描述餐食的提示规则。- 质量控制:检查数字不匹配、单位不匹配或未检测到内联语码转换,最多进行5次自我修复尝试。少量行带有
qc_flags_ja/qc_flags_yue注释以标示残留的质量问题。
- 使用
许可证信息
- 本数据集衍生自NutriBench v2,因此同样在CC-BY-NC-SA-4.0许可证下发布。
搜集汇总
数据集介绍
构建方式
在营养信息学领域,为探究代码转换对大型语言模型营养素估算的影响,本数据集从NutriBench v2原始训练集中通过分层随机抽样策略提取了1000个样本。抽样过程以国家与份量类型为分层依据,确保25个非空层各贡献40个样本,同时保留原始行索引以实现数据溯源。随后,利用GPT-5.4模型生成日语和粤语的单语及代码转换版本,通过精心设计的系统提示与质量控制流程,确保翻译的准确性与语言混合的自然性。
特点
该数据集的核心特点在于其多语言代码转换设计,涵盖了英语、日语和粤语三种语言,并专门构建了单语与代码转换两种文本变体。数据样本均附带详细的营养学标注,包括碳水化合物、脂肪、蛋白质及能量值,并保留了原始数据中的国家与份量类型信息。其构建严格遵循社交媒体的自然语言风格,旨在模拟真实场景下的语言使用习惯,为研究语言混合现象对模型性能的影响提供了高质量、结构化的实验材料。
使用方法
研究者可利用此数据集评估大型语言模型在处理多语言及代码转换文本时的营养素估算能力。数据加载后,可通过对比`meal_ja_mono`与`meal_ja_cs`或`meal_yue_mono`与`meal_yue_cs`列,分析代码转换对模型预测准确性的影响。建议结合原始英语描述`meal_en`及其营养标签进行基准测试,并利用`country`和`serving_type`字段进行跨文化或计量单位的子组分析。使用时应遵守CC-BY-NC-SA-4.0许可协议,并引用原始NutriBench文献。
背景与挑战
背景概述
在营养信息学与计算语言学交叉领域,精准地从膳食描述中估算营养成分是推动个性化健康应用的关键。NutriBench数据集由Dong等人于2024年创建,旨在评估大语言模型在卡路里估算任务上的性能。作为其衍生子集,nutribench-subset-cs-ja-yue由伦敦大学学院(UCL)COMP0087课程项目团队构建,专注于探究代码转换现象对模型碳水化合物估算能力的影响。该数据集通过引入日语和粤语的单语及代码转换变体,拓展了多语言营养文本分析的边界,为跨文化饮食研究提供了新的实证基础。
当前挑战
该数据集致力于解决营养文本中代码转换对营养素估算模型性能影响的评估挑战,核心在于量化语言混合模式下模型理解的偏差与鲁棒性。在构建过程中,研究者面临多重技术难题:首先,需确保日语和粤语翻译在保留原始数值与单位精确性的同时,维持自然流畅的日常表达风格;其次,生成符合社交媒体语境的代码转换文本时,必须在语言混合的度与真实性之间取得平衡,避免过度英文化或丧失本土语言特征;此外,质量控制环节需检测并修复数字不匹配、单位错误及未发生代码转换等异常,这依赖于迭代式的自我修复机制与人工校验的结合,增加了数据生成的复杂度与成本。
常用场景
解决学术问题
该数据集核心解决了语码转换对营养估算模型性能影响的学术问题,填补了多语言营养计算研究中语码转换效应量化分析的空白。通过严谨的抽样策略与高质量翻译生成,它使得研究者能够系统比较单语与语码转换文本在营养参数预测上的差异,从而揭示语言混合可能引入的偏差或优势。这一工作不仅推动了营养信息提取技术的跨语言泛化研究,也为理解语言接触现象在计算任务中的具体表现提供了实证基础。
衍生相关工作
该数据集衍生的经典工作包括对大型语言模型在多语言营养估算任务中的系统性评估框架,以及语码转换生成与质量控制方法的创新。相关研究进一步探索了不同提示策略对翻译与代码转换质量的影响,并扩展至其他语言对的类似分析。这些工作深化了对语言多样性条件下模型鲁棒性的理解,为后续开发更适应混合语言输入的营养计算模型奠定了方法论基础,推动了跨语言自然语言处理技术在健康领域的应用进展。
以上内容由遇见数据集搜集并总结生成


