Agriculture_NER_Dataset_for_FAIR_Metadata_Enrichment
收藏Hugging Face2025-12-07 更新2025-12-08 收录
下载链接:
https://huggingface.co/datasets/IT-ZBMED/Agriculture_NER_Dataset_for_FAIR_Metadata_Enrichment
下载链接
链接失效反馈官方服务:
资源简介:
该数据集是一个手动标注的文本语料库,专为农业研究中的命名实体识别(NER)设计,由FAIRagro支持。它包含对各种实体的标注,如作物、土壤属性、位置和时间陈述。数据集以多种格式提供,针对不同的模型架构和评估场景进行了优化。它支持英语和德语,旨在用于从非结构化文本(如数据集摘要)中提取元数据以进行丰富。
创建时间:
2025-12-05
原始信息汇总
数据集概述
基本信息
- 数据集名称: agri_fair_metadata_ner
- 发布方/支持方: FAIRagro
- 许可协议: Creative Commons Attribution 4.0 International (CC BY 4.0)
- 许可协议链接: https://creativecommons.org/licenses/by/4.0/
- 任务类别: 标记分类
- 语言: 英语、德语
- 标签: 农业、命名实体识别、NER、LLM、作物、土壤、时间陈述、位置
- 数据规模: 1K<n<10K
- 版本: 1.0.0
数据集详情
该数据集是一个手动标注的文本语料库,旨在支持农业研究中的命名实体识别模型,以自动化从非结构化文本(如数据集摘要)中提取元数据,从而实现元数据富集。
数据格式与配置
数据集提供多种格式,当前页面配置为句子级分词格式。
- 配置名称: sentence_split
- 数据文件:
- 训练集:
sentence_split/train-* - 测试集:
sentence_split/test-*
- 训练集:
- 下载大小: 374,636 字节
- 数据集大小: 2,378,375 字节
- 数据分割:
- 训练集: 2,722 个样本
- 测试集: 319 个样本
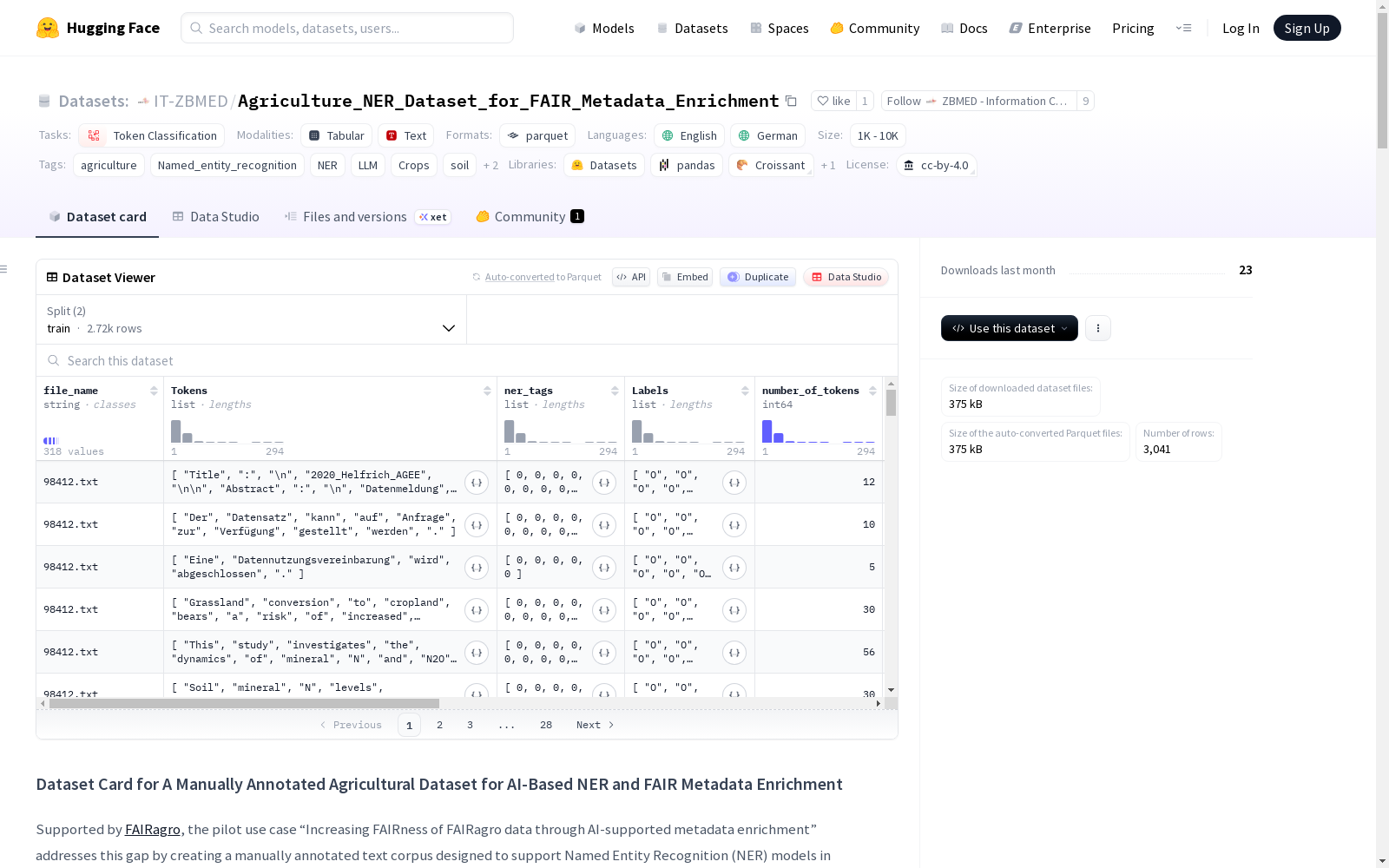
特征列说明
- file_name: 文档的唯一文件名ID。
- Tokens: 词元列表。
- ner_tags: 用于训练的标签整数映射。
- Labels: 与词元1:1对齐的BIO标签。
- number_of_tokens: 总词元数。
- Language: 语言标识("en" 或 "de")。
- source: 来源知识库("BonaRes" 或 "OpenAgrar")。
- Label_counts: 标注频率的计数器对象。
- number_of_annotations: 所有已标注实体跨度的总和。
- doi: 文档DOI(如可用)。
- sentence_id: 句子标识符,格式为
fileID-sentenceIndex。
标注实体与定义
数据集标注了以下实体及其属性:
| 实体 | 属性 | 定义 |
|---|---|---|
| Crop | Crop species | 植物的分类学等级名称,可以是学名或俗名。 |
| Crop | Crop variety | 植物的具体品种名称。 |
| Soil | Soil texture | 土壤质地,根据土壤质地分类进行标注。 |
| Soil | Soil reference group | 根据WRB参考土壤组定义的土壤组分类。 |
| Soil | Soil depth | 土壤样本的采集深度。 |
| Soil | Bulk density | 土壤干重除以其体积。 |
| Soil | pH value | 土壤样本中的氢离子浓度。 |
| Soil | Organic carbon | 土壤样本中土壤有机质的可测量成分。 |
| Soil | Available nitrogen | 土壤样本中可供植物利用的氮。 |
| Location | Location name | 与数据集相关的位置名称。 |
| Location | Latitude | 位置的北南向角度坐标。 |
| Location | Longitude | 位置的西东向角度坐标。 |
| Time statement | Start time | 与数据集相关的事件开始时间点。 |
| Time statement | End time | 与数据集相关的事件结束时间点。 |
| Time statement | Duration | 两个时间点之间的范围。 |
预期用途
- 句子级分词格式: 适用于经典的BERT风格NER模型、具有固定长度输入窗口的模型,以及细粒度的句子级训练和评估。
相关资源
- 代码仓库: https://github.com/fairagro/pilot-uc-textmining-metadata
- 引用: bash @dataset{abdelmalak_fairagro_ner_2025, author = {Abdelmalak, Abanoub and Schneider, Gabriel and Riegler, Heike and Meier, Kristin and Specka, Xenia and Svoboda, Nikolai and Husain, Murtuza and Fluck, Juliane}, title = {{FAIRagro NER Dataset: Increasing FAIRness of FAIRagro Data Through AI-Supported Metadata Enrichment}}, year = {2025}, publisher = {Fachrepositorium Lebenswissenschaften (FRL)}, doi = {10.4126/FRL01-6526458}, url = {https://doi.org/10.4126/FRL01-6526458}, note = {Version 1.0} }
作者与所属机构
- Abanoub Abdelmalak (ZB MED – Information Centre for Life Sciences; University of Bonn)
- Gabriel Schneider (ZB MED – Information Centre for Life Sciences; University of Bonn)
- Heike Riegler (Julius Kühn-Institut)
- Kristin Meier (Leibniz Centre for Agricultural Landscape Research (ZALF))
- Xenia Specka (Leibniz Centre for Agricultural Landscape Research (ZALF))
- Nikolai Svoboda (Leibniz Centre for Agricultural Landscape Research (ZALF))
- Murtuza Husain (ZB MED – Information Centre for Life Sciences; University of Bonn)
- Juliane Fluck (ZB MED – Information Centre for Life Sciences; University of Bonn)
搜集汇总
数据集介绍
构建方式
在农业信息学领域,为提升研究数据的可发现性与互操作性,该数据集通过严谨的人工标注流程构建而成。原始文本来源于农业研究数据基础设施中的非结构化元数据,如数据集摘要,经由专业标注人员使用INCEpTION平台进行细粒度实体标注。标注过程严格遵循预定义的实体类别与属性框架,涵盖作物、土壤、地理位置及时间陈述等核心农业实体,并采用BIO标注格式确保序列标注的一致性。标注后的数据通过自动化脚本转换为句子级与文档级两种结构化格式,便于适配不同架构的自然语言处理模型。
特点
本数据集的核心特征在于其针对农业领域命名实体识别任务的专业性与系统性。数据集中详尽定义了四大实体类别——作物、土壤、地理位置与时间陈述,并进一步细分为十余种具体属性,如作物品种、土壤质地、经纬度坐标等,形成了层次化的语义标注体系。数据集以英语和德语双语呈现,语料均源自BonaRes与OpenAgrar等权威农业数据仓储,确保了数据的领域代表性与真实性。其提供的句子级与文档级两种数据格式,分别优化了传统BERT模型与长文档Transformer模型的训练与评估需求,为模型选择提供了灵活性。
使用方法
该数据集旨在服务于农业文本信息抽取与元数据自动化富集的研究与应用。使用者可依据具体任务需求,选择加载句子级或文档级配置的数据分割。对于经典的序列标注模型,句子级格式因其长度适配性,可直接用于训练BERT等基于Transformer的命名实体识别模型。若需处理完整文档上下文或进行文档级统计分析,则可选用文档级格式。数据集中提供的标准化特征列,如Tokens、ner_tags及Labels,可直接与HuggingFace Transformers库等主流框架集成,进行模型微调、评估及部署,从而自动化地从农业研究文本中提取结构化元数据。
背景与挑战
背景概述
在农业科学研究领域,数据资源的可发现性、可访问性、互操作性和可重用性(FAIR原则)是实现数据驱动创新的关键。然而,大量农业研究数据因元数据缺失或不完整而难以有效利用。为应对这一挑战,FAIRagro联盟于2025年发布了“Agriculture_NER_Dataset_for_FAIR_Metadata_Enrichment”数据集。该数据集由ZB MED生命科学信息中心、波恩大学、尤利乌斯·库恩研究所及莱布尼茨农业景观研究中心等机构的研究人员共同构建,旨在通过命名实体识别技术,从非结构化的文本(如数据集摘要)中自动提取作物、土壤、地点和时间等关键实体,从而支持农业研究数据的元数据自动化增强,提升数据的FAIR化水平。
当前挑战
该数据集致力于解决农业科学领域元数据自动化提取的核心挑战,即从复杂多变的农业文本中精准识别细粒度实体。具体而言,挑战体现在实体定义的复杂性上,例如作物名称包含物种学名与俗名,土壤属性涉及质地、参考组、深度及多种化学指标,且文本中常出现缩写、同义词及跨语言表述,这要求模型具备深厚的领域知识。在构建过程中,挑战主要源于高质量标注数据的稀缺性。农业文本专业性强,标注需依赖领域专家进行精细化的手动注释,过程耗时耗力。同时,数据来源于BonaRes和OpenAgrar等多个异构知识库,涉及英语和德语双语种,在实体归一化、格式统一与质量保证方面面临显著困难。
常用场景
经典使用场景
在农业信息学领域,该数据集为命名实体识别任务提供了精准的标注资源。其经典使用场景在于训练和评估自然语言处理模型,以自动从农业研究文献或数据集元数据的非结构化文本中提取关键实体,例如作物品种、土壤属性、地理位置和时间陈述。通过支持句子级和文档级两种标注格式,该数据集能够适配不同架构的模型,如BERT风格的序列标注模型或长文档处理模型,从而在农业文本挖掘中实现高效的实体识别与分类。
解决学术问题
该数据集针对农业科学数据管理中的核心挑战,即如何提升数据的可发现性、可访问性、互操作性和可重用性。通过提供高质量的人工标注语料,它解决了农业领域缺乏专用命名实体识别基准的问题,使得研究人员能够开发针对性的信息抽取模型。这些模型能够自动化地丰富元数据,从而促进农业研究数据的FAIR原则实践,为跨学科数据整合与知识发现奠定基础。
衍生相关工作
围绕该数据集,已衍生出多项经典研究工作,主要集中在农业领域自适应预训练语言模型的微调、多语言命名实体识别模型的构建,以及结合地理空间信息的元数据增强管道开发。相关代码库公开了完整的预处理与模型训练流程,为后续研究提供了可复现的基准。这些工作不仅验证了数据集的有效性,也推动了农业自然语言处理技术向更专业化、实用化的方向发展。
以上内容由遇见数据集搜集并总结生成


